标签:插入 贪心 存储 外部存储 als eof 关心 记录 数据
1.概述
排序是计算机程序设计中的一个重要操作,它的功能是将一个数据记录(或记录)的任意序列,重新排列成一个按关键字有序的序列。
为了方便描述,我们先确切定义排序:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},要确定一种序列,该序列的关键字满足非递减(或非递增)关系,这种操作称之为排序。
若n个记录的序列中的任意两个记录排序前后的顺序一致则称这种排序是稳定的。
例如:原序列中Ri排在Rj之前,1<=i<=n,1<=j<=n,i!=j,排序之后依旧Ri排在Rj之前,这就是稳定排序,反之,不稳定排序。
如果排序只在RAM中进行则称之为内部排序,如果涉及到了外部存储器(比如磁盘、固态硬盘、软盘和闪存等)则称之为外部排序。
为什么会有这两种方式呢,很简单,如果处理的数据极大,一次不能全部读入内存,则需要借助外部存储器进行排序。
2.插入排序
2.1直接插入排序
最简单的排序方式,基本操作是将一个记录插入到已排好序的有序表中,从而得到一个新的、记录长度加1的有序表。
简单证明:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},初始取该序列的第一个记录为有序序列。
第一步取该序列的第二个记录,插入有序序列的适当位置,使之有序;
假设第n-2步之后的原有序序列有序;
第n-1步时选取含n个记录的序列为{R1,R2,R3,...,Rn}的第n个记录,插入有序序列的适当位置,使之有序,则第n-1步之后的有序序列仍然有序。
证毕。
那么如何插入有序序列的适当位置呢?
含n个记录的序列为{R1,R2,R3,...,Rn}中选取第i个记录时,前面i-1个记录已经有序,则首先比较第i个记录与第i-1个记录的大小,如果第i个记录小于第i-1记录,则交换,再从第i-2个记录向前搜索,在搜索过程中,只要遇到大于第i个记录的记录,就将当前记录后移一个位置,直至某个记录小于或者等于第i个记录或者向前搜索到了第0个位置。
其算法如下:
 insertSort
insertSort
算法时间复杂度:
排序的基本操作为比较关键字大小和移动记录,当排序序列为逆序且关键字不重复时时间复杂度最大。简单证明一下:
当选中第i个记录,要对其操作时,最长不过搜索到第0个位置,也就是比较i次,移动i+1次;
如果有n个记录则要进行n-1次的选记录,如果每次搜索到第0个位置,也就是每次比较最多次,移动最多次,那么总得加起来就是总的比较了最多次,总的移动了最多次。前面一句话体现了一个算法策略,贪心算法。这个算法不一定正确,我们用反证法证明在这里的正确性。
假设这样的构造过程得到的总的移动次数,总的比较次数不是最多,也就是存在更大的数值,
我们每次都是选择最多的,如果存在更大的数值,则说明某次选择的不是最多的,这与我们的构造过程是矛盾的,所以假设不成立。
那么如何确定每次比较最多次,移动最多次的序列为逆序序列呢?
很简单,如果不是每次的都是逆序,那么一定存在某次选择未搜索到第0个位置就停止前向搜索了,因为找到了一个不小于(或者不大于)第i个记录的记录。
证毕。
最大移动次数:
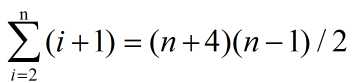
最大比较次数:
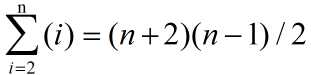
2.2其他插入排序
折半插入排序,由于插入排序的基本操作是在一个有序表中进行查找和插入,那么我们可以用折半查找来实现查找操作。
算法的正确性证明与直接插入排序一致,只是查找的过程不同。
算法时间复杂度:
虽然查找过程的时间复杂度为
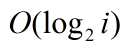 , 当i足够大时
, 当i足够大时
但是最大移动次数不变,所以算法时间复杂度依旧为
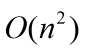
2.3希尔排序
先将整个待排序列分割成若干个子序列,分别进行插入排序,等整个序列基本有序,再对全体进行一次直接插入排序。
它的证明涉及到数学上一些尚未解决的难题,有兴趣可以查看相关论文,一般不用这个算法内部排序。
3.交换排序
3.1冒泡排序
首先将第1个位置的关键字和第2个记录的关键字比较,若为逆序,即第一个位置的关键字比第二个位置的关键字大,则将两个记录交换,然后比较第2个位置的关键字和第3个位置的关键字的大小,若为逆序,则交换记录,以此类推。
简单证明:
假设含n个记录的序列为{R1,R2,R3,...,Rn},其相应的关键字序列为{K1,K2,K3,...,Kn},
第1步从第1个记录开始,依次与最近的后面位置的记录比较关键字大小,若为逆序,则交换,当第n-1个记录与第n个记录比较关键字 之后,关键字最大的记录一定在第n个位置(为什么呢?你想嘛,每次都把关键字较大的往后移,比较完后当然是最大的在最后面了),有序序列为第n个记录
假设第n-2步从第1个记录开始到第1个记录结束,每个记录与最近的后面位置的记录比较关键字大小,若为逆序,则交换,比较完并且将关键字较大的记录加入有序序列后,有序序列为第3个记录到n个记录
