标签:des style blog http color 使用 os io
过程如下:
将数据从一台计算机通过一定的路径发送到另一台计算机。应用层数据通过协议栈发到网络上时,每层协议都要加上一个数据首部(header),称为封装(Encapsulation),如下图所示:
不同的协议层对数据包有不同的称谓,在传输层叫做段(segment),在网络层叫做数据包(packet),在链路层叫做帧(frame)。数据封装成帧后发到传输介质上,到达目的主机后每层协议再剥掉相应的首部,最后将应用层数据交给应用程序处理。
上图对应两台计算机在同一网段中的情况,如果两台计算机在不同的网段中,那么数据从一台计算机到另一台计算机传输过程中要经过一个或多个路由器,如下图所示:
其实在链路层之下还有物理层,指的是电信号的传递方式,比如现在以太网通用的网线(双绞线)、早期以太网采用的的同轴电缆(现在主要用于有线电视)、光纤等都属于物理层的概念。物理层的能力决定了最大传输速率、传输距离、抗干扰性等。集线器(Hub)是工作在物理层的网络设备,用于双绞线的连接和信号中继(将已衰减的信号再次放大使之传得更远)。
链路层有以太网、令牌环网等标准,链路层负责网卡设备的驱动、帧同步(就是说从网线上检测到什么信号算作新帧的开始)、冲突检测(如果检测到冲突就自动重发)、数据差错校验等工作。交换机是工作在链路层的网络设备,可以在不同的链路层网络之间转发数据帧(比如十兆以太网和百兆以太网之间、以太网和令牌环网之间),由于不同链路层的帧格式不同,交换机要将进来的数据包拆掉链路层首部重新封装之后再转发。
网络层的IP协议是构成Internet的基础。Internet上的主机通过IP地址来标识,Internet上有大量路由器负责根据IP地址选择合适的路径转发数据包,数据包从Internet上的源主机到目的主机往往要经过十多个路由器。路由器是工作在第三层的网络设备,同时兼有交换机的功能,可以在不同的链路层接口之间转发数据包,因此路由器需要将进来的数据包拆掉网络层和链路层两层首部并重新封装。IP协议不保证传输的可靠性,数据包在传输过程中可能丢失,可靠性可以在上层协议或应用程序中提供支持。
网络层负责点到点(point-to-point)的传输(这里的“点”指主机或路由器),而传输层负责端到端(end-to-end)的传输(这里的“端”指源主机和目的主机)。传输层可选择TCP或UDP协议。TCP是一种面向连接的、可靠的协议,有点像打电话,双方拿起电话互通身份之后就建立了连接,然后说话就行了,这边说的话那边保证听得到,并且是按说话的顺序听到的,说完话挂机断开连接。也就是说TCP传输的双方需要首先建立连接,之后由TCP协议保证数据收发的可靠性,丢失的数据包自动重发,上层应用程序收到的总是可靠的数据流,通讯之后关闭连接。UDP协议不面向连接,也不保证可靠性,有点像寄信,写好信放到邮筒里,既不能保证信件在邮递过程中不会丢失,也不能保证信件是按顺序寄到目的地的。使用UDP协议的应用程序需要自己完成丢包重发、消息排序等工作。
拆包的协议
目的主机收到数据包后,如何经过各层协议栈最后到达应用程序呢?整个过程如下图所示:
以太网驱动程序首先根据以太网首部中的“上层协议”字段确定该数据帧的有效载荷(payload,指除去协议首部之外实际传输的数据)是IP、ARP还是RARP协议的数据报,然后交给相应的协议处理。假如是IP数据报,IP协议再根据IP首部中的“上层协议”字段确定该数据报的有效载荷是TCP、UDP、ICMP还是IGMP,然后交给相应的协议处理。假如是TCP段或UDP段,TCP或UDP协议再根据TCP首部或UDP首部的“端口号”字段确定应该将应用层数据交给哪个用户进程。IP地址是标识网络中不同主机的地址,而端口号就是同一台主机上标识不同进程的地址,IP地址和端口号合起来标识网络中唯一的进程。
注意,虽然IP、ARP和RARP数据报都需要以太网驱动程序来封装成帧,但是从功能上划分,ARP和RARP属于链路层,IP属于网络层。虽然ICMP、IGMP、TCP、UDP的数据都需要IP协议来封装成数据报,但是从功能上划分,ICMP、IGMP与IP同属于网络层,TCP和UDP属于传输层。
以太网链路层数据帧格式:
IP数据包头:
IP数据报格式如下:
注:需要注意的是网络数据包以大端字节序传输,当然头部也得是大端字节序,也就是说:
The most significant bit is numbered 0 at the left, and the least significant bit of a 32-bit value is numbered 31 on the right.
