标签:等等 步骤 ural recover start tle ica 数据库实例 数据库名
只有3台服务器,开始搭建mongodb集群里主要参照的是http://www.lanceyan.com/tech/arch/mongodb_shard1.html,端口的设置也是mongos为 20000, config server 为 21000, shard1为 22001 , shard2为22002, shard3为22003。其大体思路为:
在每台服务器上启动config服务
在每台服务器上启动mongos服务,并指定每个mongos服务包含的config服务地址(前一步启动的3个config服务)https://docs.mongodb.com/manual/reference/program/mongos/#cmdoption--configdb
每台服务器上,为每个分片或其复本启动mongod实例https://docs.mongodb.com/manual/tutorial/deploy-replica-set/#start-each-member-of-the-replica-set-with-the-appropriate-options
登录任意一台服务器,配置每个分片的复本集包含的实例https://docs.mongodb.com/manual/reference/method/rs.initiate/#example
登录mongos,在mongos服务中添加启动好的分片https://docs.mongodb.com/manual/reference/command/addShard/#definition
最后在数据库层面和数据集层面开启分片功能。
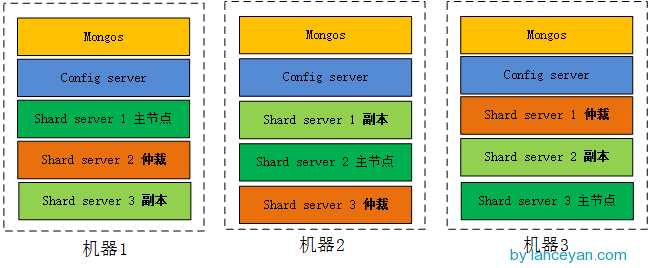
经过上述几个步骤,就搭出了下图的集群。(图片来自http://www.lanceyan.com/tech/arch/mongodb_shard1.html)
mongod --configsvr 把该mongod实例启动为某个分片集的config Server。这样一来,只能通过admin或config来向数据库写数据?
mongod --fork 把mongod实例启动为后台进程
mongod --dbpath 指定实例的目录
mongod --logpath 指定实例的日志路径
mongod --shardsrv 把该实例启动为【分片集】的一个【分片】
mongod --replSet 该实例为【复本集】的一个实例
mongod --oplogSize 配置local数据库中oplog.rs集合的大小(单位M)。实例同步时,在多个实例之间进行同步时,oplog.rs集合用来存储数据库的改变。一旦建立该表大小就固定了,填满后如果又来了新的更改,后来的修改就覆盖前面的。由于在装集群时开始设置太小,后面插入操作又特别多,导致多实例同步跟不上oplog.rs表覆写的速度,造成too stale to 更新的错误。后面有更改oplig.rs大小的过程。
mongod --port 指定该实例启动的端口号
mongos mongos是为分片的mogodb集群作为路由服务的,说白了就是来了一个操作,我给你指定你到哪个分片上去执行。
mongos --configdb 指定分片集的config servers
mongos --dbpath 同上
mongos --logpath 同上
mongos --port 同上
mongos --fork 同上
mongod --configsvr --dbpath /data/dbmongo/config/data --port 21000 --logpath /data/dbmongo/config/log/config.log --fork
mongos --configdb ip1:21000,ip2:21000,ip3:21000 --port 20000 --logpath /data/dbmongo/mongos/log/mongos.log --fork
mongod --shardsvr --replSet shard1 --port 22001 --dbpath /data/dbmongo/shard1/data --logpath /data/dbmongo/shard1/log/shard1.log --fork --oplogSize 10240 mongod --shardsvr --replSet shard2 --port 22002 --dbpath /data/dbmongo/shard2/data --logpath /data/dbmongo/shard2/log/shard2.log --fork --oplogSize 10240 mongod --shardsvr --replSet shard3 --port 22003 --dbpath /data/dbmongo/shard3/data --logpath /data/dbmongo/shard3/log/shard3.log --fork --oplogSize 10240
mongo 127.0.0.1:22001 use admin config = { _id:"复本名字", members:[ {_id:0,host:"ip1:22001",arbiterOnly:true}, {_id:1,host:"ip2:22001"}, {_id:2,host:"ip3:22001"} ] } rs.initiate(config);
mongo 127.0.0.1:20000 use admin db.runCommand( { addshard : "shard1/ip1:22001,ip2:22001,ip3:22001"}); db.runCommand( { addshard : "shard2/ip1:22002,ip2:22002,ip3:22002"}); db.runCommand( { addshard : "shard3/ip1:22003,ip2:22003,ip3:22003"});
db.runCommand( { enablesharding :"数据库名"});
db.runCommand( { shardcollection : "数据库名.集合名",key : {_id: 1} } )
oplogSize是设置的local数据库里的oplog.rs集合的大小,如果启动时oplogSize设置太小,一旦建立就不能再增大了。复本数据库一旦down掉一段时间,主数据库有可能把oplog.rs表填满之后又来了新的修改把表覆盖了,那么复本数据库再启起来就会一直处于Recovering状态,日志里提示too stale to catch up。这个时候可以:
1。把复本数据库全清掉,重新启动复本数据库实例,这样复本数据库会初始把主数据库里的数据全拷贝一遍。
2。把复本数据库全清掉,从主数据库里复制好data放过来并重启。(没试过)
3。在线的修改oplogSize的值,原理就是把数据库关掉后,启动成单实例的模式,然后删掉oplog.rs并重新建一个更大的oplog.rs。这个官方文档里有说明:Change the Size of the Oplog?
rs.stepDown()
use admin
db.shutdownServer()
mongod --port 22004 --dbpath /data/dbmongo/shard2/data --logpath /data/dbmongo/shard2/log/shard2.log --fork
mongodump --db local --collection ‘oplog.rs‘ --port 22004
use local db = db.getSiblingDB(‘local‘) db.temp.drop() db.temp.save( db.oplog.rs.find( { }, { ts: 1, h: 1 } ).sort( {$natural : -1} ).limit(1).next() ) db.oplog.rs.drop() db.runCommand( { create: "oplog.rs", capped: true, siz10 * 1024 * 1024 * 1024) } ) db.oplog.rs.save( db.temp.findOne() )
use admin db.shutdownServer() mongod --shardsvr --replSet shard2 --port 22002 --dbpath /data/dbmongo/shard2/data --logpath /data/dbmongo/shard2/log/shard2.log --fork
这个很有可能是由于unix系统对程序的资源使用限制造成的,具体可以参见文档:UNIX ulimit Settings?
修改方法为修改/etc/security/limits.d/99-mongodb-nproc.conf
# Default limit for number of user’s processes to prevent # accidental fork bombs. # See rhbz #432903 for reasoning. # # * soft nproc 4096 # root soft nproc unlimited * soft nofile 64000 * hard nofile 64000 * soft fsize unlimited * hard fsize unlimited * soft cpu unlimited * hard cpu unlimited * soft nproc 64000 * hard nproc 64000
另外还有尽量不以root用户开启mongod实例等等,具体修改忘记了,大体是这样
http://www.lanceyan.com/tech/arch/mongodb_shard1.html
http://www.cnblogs.com/wilber2013/p/4154406.html
标签:等等 步骤 ural recover start tle ica 数据库实例 数据库名
原文地址:http://www.cnblogs.com/yuantf/p/6203532.html