标签:pre ase 开头 re模块 通过 src 匹配 img 引擎
四、正则、
课前引入:
例子一、
s=‘dsdsadsadadsalexdsds‘
s.find(‘alex‘)
如何找到字符串内部的alex;?过去学习可使用方法:find、split、replace.但是字符串内置的方法很局限,只能实现完全匹配。
如果要找到:与a**开头的需求呢?就无法实现。要实现模糊匹配就得用到模糊匹配。
例子二、模糊匹配
#在文本里面存着一堆身份证 4504231989347382822 1104231989347382822 1104231992347382822 1104231995347382822 ..... #需求:找到北京市1990以后出身的人
^110......1990+*
找到一堆字符串里面的数字:
正则本质上是一种小型的,高度专业化的编程语言。(python)中内嵌在python中,并通过re模块来实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配:(普通字符、元字符)
普通字符:大多数字符和字母都会和自身匹配
import re print(re.findall(‘alex‘,‘dsfjdsfldsjfdalexdsds‘)) >>> [‘alex‘]
元字符:. ^ $ * + ?{} [] | () \
字符讲解:
1??通配符 ‘.’
import re print(re.findall(‘a..x‘,‘dsfjdsfldsjfdalexdsds‘)) >>> [‘alex‘]
2??、尖角号:^ 以什么开头。在字符串的开头进行匹配。如果符合要求匹配成功。
import re print(re.findall(‘^d..j‘,‘dsfjdsfldsjfdalexdsds‘)) >>> [‘dsfj‘]
3??、$ 符号 以什么结尾,
import re print(re.findall(‘d..s$‘,‘dsfjdsfldsjfdalexdsds‘)) >>>> [‘dsds‘]
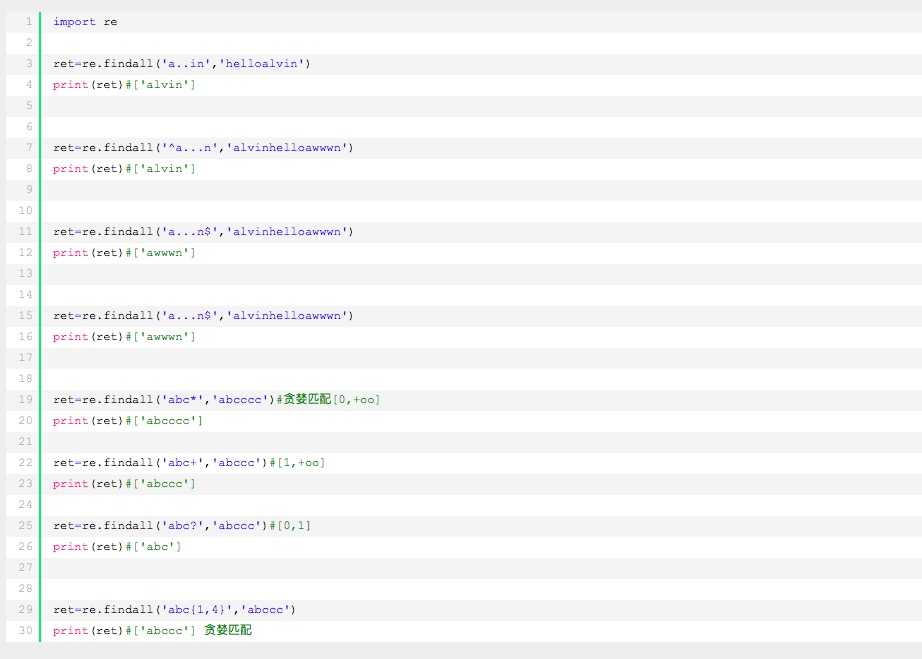
重复符号:
4??、* (0,∞) D*按照紧挨着的字符进行无穷次→贪婪匹配,
import re print(re.findall(‘d*‘,‘dsfjdsflddddddddddsjfdalexdsds‘)) >>> [‘d‘, ‘‘, ‘‘, ‘‘, ‘d‘, ‘‘, ‘‘, ‘‘, ‘dddddddddd‘, ‘‘, ‘‘, ‘‘, ‘d‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘d‘, ‘‘, ‘d‘, ‘‘, ‘‘]
import re print(re.findall(‘^d*‘,‘dsfjdsflddddddddddsjfdalexdsds‘)) >> [‘d‘]
???、+ 匹配[1,∞)最少匹配一个字符尾部加一个?号就变成惰性匹配
import re print(re.findall(‘alex*‘,‘dsfjdsfalesjfdsds‘)) import re print(re.findall(‘alex+‘,‘dsfjdsflalesjfdsds‘)) >>> [‘ale‘] []
6??、?[0,1]
import re print(re.findall(‘alex?‘,‘dsfjdsflalexxxsjfdsds‘)) >>> [‘alex‘]
7??、{} 范围自己定{0,}=*:0到无穷次、{1,}=+:【1,+00】、{0,1}=?、{6}重复6次
import re print(re.findall(‘alex{6}‘,‘dsfjdsflalexxxsjfdsds‘)) >>> []
补充:加入:?就变成 惰性匹配,按照最小的来查找匹配。
import re print(re.findall(‘alex+?‘,‘dsfjdsflalexxxsjfdsds‘)) import re print(re.findall(‘alex*?‘,‘dsfjdsflalexxxsjfdsds‘)) >>>> [‘alex‘] [‘ale‘]
8??、[]:字符集..任何符号放置在里面都是普通的符号,匹配里面的其中一个
除了
【a-z】范围,a到z
import re print(re.findall(‘x[a-z]*‘,‘xypsssdsdsdsdssxzp‘)) >>> [‘xypsssdsdsdsdssxzp‘]
【^a-z】意义:非 匹配非a到z的字母
import re print(re.findall(‘www.[oldboy baidu]‘,‘www.baid‘)) import re print(re.findall(‘x[yz]‘,‘xyssssxz‘)) import re print(re.findall(‘x[yz]p‘,‘xypssssxzp‘)) >>> [‘www.b‘] [‘xy‘, ‘xz‘] [‘xyp‘, ‘xzp‘]
9??、
day、模块-basedir、os、json模块、pickle和正则模块。
标签:pre ase 开头 re模块 通过 src 匹配 img 引擎
原文地址:http://www.cnblogs.com/laixiaoyun/p/6174273.html