The 4 bytes in the 32-bit value are transmitted in the order: bits 0-7 first, then bits 8-15, then 16-23, and bits 24-31 last. This is called big endian byte ordering, which is the byte ordering required for all binary
integers in the TCP/IP headers as they traverse a network. This is called the network byte order. Machines that store binary integers in other formats, such as the
little endian format, must convert the header values into the network byte order before transmitting the data.
IP数据包头数据结构如下:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix <asm/byteorder.h>"
#endif
__u8 tos;
__u16 tot_len;
__u16 id;
__u16 frag_off;
__u8 ttl;
__u8 protocol;
__u16 check;
__u32 saddr;
__u32 daddr;
/*The options start here. */
};版本
IP协议版本号,长度为4位,IPv4此字段值为4,IPv6此字段值为6
首部长度
以32位的字为单位,该字段长度为4位,最小值为5,即不带任何选项的IP首部20个字节;最大值为15,所以首部长度最大为60个字节
服务类型(TOS)
长度为8位。此字段包含3位的优先权(现已忽略),4位的服务类型子字段(只能有一位置1)和1位的保留位(必须置0)。4位的服务类型分别为最小延迟(D)、最大吞吐量(T)、最高可靠性(R)、最小费用(F),如下图。
总长度
该字段长度为16位,以字节为单位,该字段长度包含IP的头部和数据部分(payload)。IP数据报最大可达65535个字节。
The total length field is required in the IP header since some data links (e.g., Ethernet) pad small frames to be a minimum length.
when a datagram is fragmented the total length field of each fragment is changed to be the size of that fragment.
标识
16位标识,用来标识一个IP数据报,每发送一个此值会加1,可用于分片和重新组装成数据报。
标志与片偏移
3位标志其中第一位不使用, 每二位DF(Don’t Fragment),该位如果为1,如果传输的数据报超过最大传输单元,该数据报会被丢弃,并发送一个ICMP差错报文。第三位MF(More Fragment)表示是否有更多的片,该位为1,说明后续有分片。最后一片MF为0。
注:在这里稍微讲一下IP层分片的问题。假设一个IP数据报大于最大传输单元MTU,那么如果设置了分片标志位,将会被分片传输。
每一片都有自己的IP 头部,IP头部中的标识是一样的,但是片偏移不同(以8字节为单位)。除了最后一片,分片要求其他片除去IP头部的大小必须是8字节的整数倍。除了第一片有tcp/udp头部,其他片都没有。分片完成后,每一片独自成为一个数据包(跟数据报概念不同,参见这里),可以走不同的路由,最后到达目的地的时候IP层根据它们各自IP头部的信息重新组成一个IP数据报。
分片是有风险的,因为一旦某一片丢失,就需要重传这个IP数据报,因为IP层本身并没有超时重传的机制,可靠性需要TCP层来保证(一些UDP协议的可靠性由应用程序保证),一旦一个TCP段中的某一片丢失,TCP协议层会超时重传。此外,分片可以发生在源主机或者中间的路由,如果发生在中间的路由,源主机根本不知道是怎样分片,所以要尽量避免分片。
应用数据的多个IP数据报由TCP层根据seq number 进行重组成原始数据,存放到TCP接收缓冲区。
Using sequence numbers, a receiving TCP discards duplicate segments and reorders segments that arrive out of order. Recall that any of these anomalies can happen because TCP uses IP to
deliver its segments, and IP does not provide duplicate elimination or guarantee correct ordering. Because it is a byte stream protocol, however, TCP never delivers data to the receiving application out of order. Thus, the receiving TCP may be forced to hold
on to data with larger sequence numbers before giving it to an application until a missing lower-sequence-numbered segment (a “hole”) is filled in.
TTL
TTL(Time To Live)表示数据报最多可经过的路由器的数量。数据报每经过一个路由器,TTL减1,减为0时丢弃,并发送ICMP报文通知源主机。TTL可以避免数据报在路由器之间不断循环。
协议类型
表示IP层上承载的是哪个高级协议。在封装与分用的过程中,协议栈知道该交给哪个层的协议处理。1 ICMP 2 IGMP 6 TCP 17UDP
头部校验和
保证数据报头部的数据完整性,但校验不包括数据部分。这样做的目的有二:一是所有将数据封装在IP数据包中的高层协议均含有覆盖整个数据的校验和,因此IP数据报没有必要再对其所承载的数据部分进行校验。二是每经过一个路由器,IP数据报的头部要发生改变(如TTL),而数据部分不变,这样只对发生改变的头部进行校验,显然不会浪费太多的时间。为了减少计算时间,一般不用CRC校验码,而是采用更简单的网际校验和(Internet
Checksum)。
Since a router often changes only the TTL field (decrementing it by 1), a router can incrementally update the checksum when it forwards a received datagram, instead of calculating the checksum over the entire IP header again.
