标签:lib 存储引擎 命令 返回 git 数据文件 技术分享 磁盘 瓶颈
mongodb 现在有两款存储引擎 MMAPv1 和 WireTiger,当然了除了这两款存储引擎还有其他的存储引擎了。
如:
MMAPv1
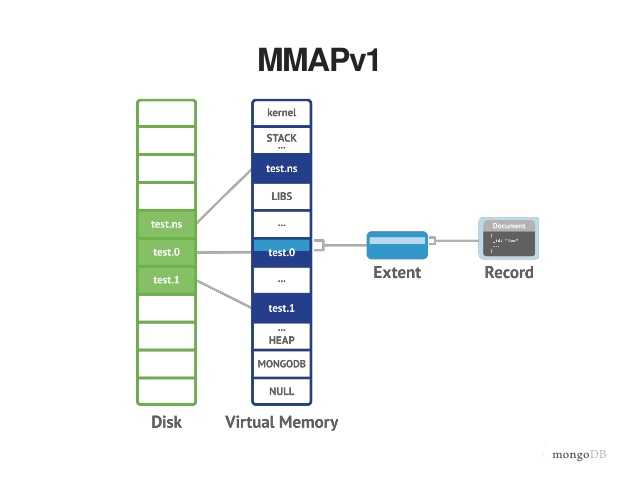
MMAPv1之所以被命名,是因为Linux 中的命令mmap() 这个命令的意思是映射文件到虚拟内存并且允许对一些用例进行单个的优化,例如,当你有一个大的文件,但是你不需要去读整个文件,你只需要读取器中的一部分,mmap()是十分快的比一个read(),因为read() 是把整个文件读到内存中。
MMAP1有一个collection级别的锁,但是没有document 级别的锁,这就造成不能同时有两个进程对同一个collection 进行写的操作。因此,针对同一个collection的写操作,必须要等到前一个操作完成才能进行下一个写的操作。MMAP这个collection 级别的锁事必要的,因为MMAP的索引涉及多个document ,如果这些索引不能同时的被更新,那么这些索引将是不稳定的。
WiredTiger
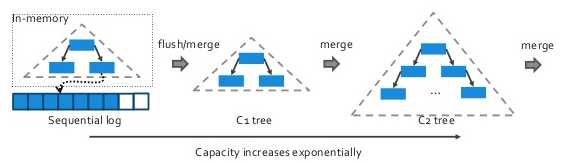
MMAP使用B-tree树去存储索引,WiredTiger也使用B-trees ,但是支持LSM树image above was adapted from here)。
LSM 树针对需要去有大量的随机的插入的工作负载的,当你的数据比cahce的容量大并且后台的维护经费在可以接受的范围的的情况是有利的。
在WiredTiger引擎中,如果一个元素的document 需要被更新,一整个新的document将被全部写到磁盘中,并且把这个旧的document移除。
