标签:开始 pytho 通过 16px import alt method http epc
相较于java,Python里的文件操作简单了很多
python 获取当前文件所在的文件夹:
os.path.dirname(__file__)
写了一个工具类,用来在当前文件夹下生成文件,这样方便
class Util(): """工具类""" @classmethod def get_file_url(cls, file_name): """获取当前文件夹的路径""" return os.path.join(os.path.dirname(__file__), file_name)
向一个文件中写数据,w表示write,用于写入
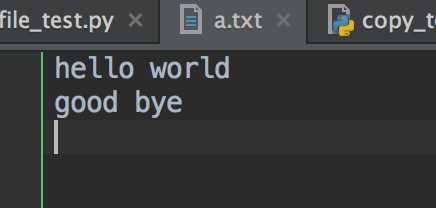
myfile = open("a.txt", "w") myfile.write("hello2 world \n") myfile.write("good bye \n")
打开文件查看内容为
写完文件后如果不在操作文件,记得关闭文件,养成好习惯。
myfile.close()
一般文件的读取都是放在try-except块中的,其中文件的关闭放在finally 中,这样能保证文件始终是关闭的。
读取文件
myfile = open(Util.get_file_url("a.txt"),‘r‘) print "第一行",myfile.readline() # 读取第一行 print "第二行",myfile.readline() # 读取第二行 print "所有行",myfile.read()
readline()方法一次读取文件中的一行,由于文件只有2行,所以执行2次readline()后没有再可以读的数据了,read()方法会将文件的所有内容读入一个字符串。如果要讲文件指针重置
到最开始的位置,可以使用如下方法
myfile.seek(0) # 将文件重置到最开始的地方
read() 方法可以指定读取的字节大小,如read(6)
myfile = open(Util.get_file_url("aaa.xxx"),‘r‘) new_str = myfile.read(6) # aaa.xxx的内容为"你好",读取6个字节则可以刚好将字符串读出来,一个中文3个字节
使用迭代器读取文件
iterator = open(Util.get_file_url("aaa.xxx"),‘r‘) for line in iterator: print line
读取文件到字符串列表
lines = myfile.readlines() # 将文件的每一行作为一个元素存入列表中
class Person(object): def __init__(self, name=‘‘, age=0): self.age = age self.name = name def __str__(self): return self.name+" -- "+str(self.age) p = Person(‘zhangsan‘, 24) p.sex = ‘男‘ p.salary = 12000 # 将对象存入文件 to_file = open(Util.get_file_url("aaa.txt"),‘wb‘) pickle.dump(p, to_file) to_file.close() print p.name # 将存入文件中的对象load进来 from_file = open(Util.get_file_url("aaa.txt"),‘rb‘) # rb 表示读取二进制文件 person = pickle.load(from_file) print person
元组的存在组要是为列表提供完整性,元组具有不可变性,可以确保在程序中不会被另一个引用修改。它类似于其他语言中的常数。
元组的在python中属于tuple 类型常见的操作:
# 元组定义 tuple1 = () # 空的元组 tuple2 = (1,) # 包含1个元素的元组 int1 = (1) # 包含一个元素的变量 tuple4 = (1, 2, 3, 4,2) # 遍历元组 for tup in tuple4: print tup print ‘*‘ * 55 # 获取指定下标的元素 print tuple4[2] # 获取指定数的下标 print tuple4.index(4) # 获取指定值出现的次数 print tuple4.count(2) print tuple4[1:3] # 含左不含右
python中一切皆为对象,赋值只是拷贝了引用。举个例子:
>>> list1=[1,2,3,4] >>> print list1 [1, 2, 3, 4] >>> x = list1 >>> print x [1, 2, 3, 4] >>> list1[1]=‘abc‘ >>> print list1 [1, ‘abc‘, 3, 4] >>> print x [1, ‘abc‘, 3, 4]
如果有其他面向对象编程的经验就不难理解,那么如何将list1列表完全赋值给x呢,我们可以使用如下的方法
>>> x = list(list1) (也可以 x = list1[:]) >>> print x [1, ‘abc‘, 3, 4] >>> list1[1]=2 >>> print list1 [1, 2, 3, 4] >>> print x [1, ‘abc‘, 3, 4]
对于dict 类型,可以使用如下的方式,这样就实现了完整的拷贝
>>> dict1 = {"a":1,"b":2}
>>> dict2 = dict1.copy()
注意:通过 copy 和 list() 或list1[:]的方式生成的只是顶层拷贝,并不能赋值嵌套的数据。举个例子:
>>> L = [1, 2, 3] >>> dict1 = {"list": L} >>> tuple5 = (dict1.copy(),) >>> print tuple5 ({‘list‘: [1, 2, 3]},) >>> L[0] = "a" >>> print L [‘a‘, 2, 3] >>> print tuple5 ({‘list‘: [‘a‘, 2, 3]},)
如果想要一个深层次的拷贝结果,需要使用如下的方法
import copy res_copy = copy.deepcopy(tuple5) #此方法将会进行深层次拷贝
好了,先写到这吧,算是总结完了
标签:开始 pytho 通过 16px import alt method http epc
原文地址:http://www.cnblogs.com/rilweic/p/6204611.html