标签:菜谱 循环 时间复杂度 冒泡排序 第一个 区别 复杂度 相加 依赖
1、什么是算法
算法(algorithm):就是定义良好的计算过程,他取一个或一组的值为输入,并产生出一个或一组值作为输出。简单来说算法就是一系列的计算步骤,用来将输入数据转化成输出结果。
mark:我们可以把所有的算法想象为一本“菜谱”,特定的算法比如菜谱中的的一道“老醋花生米”的制作流程,只要按照菜谱的要求制作老醋花生米,那么谁都可以做出一道好吃的老醋花生米。so,这个做菜的步骤就可以理解为:“解决问题的步骤”
2、算法的意义
假设计算机无限快,并且计算机存储容器是免费的,我们还需要各种乱七八糟的算法吗?如果计算机无限快,那么对于某一个问题来说,任何一个都可以解决他的正确方法都可以的!
当然,计算机可以做到很快,但是不能做到无限快,存储也可以很便宜但是不能做到免费。
那么问题就来了效率:解决同一个问题的各种不同算法的效率常常相差非常大,这种效率上的差距的影响往往比硬件和软件方面的差距还要大。
3、如何选择算法
第一首先要保证算法的正确性
一个算法对其每一个输入的实例,都能输出正确的结果并停止,则称它是正确的,我们说一个正确的算法解决了给定的计算问题。不正确的算法对于某些输入来说,可能根本不会停止,或者停止时给出的不是预期的结果。然而,与人们对不正确算法的看法想反,如果这些算法的错误率可以得到控制的话,它们有时候也是有用的。但是一般而言,我们还是仅关注正确的算法!
第二分析算法的时间复杂度
算法的时间复杂度反映了程序执行时间随输入规模增长而增长的量级,在很大程度上能很好反映出算法的好坏。
1、什么是时间复杂度
一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
2、时间复杂度的计算方法
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试因为该方法有两个缺陷:
所以只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。
一般情况下,算法的基本操作重复执行的次数是模块n的某一个函数f(n),因此,算法的时间复杂度记做:T(n)=O(f(n))。随着模块n的增大,算法执行的时间的增长率和f(n)的增长率成正比,所以f(n)越小,算法的时间复杂度越低,算法的效率越高。
在计算时间复杂度的时候,先找出算法的基本操作,然后根据相应的各语句确定它的执行次数,再找出T(n)的同数量级(它的同数量级有以下:1,Log2n ,n ,nLog2n ,n的平方,n的三次方,2的n次方,n!),找出后,f(n)=该数量级,若T(n)/f(n)求极限可得到一常数c,则时间复杂度T(n)=O(f(n))。
3、常见的时间复杂度
常见的算法时间复杂度由小到大依次为:
Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)
求解算法的时间复杂度的具体步骤:
如果算法中包含镶套的循环,则基本语句通常是最内层的循环体,如果算法中包并列的循环,则将并列的循环时间复杂度相加,例如:
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = ‘luotianshuai‘ n = 100 for i in range(n): print(i) for i in range(n): ##每循i里的一个元素,for循环内部嵌套的for循环就整个循环一次 for q in range(n): print(q)
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
Ο(1)表示基本语句的执行次数是一个常数,一般来说,只要算法中不存在循环语句,其时间复杂度就是Ο(1)。
其中Ο(log2n)、Ο(n)、 Ο(nlog2n)、Ο(n2)和Ο(n3)称为多项式时间,而Ο(2n)和Ο(n!)称为指数时间,计算机科学家普遍认为前者(即多项式时间复杂度的算法)是有效算法,把这类问题称为P(Polynomial,多项式)类问题,而把后者(即指数时间复杂度的算法)称为NP(Non-Deterministic Polynomial, 非确定多项式)问题。在选择算法的时候,优先选择前者!
