标签:style blog http color 使用 文件 数据 for

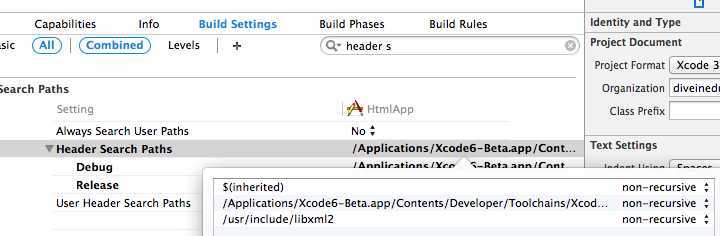
首先,新建一个工程,到Build Phases-link Binary With Libraries,点+添加libxml2运行库
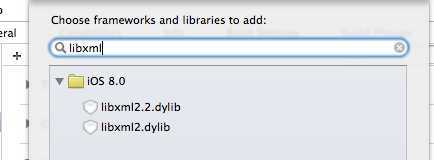
再到build settings中搜索Header search Paths,双击该选项第一行添加/usr/include/libxml2 此步骤为添加头文件
把HTML解析开源代码加入工程
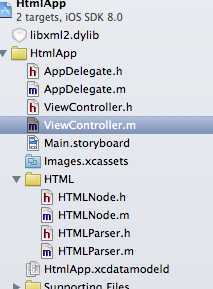
在我们解析HTML的那个类中添加开源代码头文件

开始解析
NSString *str = [NSString stringWithContentsOfURL:[NSURL URLWithString:@"http://dict.youdao.com/search?le=eng&q=success&keyfrom=dict.top"] encoding:NSUTF8StringEncoding error:nil];//把这个网址的内容以UTF-8编码保存在字符串中 NSError *error; if (error)//一旦出错,程序自动返回 { return; } HTMLParser *parser = [[HTMLParser alloc]initWithString:str error:&error];//定义一个解析HTML工具的对象,来使用开源代码 HTMLNode *node = [parser body];//确定程序最大的那个body节点,选出这个节点,再在body节点中找我们要的数据 NSArray *keyword = [node findChildrenWithAttribute:@"class" matchingName:@"keyword" allowPartial:YES]; //定位单词的位置在node节点中keybode下面, for (HTMLNode *a in keyword) { NSLog(@"%@",[a contents]);//把keyboard内容依次打印输出 } NSArray *fanyi = [node findChildrenWithAttribute:@"class" matchingName:@"trans-container" allowPartial:YES]; HTMLNode *ul = [fanyi[0] findChildTag:@"ul"]; HTMLNode *li = [ul findChildTag:@"li"]; NSLog(@"%@",[li contents]); HTMLNode *ol = [node findChildWithAttribute:@"class" matchingName:@"ol wordGroup" allowPartial:YES]; NSArray *word = [ol findChildrenOfClass:@"wordGroup"]; NSLog(@"%@",word); for (HTMLNode *b in word) { HTMLNode *span = [b findChildTag:@"span"]; NSLog(@"%@",[span contents]);
}
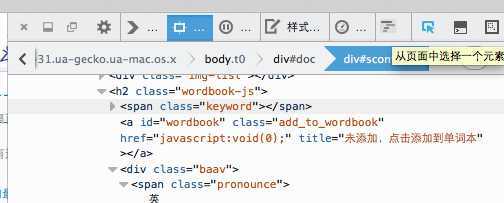
在火狐浏览器中打开需要解析的网页,查看当前网页元素,节点一目了然
标签:style blog http color 使用 文件 数据 for
原文地址:http://www.cnblogs.com/yang-sir/p/3918738.html