标签:使用 没有 [] .so bool hashset table list 为什么
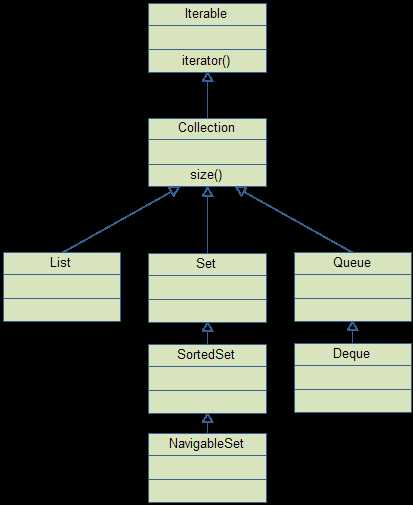
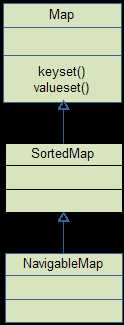
在 java.util 包中, 其中 Collection 包含:
注意: Map 不在 Collection 集合中.
Collection的主要方法
Boolean add(Object): 如果没添加, 则返回 false(Set 常用)Boolean addAll(Collection)void clear(): 清除所有Boolean contains(Object): 包含(通过比较equals)则返回trueBoolean containsAll(Collection): 如果包含所有, 则返回trueBoolean isEmpty(): 没有元素返回trueIterator iterator(): 返回迭代器, Collection 唯一的迭代方法Boolean remove(Object): true 代表有删除动作Boolean removeAll(Collection): true 代表有删除动作Boolean retainAll(Collection): 取交集, 有变动返回 trueint size()Object[] toArray(): 返回一个数组Object[] toArray(Object[] a)1.8新特性
Spliterator<E> spliterator()Stream<E> stream()Stream<E> parallelStream()List接口 继承自 Collection 接口, 它保证元素保存的顺序. 实现类主要有:
ArrayListLinkedListArrayList特点:
Vector扩容:
oldCapacity + (oldCapacity >> 1) + 1LinkedList特点:
Set接口 继承自 Collection 接口, 它保证容器内元素唯一性, 不保证顺序. Set 中添加的对象, 必须重写了 equals() 方法(否则只是比较地址), 实现类有:
HashSetTreeSet特点:
hashcodeHashMap 实现, 每次add操作会调用 map.put(ele, 预定义假对象);特点:
TreeMap 实现, 每次add操作会调用 map.put(ele, 预定义假对象);用于存储 "键值对".包含:
特点:
HashtablehashCode() 和 equals()put() 和 get() 为常数时间扩容:
与Hashtable区别:
<null, null>影响HashMap性能的参数:
初始大小和负载因子, 当(键值对数 > 总槽数 * 负载因子), 就会进行 rehash().
如何有效地减少rehash 操作, 以提高HashMap性能? 1. 在设置初始大小的时候, 要考虑实际要存储多少元素, 以及增长因子(什么时候扩容), 这样的话, 就可以减少 rehash 的次数. 2. 当有特别多元素要存储的时候, 初始值要考虑设置的大一点. 这比每次扩容改变大小效率高很多.
特点: 1. 在 红-黑 树的基础上实现. 2. key 不能为 null, 和 HashMap不同 3. 有 subMap() 方法, 可以返回树的一部分. 4. put() 和 get() 时间复杂度为 log(N) 5. 需要重写 equals() 6. 查询比 HashMap 快
TreeMap 是怎样排序的?
Comparator接口的实现Object 实现了 Comparable 接口__Comparator 和 Comparable 有什么区别? Comparator是外部比较器, 其比较方法compare(T o1, T o2)有两个参数Comparable 是内部比较器, 起比较方法compareTo(T o) 只有一个参数
Arrays.sort(a, new Comparator(){...})Comparable 可以调用 Arrays.sort(a)Arrays.binarySearch()Object[] a = list.toArray()Arrays.sort(a, new Comparator(){...}), 假如 Object 实现了 Comparable 可以调用 Arrays.sort(a)void sort(Comparator c) 方法Collections.sort(List l)方法Collections.binarySearch(List, Object)
Object[] a = list.toArray()Arrays.sort(a, new Comparator(){...}), 假如 Object 实现了 Comparable 可以调用 Arrays.sort(a)HashSet 转化成 TreeSetHashMap 转化成 TreeMapenumeration(Collection)max(Collection)min(Collection)max(Collection, Comparator)min(Collection, Comparator)nCopies(int n, Object o): 返回一个不可边的List, 列表内的元素都指向 ounmodifiedbleCollection(Collection): 返回一个不可边的 CollectionsynchronizedList(List)synchronizedSet(Set)synchronizedMap(Map)Enumeration和Iterator接口的区别?
Enumeration的速度是Iterator的两倍,也使用更少的内存。Enumeration是非常基础的,也满足了基础的需要。但是,与Enumeration相比,Iterator更加安全,因为当一个集合正在被遍历的时候,它会阻止其它线程去修改集合。
迭代器取代了Java集合框架中的Enumeration。迭代器允许调用者从集合中移除元素,而Enumeration不能做到。为了使它的功能更加清晰,迭代器方法名已经经过改善。
优点: 可以容纳基本数据类型 缺点: 提前分配空间
特点:
List 接口synchronized 标识, 有显著的性能开销扩容:
特点:
Vector扩容, 同 Vector
特点:
Map 接口key-value 对Entry<K,V>(实现Map.Entry<K,V>接口) 数组 + 外部拉链法synchronized 保证扩容:
rehash() 都会扩容rehash 条件: count >= threshold, threshold值为: 当前大小 * 负载因子newCapacity = (oldCapacity << 1) + 1MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8最大值-8)默认的 hashcode 是多少?
hashcode默认值是由 Object的hashcode生成的, 值是这个对象的地址.
为什么要存到 HashMap/HashList/Hashtable 中的对象要重写 equals 和 hashcode?
hashcode 默认值是对象的地址, 假如一个对象在 Hashtable 中, 拿另外一个相等的对象查找, 会无法在 Hashtable 中检索到, 因为两个对象地址不同, 所以检索到的 enties[index] 不同.
之所以要重写 equals, 是因为虽然通过 hashcode 可以找到正确的 entries[index], 但是在链表中找相等元素, 是比较 equals 方法.
标签:使用 没有 [] .so bool hashset table list 为什么
原文地址:http://www.cnblogs.com/pragmatic/p/6143008.html