OK我懂对于没有算法基础的同学,看起算法来也很头疼,但是这个是基础和重点,不会算法的开发不是一个合格的开发并且包括语言记得基础也是需要好好整理的!加油吧~~ 咱们在一起看下时间复杂度的详细说明吧
1、O(1)
#O(1) n = 100 sum = (1+n) * n/2 #执行一次 sum_1 = (n/2) - 10 #执行一次 sum_2 = n*4 - 10 + 8 /2 #执行一次
这个算法的运行次数函数是f(n)=3。根据我们推导大O阶的方法,第一步就是把常数项3改为1。在保留最高阶项时发现,它根本没有最高阶项,所以这个算法的时间复杂度为O(1)。
并且:如果算法的执行时间不随着问题规模n的增长而增加,及时算法中有上千条语句,其执行的时间也不过是一个较大的常数。此类算法的时间复杂度记作O(1)
2、O(n2)
n = 100 for i in range(n): #执行了n次 for q in range(n): #执行了n2 print(q) #执行了n2
解:T(n)=2n2+n+1=O(n2)
一般情况下,对进循环语句只需考虑循环体中语句的执行次数,忽略该语句中步长加1、终值判别、控制转移等成分,当有若干个循环语句时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。
3、O(n)
#O(n) n =100 a = 0 #执行一次 b = 1#执行一次 for i in range(n): #执行n次 s = a +b #执行n-1次 b =a #执行n-1次 a =s #执行n-1次
解:T(n)=2+n+3(n-1)=4n-1=O(n)
4、Ο(n3)
#O(n3) n = 100 for i in range(n):#执行了n次 for q in range(n):#执行了n^2 for e in range(n):#执行了n^3 print(e)#执行了n^3
简单点来去最大值是:Ο(n3)
5、常用的算法的时间复杂度和空间复杂度
| 排序法 | 平均时间 | 最差情况 | 稳定度 | 额外空间 | 备注 |
| 冒泡排序 | Ο(n2) | Ο(n2) | 稳定 | O(1) | n小时较好 |
| 交换排序 | Ο(n2) | Ο(n2) | 不稳定 | O(1) | n小时较好 |
| 选择排序 | Ο(n2) | Ο(n2) | 不稳定 | O(1) | n小时较好 |
| 插入排序 | Ο(n2) | Ο(n2) | 稳定 | O(1) | 大部分已排序时较好 |
| 快速排序 | Ο(nlogn) | Ο(n2) | 不稳定 | Ο(nlogn) | n较大时较好 |
| 希尔排序(SHELL) | Ο(log2n) | Ο(ns) 1<s<2 |
不稳定 | O(1) | s是所选分组 |
| 归并排序 | Ο(log2n) | Ο(log2n) | 稳定 | O(1) | n大时较好 |
| 堆排序 | Ο(log2n) | Ο(log2n) | 不稳定 | O(1) | n大时较好 |
| 基数排序 | Ο(logRB) | Ο(logRB) | 稳定 | O(N) |
B是真数(0-9) R是基数(个十百) |
排序算法是在更复杂的算法中的是一个构建基础,所以先看下常用的排序。
1、冒泡排序
需求:
请按照从小到大对列表,进行排序==》:[69, 471, 106, 66, 149, 983, 160, 57, 792, 489, 764, 589, 909, 535, 972, 188, 866, 56, 243, 619]
思路:相邻两个值进行比较,将较大的值放在右侧,依次比较!
