标签:parse pattern ota str margin rank 文件名 ... reading
大概半年前我开始学习python,也就是半年前,我半抄半改的同样的爬虫写了出来,由于是单线程的程序,当中出了一点的小错就会崩溃,但是那个爬虫中的header之类的东西现在依旧还是能够使用的,于是我就把之前那份的保留了下来。由于有一半是抄的,自己得到的并不多,这次重写,我相当于又重新学习了一遍。,当中有可能有认识不足的,欢迎指正。
首先我们要想登陆p站,得构造一个请求,p站登陆的请求包括:
request = urllib.request.Request( #创建请求 url=login_url, #链接 data=login_data, #数据 headers=login_header #头 )
url通过猜测就可以得到是https://www.pixiv.net/login.php,但是由于采用了https加密data和headers却不好获得,这里我采用了之前的那份的,没想到还能用:
data = { #构建请求数据
"pixiv_id": self.id, #账号
"pass": self.passwd, #密码
"mode": "login",
"skip": 1
}
login_header = { #构建请求头
"accept-language": "zh-cn,zh;q=0.8",
"referer": "https://www.pixiv.net/login.php?return_to=0",
"user-agent": "mozilla/5.0 (windows nt 10.0; win64; x64; rv:45.0) gecko/20100101 firefox/45.0"
}
因为是要爬取多个页面的图,我这里采用cookie登陆的方式,不过因为可能cookie会变每次运行还得重新登陆:
cookie = http.cookiejar.MozillaCookieJar(".cookie") #创建cookie每次都覆盖,进行更新 handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open(request) print("Log in successfully!") cookie.save(ignore_discard=True, ignore_expires=True) response.close() print("Update cookies successfully!")
登陆解决了,cookie登陆其实是很简单的,只要载入本地的cookie文件就行了:
def cookie_opener(self): #使用cookie登陆, 创建opener cookie = http.cookiejar.MozillaCookieJar() cookie.load(".cookie", ignore_discard=True, ignore_expires=True) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) return opener
一开始我的想法是先将所有的链接中的图片链接解析出来,然后再下载,在统筹学看来这样的做法就是完全的浪费时间的,因为解析和下载所用的时间是不一样的,解析可能会花上3,4分钟,而单独的下载只要10秒以内。在计算机允许的情况下,一个线程专门负责解析,另外的线程专门负责下载,效率会非常的高。
后来通过学习,我改成了生产者消费者模式:
1. 一个Crawler爬取链接中的图片链接,放入处理队列中
2. n个Downloader下载爬出到的图片
如图:
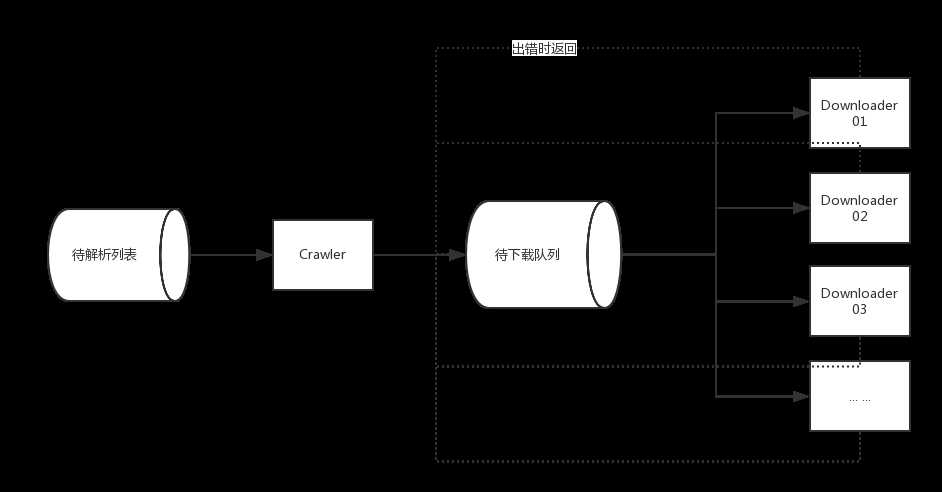
本文的生产者和消费者模式示意图
可以做到边解析,边下载,由于通常解析的速度是快于下载的速度的,一开始可能下载的速度是快过解析的,但是后来会被反超,采用一个解析器对多个下载器的模式效率并没有多小的差别。
具体的实现,我是将downloader作为threading.Thread的一个派生类:
class downloader (threading.Thread): #将一个下载器作为一个线程 def __init__(self, q, path, opener): threading.Thread.