The standard BSD implementation, however, does not use this incremental update feature when forwarding a datagram.
源IP地址
发送数据的主机IP地址
目的IP地址
接收数据的主机IP地址
选项与填充(选项为4字节整数倍,否则用0填充)
安全和处理限制
路径记录:记录所经历路由器的IP地址
时间戳:记录所经历路由器的IP地址和时间
宽松源站路由:指定数据报文必须经历的IP地址,可以经过没有指定的IP地址。
严格的源站路由:指定数据报文必须经历的IP地址,不能经过没有指定的IP地址。
二、IP地址与路由
IPv4的IP地址长度为4字节,通常采用点分十进制表示法(dotted decimal representation)例如0xc0a80002表示为192.168.0.2。Internet被各种路由器和网关设备分隔成很多网段,为了标识不同的网段,需要把32位的IP地址划分成网络号和主机号两部分,网络号相同的各主机位于同一网段,相互间可以直接通信,网络号不同的主机之间通信则需要通过路由器转发。
In our general scheme, IP can receive a datagram from TCP, UDP, ICMP, or IGMP (that is, a locally generated datagram) to send, or one that has been received from a network interface (a datagram to forward). The IP layer has a routing table in memory that
it searches each time it receives a datagram to send. When a datagram is received from a network interface, IP first checks if the destination IP address is one of its own IP addresses or an IP broadcast address. If so, the datagram is delivered to the protocol
module specified by the protocol field in the IP header. If the datagram is not destined for this IP layer, then (1) if the IP layer was configured to act as a router the packet is forwarded (that is, handled as an outgoing datagram as described below), else
(2) the datagram is silently discarded.
假设某主机上的网络接口配置和路由表如下:
这台主机只有一个网络接口连到192.168.232.0/24网络。路由表的Destination是目的网络地址,Genmask是子网掩码,Gateway是下一跳地址,Iface是发送接口,Flags中的U标志表示此条目有效(可以禁用某些条目),G标志表示此条目的下一跳地址是某个路由器的地址,没有G标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发,因此下一跳地址处记为*号。
如果要发送的数据包的目的地址是192.168.232.1,跟第三行的子网掩码做与运算得到192.168.232.0,正是第三行的目的网络地址,因此从eth0接口发送出去,由于192.168.232.0/24正是与eth0接口直接相连的网络,因此可以直接发到目的主机,不需要经路由器转发。
如果要发送的数据包的目的地址是202.10.1.2,跟后两行路由表条目都不匹配,那么就要按缺省路由条目,从eth0接口发出去,首先发往192.168.232.2 路由器,再让路由器根据它的路由表决定下一跳地址。
A complete matching host address is searched for before a matching network ID. Only if both of these fail is a default route used.
路由的处理过程如下,ARP部分可以参考这里:
TCP 数据包头
TCP数据包结构:
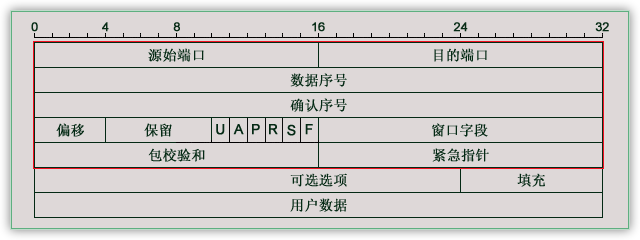
数据结构如下:
struct tcphdr {
__be16 source; // <span style="font-family:SimSun;">源端口号</span>
__be16 dest; // 目的端口号
__be32 seq; // 封装序号
__be32 ack_seq; <span style="font-family:SimSun;">// ACK序号</span>
#if defined(__LITTLE_ENDIAN_BITFIELD) // 小端时
__u16 res1:4,
doff:4,
fin:1, // 传输结束
syn:1, <span style="font-family:SimSun;">// 建立同步</span>
rst:1, // 对端复位
psh:1, // 尽快传递给应用程序
ack:1, <span style="font-family:SimSun;">// 确认数据包</span>
urg:1, // 紧急数据包
ece:1,
cwr:1;
#elif defined(__BIG_ENDIAN_BITFIELD) <span style="font-family:SimSun;">// 大端时</span>
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window; //<span style="font-family:SimSun;"> 滑动端口大小</span>
__sum16 check; // 检验码
__be16 urg_ptr; // 紧急信息
};1-1.源始端口16位,范围当然是0-65535啦。
1-2.目的端口,同上。
2-1.数据序号32位,TCP为发送的每个字节都编一个号码,这里存储当前数据包数据第一个字节的序号。
3-1.确认序号32位,为了安全,TCP告诉接受者希望他下次接到数据包的第一个字节的序号。