原理图:
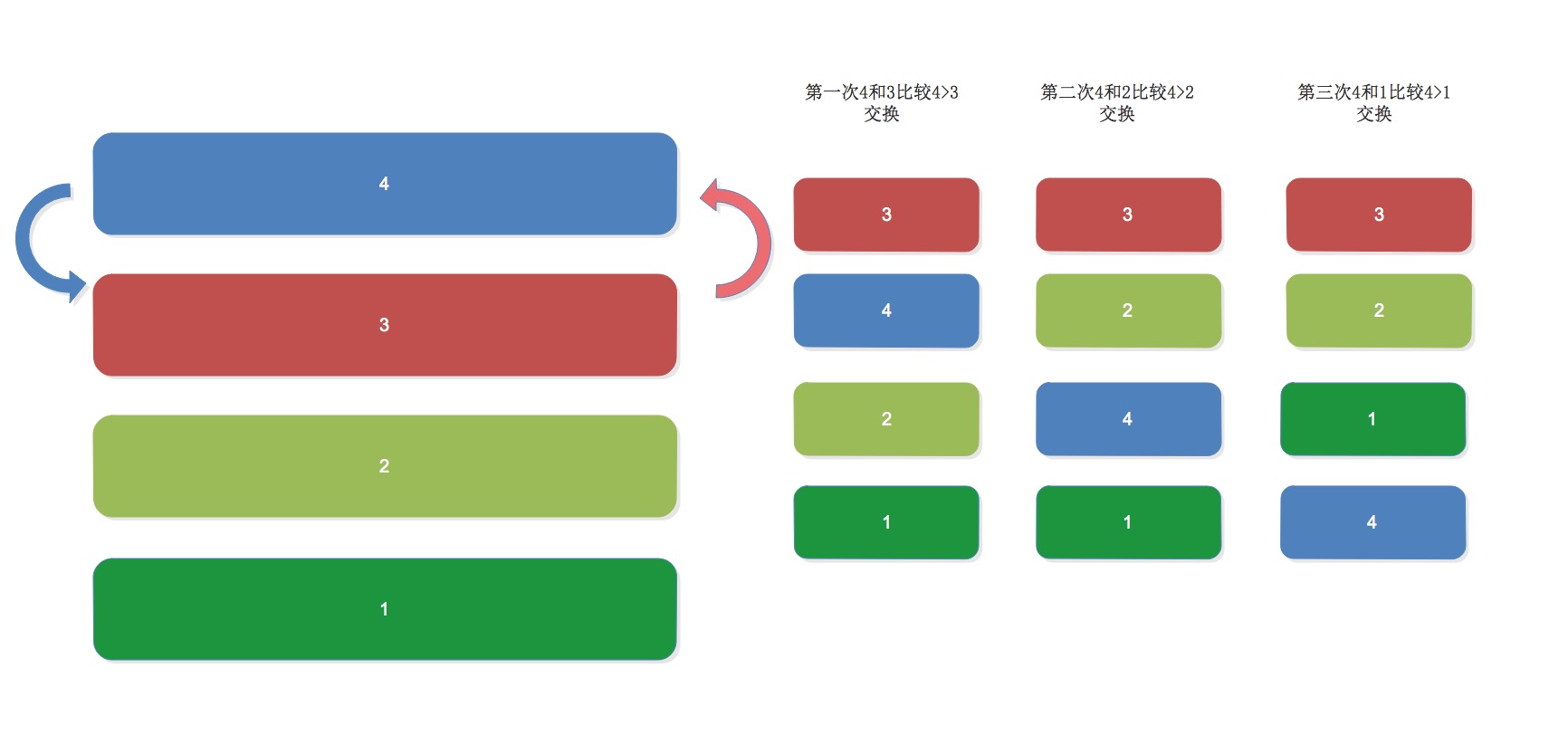
原理分析:
列表中有5个元素两两进行比较,如果左边的值比右边的值大,就用中间值进行循环替换!
既然这样,我们还可以用一个循环把上面的循环进行在次循环,用表达式构造出内部循环!
代码实现:
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = ‘luotianshuai‘ import random maopao_list = [13, 22, 6, 99, 11] ‘‘‘ 原理分析: 列表中有5个元素两两进行比较,如果左边的值比右边的值大,就用中间值进行循环替换! 既然这样,我们还可以用一个循环把上面的循环进行在次循环,用表达式构造出内部循环! ‘‘‘ def handler(array): for i in range(len(array)): for j in range(len(array)-1-i): ‘‘‘ 这里为什么要减1,我们看下如果里面有5个元素我们需要循环几次?最后一个值和谁对比呢?对吧!所以需要减1 这里为什么减i?,这个i是循环的下标,如果我们循环了一次之后最后一只值已经是最大的了还有必要再进行一次对比吗?没有必要~ ‘‘‘ print(‘left:%d‘ % array[j],‘right:%d‘ % array[j+1]) if array[j] > array[j+1]: tmp = array[j] array[j] = array[j+1] array[j+1] = tmp if __name__ == ‘__main__‘: handler(maopao_list) print(maopao_list)
时间复杂度说明看下他的代码复杂度会随着N的增大而成指数型增长,并且根据判断他时间复杂度为Ο(n2)
2、选择排序
需求:
请按照从小到大对列表,进行排序==》:[69, 471, 106, 66, 149, 983, 160, 57, 792, 489, 764, 589, 909, 535, 972, 188, 866, 56, 243, 619]
思路:
第一次,从列表最左边开始元素为array[0],往右循环,从右边元素中找到小于array[0]的元素进行交换,直到右边循环完之后。
第二次,左边第一个元素现在是最小的了,就从array[1],和剩下的array[1:-1]内进行对比,依次进行对比!
