标签:目录 xxxx direct card 高效 http sql语句 数据 核心
打开百度输入 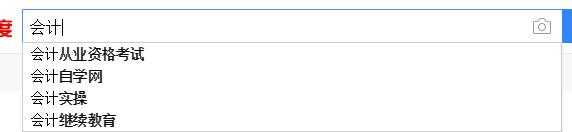
站内搜索也要实现类似功能。最基础的做法,写个方法查数据库搜索历史综合表keywordSearch(先将被搜索过的关键字记录到一张表,记录好他们被搜索的次数、上次搜索的有多少结果)
大概一条sql语句:select keyword,searchCount,xxxx from table where keyword like ‘会计%‘
当表 keywordSearch 记录很有几百上千万的时候,like显然不能及时响应了。但是这种关键字联想的一旦有延迟返回,那是很不好的体验。还没等你返回一次联想结果,用户早就自己输完了。。。。。那还联想个球。
然后这个时候,想到的是用lucene.net
二话不说开干。很快实现了demo,创建了索引2g,搜索核心代码如下:(渣渣代码,勿喷)

测试之,大概在1秒内能返回结果,但是还是不够快,有明显的延迟感。
尼玛。。。。。想不到好办法解决,然后试了试用RAMDirectory ,还是不行,毕竟 RAMDirectory 只是将索引一次性读到内存,避免了一个预热的过程,所以瓶颈感觉应该出在了这个WildcardQuery上(谁知道lucene.net要实现这种查询,还有其他办法效率高吗?看到的有知道的请评论告诉我谢谢。)。
当时想的是,看样子只能丢掉一些关键字,比如只汇总最近一年的关键字,把索引搞小一些。
but,周末休息了一下,让我想到了一个办法。
既然要减少单个索引体积,那我为什么不拆分索引?
首先,创建索引的时候,根据关键字的第一个汉字的首字母,来决定放在哪个索引。比如 “会计学” 放在 D:\LuceneIndex\Searchkeyword\k\ 目录下的索引,"管理学"放在 D:\LuceneIndex\Searchkeyword\k\ 目录。
然后检索的时候我也根据用户输入的关键字,检索不同的目录。这样应该就能解决这个问题。
说干就干,又开始改代码。
因为代码篇幅比较大,我就贴一点核心部分。(再次请求原谅我的渣渣代码。。。。)
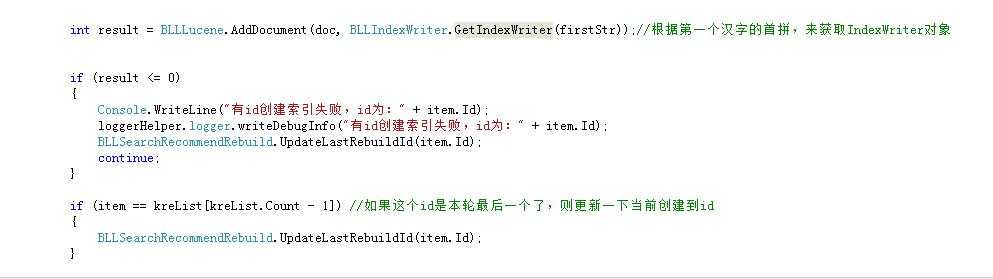
那个 GetIndexWriter 方法,就是根据汉字首拼字母来获取的,
BLLIndexWriter类里面 用 Dictionary<string, string> 对象,来装所有字母和它对应的索引路径。
然后用了一个 Dictionary<string, IndexWriter> 对象,来装所有字母,和它所对应的 IndexWriter 对象。
当索引全部创建完毕以后,遍历了装所有 IndexWriter 的对象,然后一个个关闭并优化。
最后,索引就一一对应到不同目录了
见图,原来的索引和现在的索引。
平均分了这么多以后,搜索基本上是马上就出结果了。因为每一个都只有几十MB一百MB的。这点量,lucene的通配还是能搞的定的。
对于此类查询,数据库上分表,然后like也可以。只要你愿意用数据库搞的话。
不过谁还知道,有没有什么更好的办法解决这个问题?
记录到这里。渣渣代码不上传了,如果有谁刚好需要写这样的功能,又实在写不出来代码的内线我,我发一份给你。。。。。
利用 lucene.net 实现高效率的 WildcardQuery ,记一次类似百度搜索下拉关键字联想功能的实现。
标签:目录 xxxx direct card 高效 http sql语句 数据 核心
原文地址:http://www.cnblogs.com/Jerseyblog/p/6197096.html