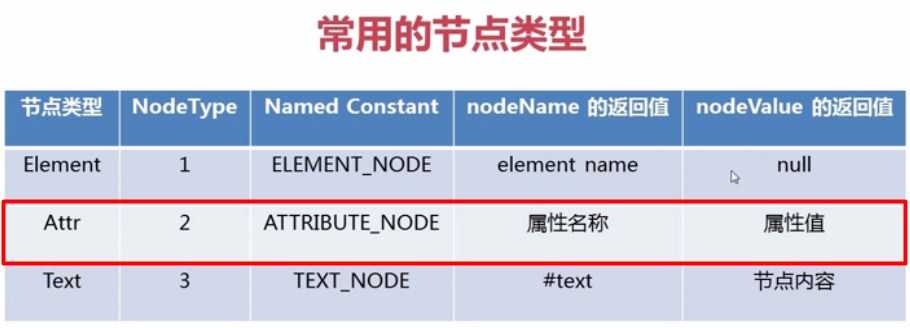
标签:赋值 dev name 返回 length ring system java dom4j
<?xml version="1.0" encoding="UTF-8" ?><bookstore><book type="fiction" id="1"><name>冰与火之歌</name><author>乔治马丁</author><year>2014</year><price>89</price></book><book id="2"><name>安徒生童话</name><year>2004</year><price>77</price><language>English</language></book></bookstore>
public class DomTest {public static void main(String[] args) {//(1)创建DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();try {//(2)创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//(3)通过DocumentBuilder对象的parse方法加载book.xmlDocument document = db.parse("books.xml");- } catch (ParserConfigurationException e) {
e.printStackTrace();} catch (SAXException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}- }
}
public class DomTest {public static void main(String[] args) {//创建DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();try {//创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//通过DocumentBuilder对象的parse方法加载book.xmlDocument document = db.parse("books.xml");//(1)获取所有book节点的集合NodeList booklist = document.getElementsByTagName("book");System.out.println("共有" + booklist.getLength() + "本书");System.out.println("-------------------------------------");//(2)遍历每个book节点for (int i = 0; i < booklist.getLength(); i++) {//(3)通过item(i)获取book节点,nodelist索引从0开始Node book = booklist.item(i);//(4)获取book节点的所有属性集合NamedNodeMap attrs = book.getAttributes();//获取属性的数量System.out.println("第" + (i + 1) + "本书有" + attrs.getLength() + "个属性");System.out.print("分别是:");//(5)遍历book的属性for (int j = 0; j < attrs.getLength(); j++) {//(6)获取属性Node att = attrs.item(j);//(6)获取属性的名称String attName = att.getNodeName();System.out.print(attName + ", ");}System.out.println();System.out.println("-------------------------------------");}} catch (ParserConfigurationException e) {e.printStackTrace();} catch (SAXException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
共有2本书-------------------------------------第1本书有2个属性分别是:id, type,-------------------------------------第2本书有1个属性分别是:id,-------------------------------------
public class DomTest {public static void main(String[] args) {//创建DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();try {//创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//通过DocumentBuilder对象的parse方法加载book.xmlDocument document = db.parse("books.xml");//获取所有book节点的集合NodeList booklist = document.getElementsByTagName("book");System.out.println("共有" + booklist.getLength() + "本书");System.out.println("-------------------------------------");//遍历每个book节点for (int i = 0; i < booklist.getLength(); i++) {//通过item(i)获取book节点,nodelist索引从0开始Node book = booklist.item(i);//获取book节点的所有属性集合NamedNodeMap attrs = book.getAttributes();//获取属性的数量System.out.println("第" + (i + 1) + "本书有" + attrs.getLength() + "个属性");System.out.print("分别是:");//遍历book的属性for (int j = 0; j < attrs.getLength(); j++) {//获取属性Node att = attrs.item(j);//获取属性的名称String attName = att.getNodeName();System.out.print(attName + ", ");}System.out.println();System.out.println("子节点:");//(1)解析book节点的子节点NodeList bookChildNodes = book.getChildNodes();//(2)遍历bookChildNodes获取每个子节点for (int k = 0; k < bookChildNodes.getLength(); k++) {//(3)获取子节点Node bookChild = bookChildNodes.item(k);//注(a)//区分text类型的node以及element类型的node(子节点含我们不需要的文本型,所以我们要筛选)if (bookChild.getNodeType() == Node.ELEMENT_NODE) {//注(b)//(4)获取和输出节点名和节点内容//方法1:System.out.println(bookChild.getNodeName() + ", " + bookChild.getTextContent());//方法2://System.out.println(bookChild.getNodeName() + ", " + bookChild.getFirstChild().getNodeValue());}}System.out.println("-------------------------------------");}} catch (ParserConfigurationException e) {e.printStackTrace();} catch (SAXException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
共有2本书-------------------------------------第1本书有2个属性分别是:id, type,子节点:name, test冰与火之歌author, 乔治马丁year, 2014price, 89-------------------------------------第2本书有1个属性分别是:id,子节点:name, 安徒生童话year, 2004price, 77language, English-------------------------------------

<bookstroe><book id="1"><name>冰与火之歌</name><author>乔治马丁</author><year>2014</year><price>89</price></book></bookstroe
<bookstroe><book id="1"><name>冰与火之歌</name><author>乔治马丁</author><year>2014</year><price>89</price></book></bookstroe>
标签:赋值 dev name 返回 length ring system java dom4j
原文地址:http://www.cnblogs.com/deng-cc/p/6189669.html