对比:
他和冒泡排序的区别就是,冒泡排序是相邻的两两做对比,但是选择排序是左侧的“对比元素”和右侧的列表内值做对比!
原理图:
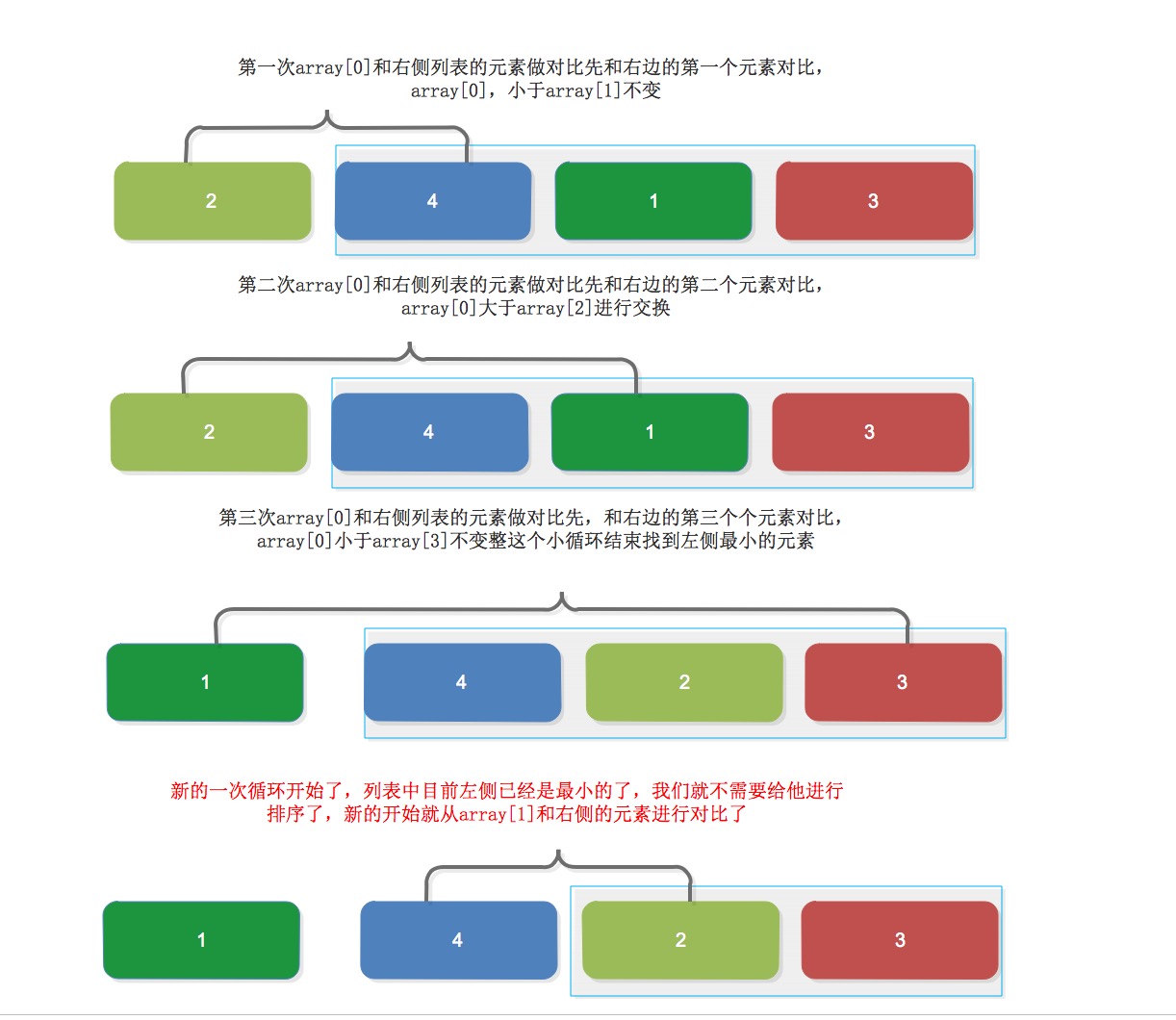
代码实现:
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = ‘luotianshuai‘ xuanze_list = [13, 22, 6, 99, 11] print(range(len(xuanze_list))) def handler(array): for i in range(len(array)): ‘‘‘ 循环整个列表 ‘‘‘ for j in range(i,len(array)): ‘‘‘ 这里的小循环里,循环也是整个列表但是他的起始值是i,当这一个小循环完了之后最前面的肯定是已经排序好的 第二次的时候这个值是循环的第几次的值比如第二次是1,那么循环的起始值就是array[1] ‘‘‘ if array[i] > array[j]: temp = array[i] array[i] = array[j] array[j] = temp # print(array) if __name__ == ‘__main__‘: handler(xuanze_list) print(xuanze_list)
选择排序代码优化:
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = ‘luotianshuai‘ import random import time def handler(array): for i in range(len(array)): smallest_index = i #假设默认第一个值最小 for j in range(i,len(array)): if array[smallest_index] > array[j]: smallest_index = j #如果找到更小的,记录更小元素的下标 ‘‘‘ 小的循环结束后在交换,这样整个小循环就之前的选择排序来说,少了很多的替换过程,就只替换了一次!提升了速度 ‘‘‘ tmp = array[i] array[i] = array[smallest_index] array[smallest_index] = tmp if __name__ == ‘__main__‘: array = [] old_time = time.time() for i in range(50000): array.append(random.randrange(1000000)) handler(array) print(array) print(‘Cost time is :‘,time.time() - old_time)
3、插入排序
需求:
请按照从小到大对列表,进行排序==》:[69, 471, 106, 66, 149, 983, 160, 57, 792, 489, 764, 589, 909, 535, 972, 188, 866, 56, 243, 619]
思路:
一个列表默认分为左侧为排序好的,我们拿第一个元素举例,他左边的全是排序好的,他右侧是没有排序好的,如果右侧的元素小于左侧排序好的列表的元素就把他插入到合适的位置