WiredTiger 提供了document-level-concurrency,这意味着两个写的操作将不影响相同的document,如果影响,一个操作将被返回重新执行。如果返回执行是十分少的那么这个是一个非常不错的性能优化。
还有一个WiredTiger特有的,提供了一个在文件系统中压缩数据和索引的功能,他支持快压和zlib 两种运算,默认情况下是有用快压,和zlib相比他是用了少量的cpu但是它有低 的压缩效率。
Benchmarks
当WiredTiger为mongodb服务的时候,他被公布在写操作方面,性能将比之前快7-10 倍,并且压缩了80%的文件系统,这是一个大的改善,下面是多线程的吞吐量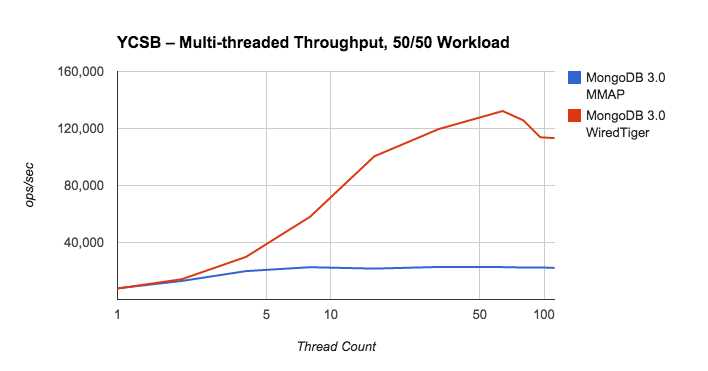
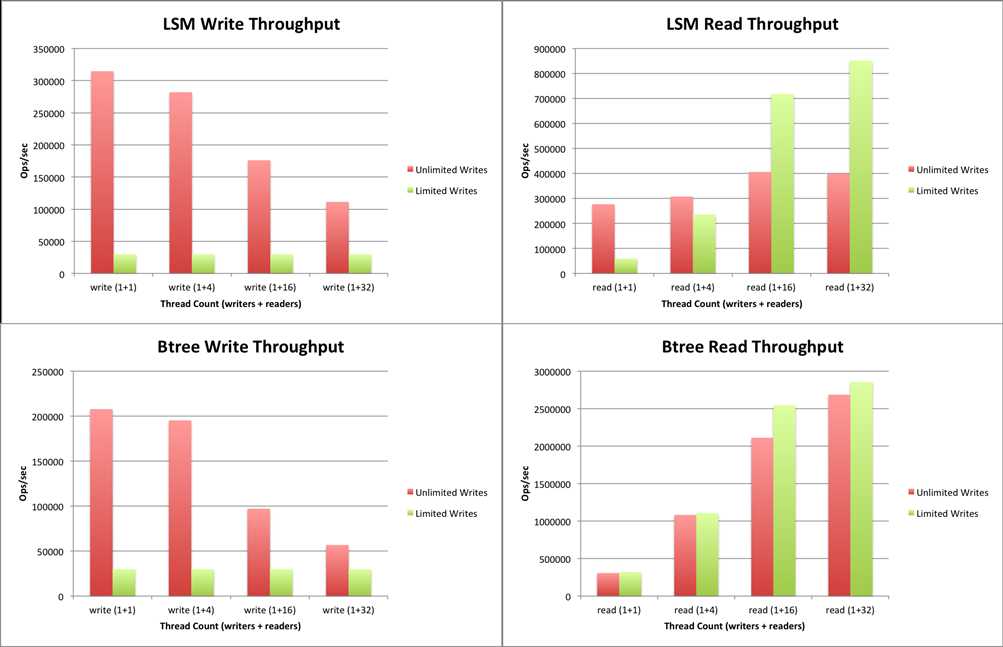
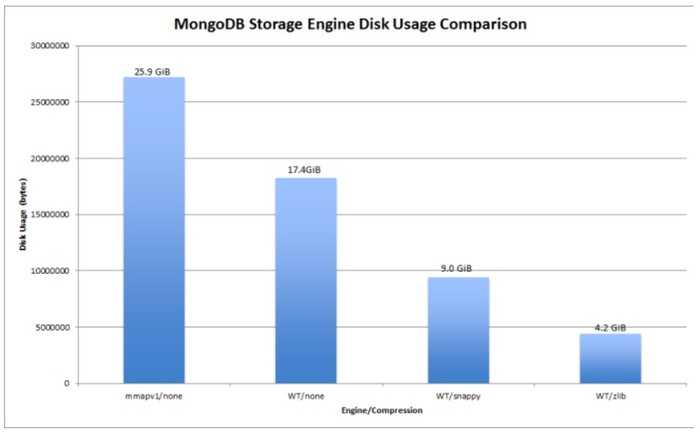
Conclusion
如果你的app是读的权重大,使用MMAP,如果写的大,使用WiredTiger。
一个有趣的问题是可以建立一个混合引擎的复制集。在复制集中,你可以给一个node配置WiredTiger去接受一个大量写的数据负载,再用另外一个node 配置MMAP引擎去被一些读数据的服务使用,复制集会自动主库和其他库之间的数据,她们基础的存储引擎是独立的。
如果你的数据文件使用MMAP引擎创建的,你将需要创建一个新的数据库,如果你需要用一个WiredTirger node去运行,他不能打开数据文件,这倒转过来是一样的,虽然她们使用了不同的方法存储数据,你不能重新使用相同的文件,但是在复制集中,数据和主库进行交换是没有问题的
[mongodb] MMAP 和wiredTiger 的比较
标签:lib 存储引擎 命令 返回 git 数据文件 技术分享 磁盘 瓶颈
原文地址:http://www.cnblogs.com/Kellana/p/6195890.html