标签:oop ns2 tom primary tar images oat load one
sqoop:sqoop-1.4.5+cdh5.3.6+78,
hive:hive-0.13.1+cdh5.3.6+397,
hbase:hbase-0.98.6+cdh5.3.6+115
Sqoop
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的开源工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
不想用程序语言开发MapReduce的朋友比如DB们,熟悉SQL的朋友可以使用Hive开离线的进行数据处理与分析工作。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。注意Hive现在适合在离线下进行数据的操作,就是说不适合在挂在真实的生产环境中进行实时的在线查询或操作,因为一个字“慢”。
Hive起源于FaceBook,在Hadoop中扮演数据仓库的角色。建立在Hadoop集群的最顶层,对存储在Hadoop群上的数据提供类SQL的接口进行操作。你可以用 HiveQL进行select、join,等等操作。如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReduce jobs就可以用Hive代替。
Hive的内置数据类型可以分为两大类:
(1)、基础数据类型;
(2)、复杂数据类型。
其中,基础数据类型包括:TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE、STRING、BINARY、TIMESTAMP、DECIMAL、CHAR、VARCHAR、DATE。
下面的表格列出这些基础类型所占的字节以及从什么版本开始支持这些类型。
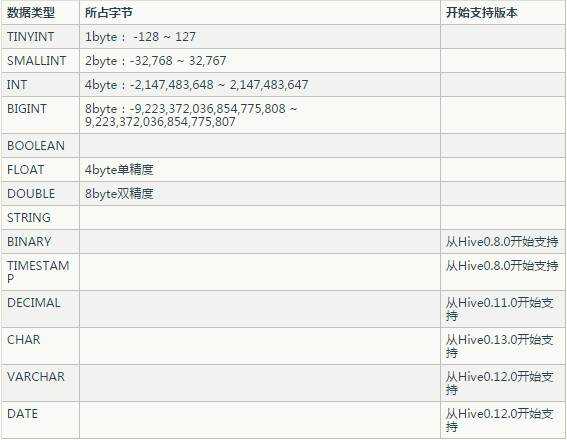
复杂类型包括ARRAY、MAP、STRUCT、UNION,这些复杂类型是由基础类型组成的。
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现。HBase以Google BigTable为蓝本,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。如果你需要实时访问一些数据,就把它存入HBase。
你可以用Hive作为静态数据仓库,HBase作为数据存储,放那些进行一些会改变的数据。在Hive中,普通表是存储在HDFS中,而你可以通过创建EXTERNAL TABLE外表来指定数据存储位置,可以是系统目录,也可以是ElasticSearch,还可以是HBase。
在使用Sqoop从Mysql导出数据入Hadoop时,就需要考虑是直接入Hive(此时是普通表),还是导入数据到HBase,Sqoop同时支持导入这两种导入。
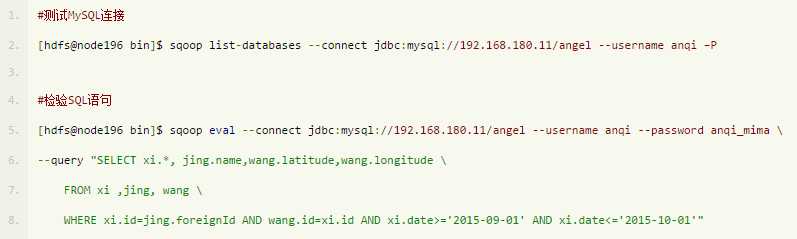
以上Sqoop语句执行过后,可以确认Sqoop运行正常,Sqoop连接MySQL正常。
使用复杂SQL
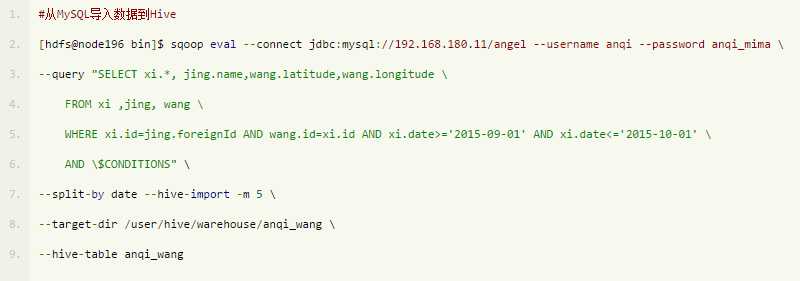
注意:
由于使用Sqoop从MySQL导入数据到Hive需要指定target-dir,因此导入的是普通表而不能为外部表。
以下简要列举了Sqoop的执行过程:

可以看出,--split-by设置后,job按设置值切分,切分个数为-m设置值(-m 5 不设置的话默认job切分数是4)。经检验,此种较复杂的SQL语句,Sqoop支持得很好。
上面任务执行成功后,经过检测,发现Hive表结构中的数据类型与MySQL对应列有如下关系:

可以看出MySQL的decimal类型变成了Hive中的double类型。此时需要在导入时通过--map-column-hive 作出映射关系指定,如下所示:
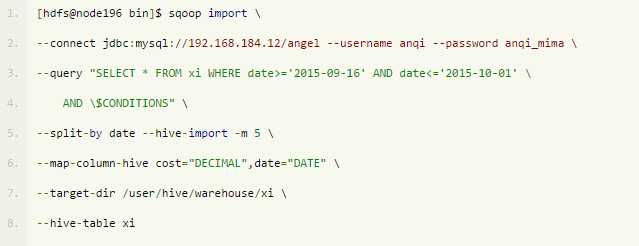
以上命令可以执行成功,然而Hive列类型设置为DECIMAL时,从Mysql[decimal(12,2)]-->Hive[decimal]会导致导入后小数丢失。
注意:
对于cost="DECIMAL(10,2)"这样指定精确度的映射语句的执行,在Sqoop1.4.5中执行失败。这是Sqoop1.4.5的一个BUG,详情见:https://issues.apache.org/jira/browse/SQOOP-2103,它在1.4.7版本中修复。
不断更新
将上面Sqoop语句执行两次,在执行第二次时会出现错误:

这表示HDFS中已经存在相应存储,此时需要执行Sqoop-Hive的增量导入语句。
注意:
由于Hive没有rowkey,其hdfs存储决定了Sqoop-Hive只能添加,update更新导入无法进行。
使用复杂SQL
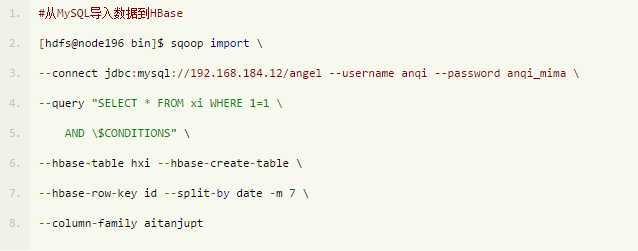
上面SQL语句较简单。经检验,更复杂的SQL语句,Sqoop支持得很好,导入正常。
不断更新
以上指定了HBase的Rowkey后,再次执行从MySQL导入数据到HBase的Sqoop语句,基于相同的Rowkey值,HBase内相应的行会进行更新替换。

关于Hive使用存储在HBase中的数据,更多详细信息可以查看《使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作》一文。
架构上,Sqoop1使用MapOnly作业进行Hadoop(HDFS/HBase/Hive)同关系数据库进行数据的导入导出,用户使用命令行方式与之交互,数据传输和数据格式紧密耦合;易用性欠佳,Connector数据格式支持有限,安全性不好,对Connector的限制过死。Sqoop2则建立了集中化的服务,负责管理完整的MapReduce作业,提供多种用户交互方式(CLI/WebUI/RESTAPI),具有权限管理机制,具有规范化的Connector,使得它更加易用,更加安全,更加专注。
综上所述
使用Sqoop从MySQL导入数据到HBase要比导入到Hive方便,使用Hive对HBase数据操作时,也无decimal精度相关BUG,并且可以很好的支持更新。因此建议使用Sqoop从MySQL导入数据到HBase,而非直接Hive。
经过测试,使用Sqoop从MySQL导入数据到HBase,100万条需花费7~12分钟。impala对于hbase的查询效率也没有对hdfs效率高。
在大数据领域浸染的多了,才知道当前社会上的公司对于大数据方向的技术都是什么样的理解。有的公司数据量足够大,但数据并无价值或者价值不够大,我们称之为LU(large but unavailable)类型公司;有的公司数据量不多,但都价值连城,我们称之为SV(small but valuable)类型公司;有的公司数据量很大,数据也都很有价值,我们称之为LV(large and valuable)类型公司。
LU公司市场上有很多,造成数据无价值的因素可能是有数据本身的原因,也有产品的原因,他们也经常想要在当前环境下试下大数据的水,这便要细心甄别。SV公司也有不少,对于他们而言,好的数据分析师比大数据平台更重要,欲要试水大数据,还是要对数据量有清晰的预估。LV公司是最需要搭建大数据平台的,但又往往他们没有技术与欲望去做这件事,这也比较可恨。
简而言之,想做的不一定需要,不做的不一定不需要。
End.
教程 | 使用Sqoop从MySQL导入数据到Hive和HBase
标签:oop ns2 tom primary tar images oat load one
原文地址:http://www.cnblogs.com/sanyuanempire/p/6163803.html