原理图:
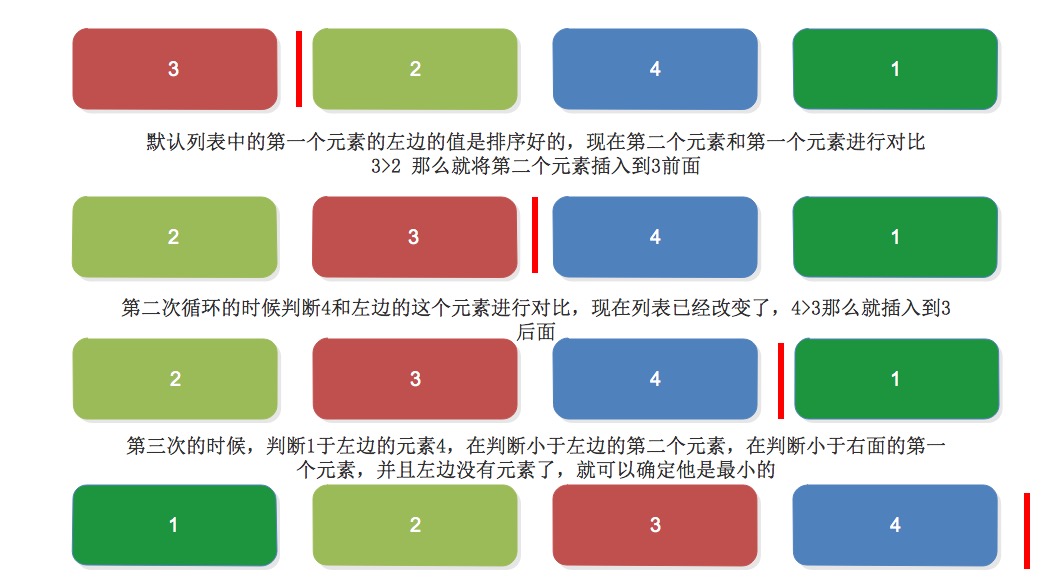
代码实现:
#!/usr/bin/env python #-*- coding:utf-8 -*- __author__ = ‘luotianshuai‘ import random import time chaoru_list = [69, 471, 106, 66, 149, 983, 160, 57, 792, 489, 764, 589, 909, 535, 972, 188, 866, 56, 243, 619] def handler(array): for i in range(1,len(array)): position = i #刚开始往左边走的第一个位置 current_val = array[i] #先把当前值存下来 while position > 0 and current_val < array[position -1]: ‘‘‘ 这里为什么用while循环,咱们在判断左边的值得时候知道他有多少个值吗?不知道,所以用while循环 什么时候停下来呢?当左边没有值得时候,或者当他大于左边的值得时候! ‘‘‘ array[position] = array[position - 1] #如果whille条件成立把当前的值替换为他上一个值 ‘‘‘ 比如一个列表: [3,2,4,1] 现在循环到 1了,他前面的元素已经循环完了 [2,3,4] 1 首先我们记录下当前这个position的值 = 1 [2,3,4,4] 这样,就出一个位置了 在对比前面的3,1比3小 [2,3,3,4] 在替换一下他们的值 在对比2 [2,2,3,4] 最后while不执行了在进行替换‘array[position] = current_val #把值替换‘ ‘‘‘ position -= 1 #当上面的条件都不成立的时候{左边没有值/左边的值不比自己的值小} array[position] = current_val #把值替换 if __name__ == ‘__main__‘: handler(chaoru_list) print(chaoru_list) ‘‘‘ array = []#[69, 471, 106, 66, 149, 983, 160, 57, 792, 489, 764, 589, 909, 535, 972, 188, 866, 56, 243, 619] old_time = time.time() for i in range(50000): array.append(random.randrange(1000000)) handler(array) print(array) print(‘Cost time is :‘,time.time() - old_time) ‘‘‘
4、快速排序
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动.他的时间复杂度是:O(nlogn) ~Ο(n2)
排序示例:
假设用户输入了如下数组:
创建变量i=0(指向第一个数据)[i所在位置红色小旗子], j=5(指向最后一个数据)[j所在位置蓝色小旗子], k=6(赋值为第一个数据的值)。
i=0 j=3 k=6
i=2 j=3 k=6
