标签:list
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取阅读数
#coding=utf-8 from selenium import webdriver import unittest from time import sleep class Weibo(unittest.TestCase): def setUp(self): self.dr = webdriver.Chrome() self.hot_list = self.get_weibo_hot_topic() self.weibo_topic = self.get_top_rank_file() def get_weibo_hot_topic(self): self.dr.get(‘http://weibo.com/‘) sleep(5) self.login(‘649004152@qq.com‘,‘kemi_xxxx‘) #微博帐号密码 self.dr.get(‘http://d.weibo.com/100803?refer=index_hot_new‘) #热门话题url sleep(5) hot_topic_list = [] i = 0 while i < 15: rank_and_topic = self.dr.find_elements_by_css_selector(‘.title.W_autocut‘)[i].text #定位排行和话题 number = self.dr.find_elements_by_css_selector(‘.number‘)[i].text #定位阅读数 hot_topic_list.append([rank_and_topic, number]) i += 1 return hot_topic_list def get_top_rank_file(self): self.file_title = ‘微博24小时热门话题‘ self.file = open(self.file_title + ‘.txt‘, ‘wb‘) for item in self.hot_list: separate_line = ‘~~~~~~~~~~~~~~~~~~~~~~~~\n‘ self.file.write(separate_line.encode(‘utf-8‘)) self.file.write((item[0]+‘ ‘+‘阅读数:‘+item[1]+‘\n‘).encode(‘utf-8‘)) self.file.close() def login(self, username, password): self.dr.find_element_by_name(‘username‘).clear() self.dr.find_element_by_name(‘username‘).send_keys(username) self.dr.find_element_by_name(‘password‘).send_keys(password) self.dr.find_element_by_css_selector(‘.info_list.login_btn‘).click() def test_weibo_topic(self): pass print(‘抓取完毕‘) def tearDown(self): self.dr.quit() if __name__== ‘__main__‘: unittest.main()
网页如下:
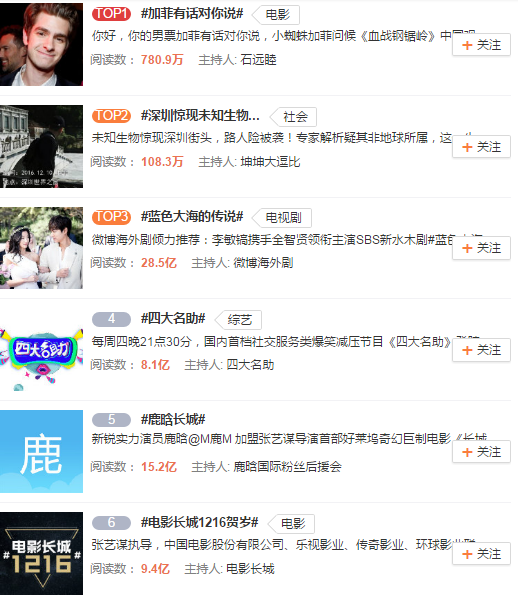
生成txt文件如下:

本文出自 “无想法,无成就!” 博客,请务必保留此出处http://kemixing.blog.51cto.com/10774787/1883205
用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
标签:list
原文地址:http://kemixing.blog.51cto.com/10774787/1883205