标签:index.php 输入 平均值 png details strong size 编号 生成
Ref: 从LeNet-5看卷积神经网络CNNs
关于这篇论文的一些博文的QAC:
MLP(Multilayer Perceptron,多层感知器)是一种前向神经网络(如下图所示),相邻两层网络之间全连接。
sigmoid通常使用tanh函数和logistic函数。
1998年Yann LeCun在论文“Gradient-Based Learning Applied to Document Recognition”中提出了LeNet-5,并在字母识别中取得了很好的效果。LeNet-5的结构如下图所示:


下面开始对各层进行具体分析。
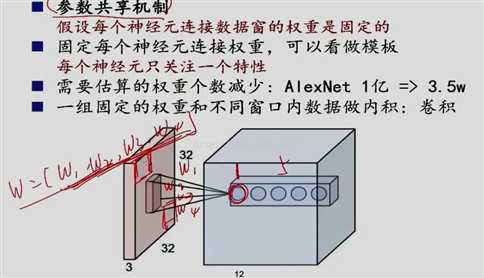
C1/C3/C5这三层都用了卷积操作,学过数字图像处理的同学一定对这种图像上的卷积很熟悉,本质上是用一块权重模板在图像上的各个区域做加权求和,如下图所示:

图中黄色的3*3 卷积核从图像的左上角开始向右或向下移动,对移动过程中覆盖的区域求加权和。最后得到(5-3+1)*(5-3+1)大小的卷积结果,称为一个feature map。
C1: LeNet-5的C1层用6个 5*5卷积核对输入的32*32图像进行卷积,每个卷积核对应生成一个(32-5+1)*(32-5+1)的feature map,共计6个feature map。
C3: C3的过程稍为复杂,C3总共生成了16个feature map,每个feature map按照Table1选择输入。例如C3编号为0的feature map是由S2中编号为0、1、2的feature map 生成的。先由3个卷积核分别在S2的0、1、2 feature map上生成3个临时feature map,然后把这三个临时feature map相加得到C3的feature map 0。这样构造C3 有两个好处:一是相比于全连接,可以减少参数的数量;二是每个feature map的输入都不相同,可以达到互补的效果。
C5: C5层用全连接的方式,每个feature map都是由S4中所有的feature map卷积结果求和得到的。由于S4的feature map大小是5*5,卷积核大小也是5*5,所以卷积后得到的是一个1*1的矩阵。
另外,C1/C3/C5每个feature map计算结果都会在计算结尾加上一个偏置。
池化的作用主要有两个:一是减少参数数量;二是在使模型具有较好的平移不变性。
和卷积很类似,不同之处在于卷积核覆盖的区域是重叠的,而池化的各个区域是没有重叠的。所以当S2/S4用2*2的池化模板后,feature map的宽和高都减小为原来的一半。
再借用一下UFLDL Tutorial关于池化的示意图:

output层/F6层都是与前一层全连接,C5-F6-output整体结构可以看成一个多层感知器。
所以LeNet-5其实是由三种不同的结构组成的:卷积、池化、多层感知器。而使用这三种结构也就可以构成大部分卷积神经网络了。
目前几乎所有公开发表的卷积模型都使用全连接结构,即某一层(第m层)的feature map是由上一层(第m-1层)的所有feature map卷积后求和得到的。但是在实际使用中需要注意模型的参数个数,参数个数的增加对计算量的影响很大。
目前常用的是平均池化或者最大池化,即把上一层feature map的各个池化区域内的单元值求平均值或最大值。
可以把最后一层的结果输出到某个分类器(如Logistic Regression等)进行分类。
[1]Yann LeCun, Gradient-Based Learning Applied to Document Recognition, 1998
[2]Theano Deeplearning Tutorial
[3]Stanford UFLDL Tutorial: http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B
(1) 卷积核是学习得来,还是预定义好的?
整个网络的训练,主要就是为了学那个卷积核啊。
(2) 有哪些参数?
卷积核的参数就是神经网络的输入层。
[OpenCV] Convolutional Neural Network
标签:index.php 输入 平均值 png details strong size 编号 生成
原文地址:http://www.cnblogs.com/jesse123/p/6201301.html