4-1.偏移4位,类似IP,表明数据距包头有多少个32位。
4-2.保留6位,未使用,应置零。
4-3.紧急比特URG—当URG=1时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。
4-3.确认比特ACK—只有当ACK=1时确认号字段才有效。当ACK=0时,确认号无效。参考TCP三次握手
4-4.复位比特RST(Reset) —当RST=1时,表明TCP连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新
建立运输连接。参考TCP三次握手
4-5.同步比特SYN—同步比特SYN置为1,就表示这是一个连接请求或连接接受报文。参考TCP三次握手
4-6.终止比特FIN(FINal)—用来释放一个连接。当FIN=1时,表明此报文段的发送端的数据已发送完毕,并要求释放运输连接。
4-7.窗口字段16位,窗口字段用来控制对方发送的数据量,单位为字节。TCP连接的一端根据设置的缓存空间大小确定自己的接收窗口
大小,然后通知对方以确定对方的发送窗口的上限。
5-1.包校验和16位,包括首部和数据这两部分。在计算检验和时,要在TCP报文段的前面加上12字节的伪首部。
5-2.紧急指针16位,紧急指针指出在本报文段中的紧急数据的最后一个字节的序号。
6-1.可选选项24位,类似IP,是可选选项。
6-2.填充8位,使选项凑足32位。
7-1.用户数据……
可以看出,每个IP包至少要20字节的头部长度,这些与下载内容无关,加上目前多数传输,包括http协议(就是IE直接下载),都是基于
TCP协议的,所以IP包裹还要从用户数据中扣除20字节的TCP包头,这里已经是40字节,加上其他程序的连接,状态确认等等包裹,因
而算出来要比理论值要小。
UDP数据包头
UDP协议(User Datagram Protocol)是传输层协议,为应用层提供服务,RFC768中有基本的UDP描述。UDP的长度是8字节,其数据包头的结构如图所示。UDP数据包是包含在一个IP数据报文中的。

UDP协议是面向非连接的,任何一方创建好后,都可以向对方发送数据包,甚至可以在对方未开机或不存在的情况下,一方仍然可以成功地发送数据包.
什么是大端和小端
Big-Endian和Little-Endian的定义如下:
1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
2) Big-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
举一个例子,比如数字0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
3)下面是两个具体例子:
16bit宽的数0x1234在Little-endian模式(以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
|
内存地址 |
小端模式存放内容 |
大端模式存放内容 |
|
0x4000 |
0x34 |
0x12 |
|
0x4001 |
0x12 |
0x34 |
32bit宽的数0x12345678在Little-endian模式以及Big-endian模式)CPU内存中的存放方式(假设从地址0x4000开始存放)为:
|
内存地址 |
小端模式存放内容 |
大端模式存放内容 |
|
0x4000 |
0x78 |
0x12 |
|
0x4001 |
0x56 |
0x34 |
|
0x4002 |
0x34 |
0x56 |
|
0x4003 |
0x12 |
0x78 |
4)大端小端没有谁优谁劣,各自优势便是对方劣势:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
数组在大端小端情况下的存储:
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value:
Big-Endian: 低地址存放高位,如下:
高地址
---------------
buf[3] (0x78) -- 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) -- 高位
---------------
低地址
Little-Endian: 低地址存放低位,如下:
高地址
---------------
buf[3] (0x12) -- 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) -- 低位
--------------
低地址
为什么会有大小端模式之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,网络字节顺序采用大端模式,
如何检测大小端:
联合体union的存放顺序是所有成员都从低地址开始存放,利用该特性可以轻松地获得了CPU对内存采用Little-endian还是Big-endian模式读写:
#include <stdio.h>
#include <stdlib.h>
union word
{
int a;
char b;
} c;
int checkCPU(void)
{
c.a = 1;
printf("c.b=%d\n",c.b);
return (c.b==1);
}
int main(void)
{
int i;
i= checkCPU();
if(i==0)
printf("this is Big_endian\n");
else if(i==1)
printf("this is Little_endian\n");
return 0;
}字节顺序转换函数
既然网络上传输的数据以及各种类型的主机字节顺序有差异,因此X86平台下编译网络程序的时候,要注意大小端转换.比如在绑定socket和ip地址的时候之一使用网络顺序.
tonl()
htons()
ntohl()
ntohs()
函数可以实现字节顺序与主机字节顺序转换.
具体函数的使用使用的搜搜用法就好了.
Linux程序设计学习笔记----网络编程之网络数据包拆封包与字节顺序大小端,布布扣,bubuko.com
Linux程序设计学习笔记----网络编程之网络数据包拆封包与字节顺序大小端
标签:des style blog http color 使用 os io
原文地址:http://blog.csdn.net/suool/article/details/38636993









