标签:size think val 需要 好的 还需要 creat 也有 命名
环境:Windows
最近用Caffe跑了一下AlxNet网络,现在总结一下数据处理部分:(处理过的数据打包链接:http://pan.baidu.com/s/1sl8M5ad 密码:ph1y)
(1)获得数据集,途径有:
1.Benchmark(数据库) AFLW FDDB
2.最新论文(2016)
3.Thinkface论坛
数据量:庞大的数据量支撑,最少1w张(正,负样本各一万张),格式如下:
xxxx.jpg x1,y1,x2,y2(标注label),即人脸所在矩形框的坐标
xxxx.jpg x1,y1,w,h
我是从Thinkface论坛上直接下载的经过裁剪的人脸数据;
(2)利用下载下来的数据集制作正负样本以及.txt文件:
以下是我的方法,可能有点笨拙:
1.先建立imageset_2文件夹作为总的工程文件夹,然后在其中新建两个文件夹,一个命名为0,一个命名为1,分别放入裁剪好的人脸数据和非人脸数据,再对图片进行重命名(人脸图片命名为face_xxxx,非人脸图片命名为non_face_xxxx);
2.再新建mix、val、train文件夹(train文件夹中再新建两个文件夹,一个命名为0,一个命名为1),编写一个python小程序,将0和1中的图片经过混合后放入mix文件夹,在mix文件中取10%放入val文件夹作为测试数据,再取剩下的90%将其中的人脸图片放入train文件夹中的0文件夹,非人脸图片放入1文件夹(正样本5800张,负样本20000张左右);
3.先制作train.txt,在train中的0文件夹中写一个.bat文件,内容如下:
dir /b/s/p/w *.jpg > train_0.txt
上述命令在新建的train_0.txt文件写入0中的每张图片的绝对路径,然后再使用txt的替换功能去掉绝对路径,再在后面加上Label值,形式如下:
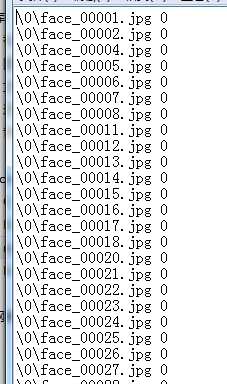
对于1也如上进行操作,得到的train_1.txt中的内容如下:
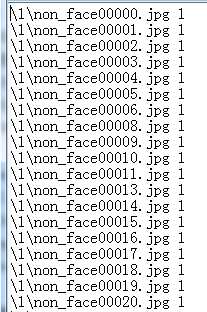
然后再将两个文件中的内容整合到train.txt文件中,就得到了我们需要的train.txt文件;
对于val.txt文件我们也进行类似操作,不过我们也要先将val文件夹中的图片分到0和1两个文件夹(因为val里既有人脸图片也有非人脸图片,无法使用替换功能),然后制作val.txt文件;
(3)将正负样本转换为lmdb格式:
在Windows下调用caffe安装根目录下BUild->x64->Debug中有一个convert_imageset.exe文件来制作lmdb文件(有的人有可能只有.cpp,那么就还需要经过VS的编译生成.exe)
在Linux下则调用examples->imagenet中的create_imagenet.sh文件,并进行改写(参见网上相关博客)
这里我介绍的是如何在windows下转换lmdb格式(要自己写.bat文件,满满的泪。。。。)
首先在Imageset_2文件夹中写一个create_imageset_2.bat文件,内容如下:

然后执行就会在后面相应的路径中创建lmdb文件;
(4)图像预处理
使用Build中的compute_image_mean.exe将图像减去均值,.bat文件内容如下:

得到对应的.binaryproto文件
(5)修改solver.prototxt和train.prototxt文件
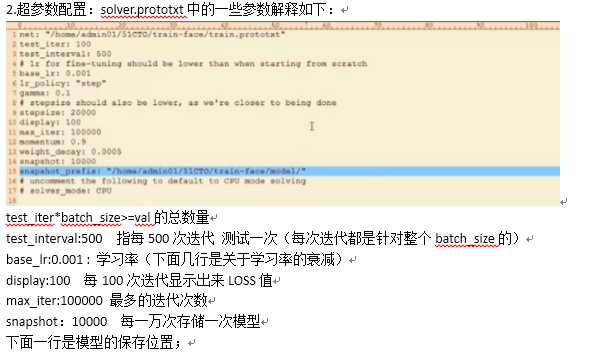
简单一点,我们只需要修改其中的路径即可(注意,路径用\\或者/,千万不要用\!!!!!!!!)
用CPU的话,solver:CPU,GPU的话相应修改即可。
(6)训练网络:
编写train.bat文件开始训练,内容如下:

双击就开始训练了:
配置:i7,8G,CPU训练,已经一天了还没好,强烈建议GPU!!!!
标签:size think val 需要 好的 还需要 creat 也有 命名
原文地址:http://www.cnblogs.com/zf-blog/p/6196882.html