如果i和j没有碰头的话,就递加i找大的,还没有,就再递减j找小的,如此反复,不断循环。注意判断和寻找是同时进行的。
代码实现:
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:luotianshuai import random import time def quick_sort(array,start,end): if start >= end: return k = array[start] left_flag = start right_flag = end while left_flag < right_flag: ‘‘‘ left_flag = start 默认为0 right_flag = end 默认为传来的列表总长度 当left_flag 小与right_flag的时候成立,说明左右两边的小旗子还没有碰头(为相同的值) ‘‘‘ #右边旗子 while left_flag < right_flag and array[right_flag] > k:#代表要继续往左一移动小旗子 right_flag -= 1 ‘‘‘ 如果上面的循环停止说明找到右边比左边的值小的数了,需要进行替换 ‘‘‘ tmp = array[left_flag] array[left_flag] = array[right_flag] array[right_flag] = tmp #左边旗子 while left_flag < right_flag and array[left_flag] <= k: #如果没有找到比当前的值大的,left_flag 就+=1 left_flag += 1 ‘‘‘ 如果上面的循环停止说明找到当前段左边比右边大的值,进行替换 ‘‘‘ tmp = array[left_flag] array[left_flag] = array[right_flag] array[right_flag] = tmp #进行递归把问题分半 quick_sort(array,start,left_flag-1) quick_sort(array,left_flag+1,end) if __name__ == ‘__main__‘: array = [] # [69, 471, 106, 66, 149, 983, 160, 57, 792, 489, 764, 589, 909, 535, 972, 188, 866, 56, 243, 619] start_time = time.time() for i in range(50000): array.append(random.randrange(1000000)) quick_sort(array,0,len(array)-1) end_time = time.time() print(array) print(start_time,end_time) cost_time = end_time - start_time print(‘Cost time is :%d‘ % cost_time)
标签:菜谱 循环 时间复杂度 冒泡排序 第一个 区别 复杂度 相加 依赖
原文地址:http://blog.csdn.net/quiet_boy/article/details/53635774