第n-1步时,由于无序序列只有前面两个,比较一次,直接加入有序序列,加入后,有序序列为第1个记录到第n个记录。
证毕。
bubbleSort
算法时间复杂度:
若含n个记录的序列{R1,R2,R3,...,Rn}按关键字大小比较,为逆序,则总的时间复杂度最高。
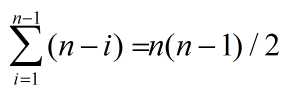 ,所以总的时间复杂度为
,所以总的时间复杂度为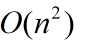
3.2快速排序
通过一趟排序将待排的记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
这里体现了一个算法策略--分治法。将一个问题划分为一个个子问题,再分别求解子问题,最后合并起来就是原问题的解。
具体实现:首先任意选取一个记录,通常是第一个记录,作为枢轴pivot。定义两个指针low和high,分别指向起始段和末端。high从所指的位置开始向前搜索找到第一个关键字小于pivot的记录,然后low所指位置起向后搜索,找到第一个关键字大于pivot的记录,再交换low和high所指向的位置的记录(low<high),重复这一步骤,直至low等于high。
qSort
算法时间复杂度分析:
,
从快速排序的过程我们可以得到下面的方程:
最坏情况:
T(n)=T(n-1)+n (n>=2,n∈N+,为什么是这个范围呢,等于1的时候直接退出,不用比较;只有一个记录比较啥)
T(1)=0,T(2)=2;
T(n)为总的问题的工作量,n为划分过程的工作量。算法的时间复杂度分析,一般关心的是关键语句的执行次数,这里的比较操作是关键语句。说明叫关键语句呢,执行次数最多的语句就叫关键语句。
为什么划分过程中的工作量为n呢,必须的啊,无论你怎么玩,每次都要将枢轴与枢轴所在序列的所有记录的关键字比较大小,直至low等于high。也就是总共进行了n次比较。
T函数中的自变量表示该问题下的序列长度。
最坏情况,也就是,你每次苦逼的比较了所有的数,但是每次都只得到一个子序列,仅比序列长度少1。
这个递推方程是不是很熟悉,无论你用递归树还是累加法都可以轻而易举得到
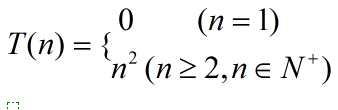
所以最坏情况的时间复杂度为O(n2)。
最好情况:
T(n)=2T(n/2)+n
每次得到两个相等的子序列。为什么呢?假设每次划分后的两个子序列分别为a和b,a+b表示这两个子序列在划分过程中的总工作量,想想大名鼎鼎的柯西不等式,你就知道当且仅当a=b时最小原式最小。
由主定理可以轻松得到最好的时间复杂度,不过,知其然知其所以然更好,我们就走走推导过程。

所以最好的时间复杂度为O(nlog2n)
4.测试
完整代码
#include<stdio.h>
#include<stdlib.h>
#include<conio.h>
#define MaxSize 100
typedef struct _recordType
{
int key;
int name;
}recordType;
typedef struct _seqList
{
recordType r[MaxSize + 1];
int length;
}seqList;
void insertSort(seqList *l)
{
for (int i = 2; i <= l->length; i++)
/*
初始选择第1个元素为有序序列,第一步选取该序列的第2个元素
*/
{
if (l->r[i].key < l->r[i - 1].key) /*
首先比较第i个元素与第i-1个元素的大小,如果第i个元素小于第i-1元素,则交换
*/
{
l->r[0] = l->r[i];
l->r[i] = l->r[i - 1];
int j = 0;
for (j = i - 2; l->r[0].key < l->r[j].key; --j)
/*
再从第i-2个元素向前搜索,在搜索过程中,只要遇到大于第i个元素的元素,就将当前元素后移一个位置,直至某个元素小于或者等于第i个元素或者向前搜索到了第0个位置
*/
{
l->r[j + 1] = l->r[j];
}
l->r[j + 1] = l->r[0];
}
}
}
void bInsertSort(seqList *l)
{
int low = 0;
int high = 0;
int m = 0;
for (int i = 2; i <=l->length; i++)
/*
初始选择第1个元素为有序序列,第一步选取该序列的第2个元素
*/
{
l->r[0] = l->r[i];
low = 1;
high = i - 1;
while (low <= high)
/*
折半查找
*/
{
m = (low + high) / 2;
if (l->r[0].key < l->r[m].key)high = m - 1;
else
low = m + 1;
}
for (int j = i - 1; j >= high + 1; --j)
{
l->r[j + 1] = l->r[j];
}
/*
找到对应插入位置,将对应插入位置到第i-1个位置的元素后移
*/
l->r[high + 1] = l->r[0];