__init__(self) self.opener = opener #下载器用的opener self.q = q #主队列 self.sch = 0 #进度[0-50] self.is_working = False #是否正在工作 self.filename = "" #当前下载的文件名 self.path = path #文件路径 self.exitflag = False #是否退出的信号 def run(self): def report(blocks, blocksize, total): #回调函数用于更新下载的进度 self.sch = int(blocks * blocksize / total * 50) #计算当前下载百分比 self.sch = min(self.sch, 50) #忽略溢出 def download(url, referer, path): #使用urlretrieve下载图片 self.opener.addheaders = [ #给opener添加一个头 (‘Accept-Language‘, ‘zh-CN,zh;q=0.8‘), (‘User-agent‘, ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:45.0) Gecko/20100101 Firefox/45.0‘), (‘Referer‘, referer) #p站的防盗链机制 ] pattern = re.compile(r‘([a-zA-Z.0-9_-]*?)$‘) #正则匹配处理模式 filename = re.search(pattern, url).group(0) #匹配图片链接生成本地文件名 if filename.find("master") != -1: #去除多图的master_xxxx的字符串 master = re.search(re.compile(r‘_master[0-9]*‘), filename) filename = filename.replace(master.group(0), ‘‘) self.filename = filename urllib.request.install_opener(self.opener) #添加更新后的opener try: urllib.request.urlretrieve(url, path + filename, report) #下载文件到本地 except: os.remove(path + filename) #如果下载失败,将问题文件删除,并将referer和url重新放入队列 self.q.put((referer, url)) while not self.exitflag: if not self.q.empty(): #当队列非空获取队列首部元素,开始下载 links = self.q.get() self.is_working = True download(links[1], links[0], self.path) self.sch = 0 #置零 self.is_working = False
封装的downloader类作为一个单独的线程起到了和threading.Thread一样的作用,同时对下载器任务的一些说明,可以在后面的运行的过程中显示各个下载器的进度。
爬取地址的时候,先把排行榜首页的扫一遍,获取所有作品的地址,以下都用到了beautifulsoup模块:
response = opener.open(self.url) html = response.read().decode("gbk", "ignore") #编码,忽略错误(错误一般不存在在链接上) soup = BeautifulSoup(html, "html5lib") #使用bs和html5lib解析器,创建bs对象 tag_a = soup.find_all("a") for link in tag_a: top_link = str(link.get("href")) #找到所有<a>标签下的链接 if top_link.find("member_illust") != -1: pattern = re.compile(r‘id=[0-9]*‘) #过滤存在id的链接 result = re.search(pattern, top_link) if result != None: result_id = result.group(0) url_work = "http://www.pixiv.net/member_illust.php?mode=medium&illust_" + result_id if url_work not in self.rankurl_list: self.rankurl_list.append(url_work)
解析由于只有一个线程,所以我就用了一般的用法:
def _crawl(): while len(self.rankurl_list) > 0: url = self.rankurl_list[0] response = opener.open(url) html = response.read().decode("gbk", "ignore") #编码,忽略错误(错误一般不存在在链接上) soup = BeautifulSoup(html, "html5lib") imgs = soup.find_all("img", "original-image") if len(imgs) > 0: self.picurl_queue.put((url, str(imgs[0]["data-src"]))) else: multiple = soup.find_all("a", " _work multiple ") if len(multiple) > 0: manga_url = "http://www.pixiv.net/" + multiple[0]["href"] response = opener.open(manga_url) html = response.read().decode("gbk", "ignore") soup = BeautifulSoup(html, "html5lib") imgs = soup.find_all("img", "image ui-scroll-view") for i in range(0, len(imgs)): self.picurl_queue.put((manga_url + "&page=" + str(i), str(imgs[i]["data-src"]))) self.rankurl_list = self.rankurl_list[1:] self.crawler = threading.Thread(target=_crawl) #开第一个线程用于爬取链接,生产者消费者模式中的生产者 self.crawler.start()
与此同时生成和之前所设的最大线程数相等的线程:
for i in range(0, self.max_dlthread): #根据设定的最大线程数开辟下载线程,生产者消费者模式中的消费者 thread = downloader(self.picurl_queue, self.os_path, opener) thread.start() self.downlist.append(thread) #将产生的线程放入一个队列中
接下来就是显示多线程每一个线程的下载进度,同时等待所有的事情处理结束了:
flag = False while not self.picurl_queue.empty() or len(self.rankurl_list) > 0 or not flag: #显示进度,同时等待所有的线程结束,结束的条件(这里取相反): #1 下载队列为空 #2 解析列表为空 #3 当前所有的下载任务完成 os.system("cls") flag = True if len(self.rankurl_list) > 0: print(str(len(self.rankurl_list)) + " urls to parse...") if not self.picurl_queue.empty(): print(str(self.picurl_queue.qsize()) + " pics ready to download...") for t in self.downlist: if t.is_working: flag = False print("Downloading " + ‘"‘ + t.filename + ‘" : \t[‘ + ">"*t.sch + " "*(50-t.sch) + "] " + str(t.sch*2) + " %") else: print("This downloader is not working now.") time.sleep(0.1)
下面是实际运行的图:
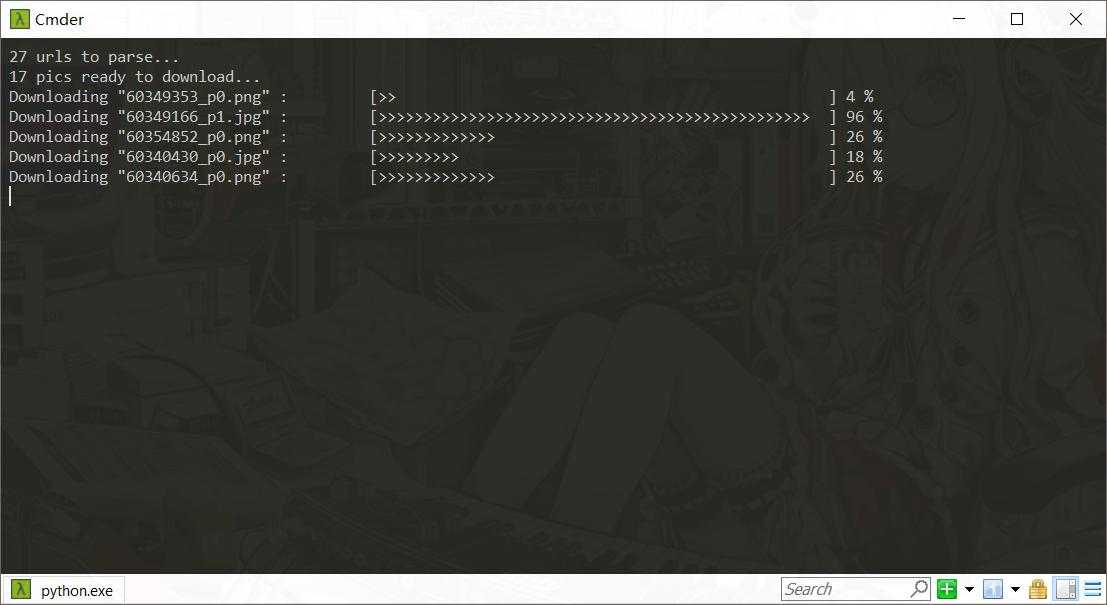
多线程,每个线程的进度都不同,上面显示的分别是需要解析的链接和已经准备好要下载的链接
等到所有的任务结束,给所有的线程发送一个退出指令:
for t in self.downlist: #结束后给每一个下载器发送一个退出指令 t.exitflag = True
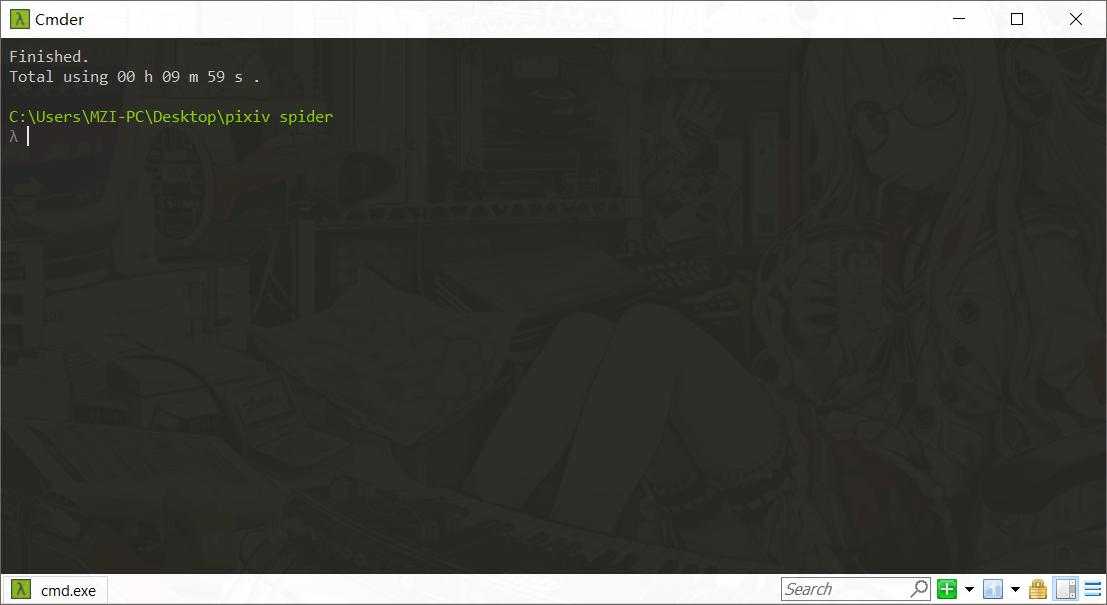
等所有任务结束,系统将会给出下载所用的时间:
def start(self): st = time.time() self.login() opener = self.cookie_opener() self.crawl(opener) ed = time.time() tot = ed - st intvl = getTime(int(tot)) os.system("cls") print("Finished.") print("Total using " + intvl + " .") #统计全部工作结束所用的时间
2016年12月14日,p站每日榜全部爬取所用的时间:
下面给出coding上的地址:
https://coding.net/u/MZI/p/PixivSpider/git
简单的实现一个python3的多线程爬虫,爬取p站上的每日排行榜
标签:parse pattern ota str margin rank 文件名 ... reading
原文地址:http://www.cnblogs.com/mzi1234/p/6180529.html