}
}
void bubbleSort(seqList *l)
{
recordType tmp;
bool swap = false;
for (int i = 0; i < l->length-1; i++)/*
总共进行n-1步
*/
{
swap = false;
for (int j = 1; j <l->length - i; ++j)
/*
每一步从第1个元素开始到第n-i-1元素结束,每个元素与最近的后面位置比较
关键字大小,若为逆序则交换
*/
{
if (l->r[j].key > l->r[j + 1].key)
{
swap = true;
tmp = l->r[j + 1];
l->r[j + 1] = l->r[j];
l->r[j] = tmp;
}
}
if (swap == false)break;
/*
如果在比较关键字大小时没有记录移动,则说明前面的记录已经按关键字有序
*/
}
}
int partition(seqList *l, int low, int high)
{
l->r[0] = l->r[low];
/*
在某趟快速排序中,首先任意选取一个记录,通常是第一个记录,作为枢轴pivot
*/
recordType tmp;
while (low < high)
/*
如果low==high,说明某趟快速排序已经搜索完所有记录并找到了枢轴的恰当位置
使得枢轴左边的记录的关键字都小于等于枢轴右边记录的关键字都大于等于枢轴
*/
{
while ((low < high)&&(l->r[0].key > l->r[low].key))++low;
while ((low < high)&&(l->r[0].key < l->r[high].key))--high;
if (low <high)
{
tmp = l->r[low];
l->r[low] = l->r[high];
l->r[high] = tmp;
}
low = low + 1;
high = high - 1;
}
return low;
}
void qSort(seqList *l, int low, int high)
{
/*
将某个序列递归的分为多个子序列,直至子问题的规模不超过零
*/
if (low < high)
{
int pivotPos = partition(l, low, high);/*将序列l->[low...high]一分为二*/
qSort(l, pivotPos + 1, high);/*对高子表递归排序*/
qSort(l, low, pivotPos - 1);/*对低子表递归排序*/
}
}
int sum(seqList *l,int n)
{
if (n > 0)
return sum(l, n - 1) + l->r[n].key;
else
return 0;
}
int main(void)
{
freopen("in.txt", "r", stdin);
seqList *l = (seqList*)malloc(sizeof(seqList));
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
insertSort(l);
printf("Straight Insertion Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
fseek(stdin, 0, 0);
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
bInsertSort(l);
printf("Binary Insertion Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
fseek(stdin, 0, 0);
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
bubbleSort(l);
printf("Bubble Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
fseek(stdin, 0, 0);
scanf("%d", &l->length);
for (int i = 1; i <= l->length; i++)
{
scanf("%d", &l->r[i].key);
}
qSort(l, 1, l->length);
printf("Quick Sort:\n");
for (int i = 1; i <= l->length; i++)
{
printf("%d ", l->r[i].key);
}
printf("\n");
printf("%d\n", sum(l, l->length));
getch();
}
测试文本:

测试结果

在这个浮躁的社会,很多人只是粘贴一份算法,跑一边,就算懂了,我们应该沉下心来
标签:插入 贪心 存储 外部存储 als eof 关心 记录 数据
原文地址:http://www.cnblogs.com/GaussianPrince/p/6185303.html