标签:.json des sch back return 分享 python爬虫 sources ide
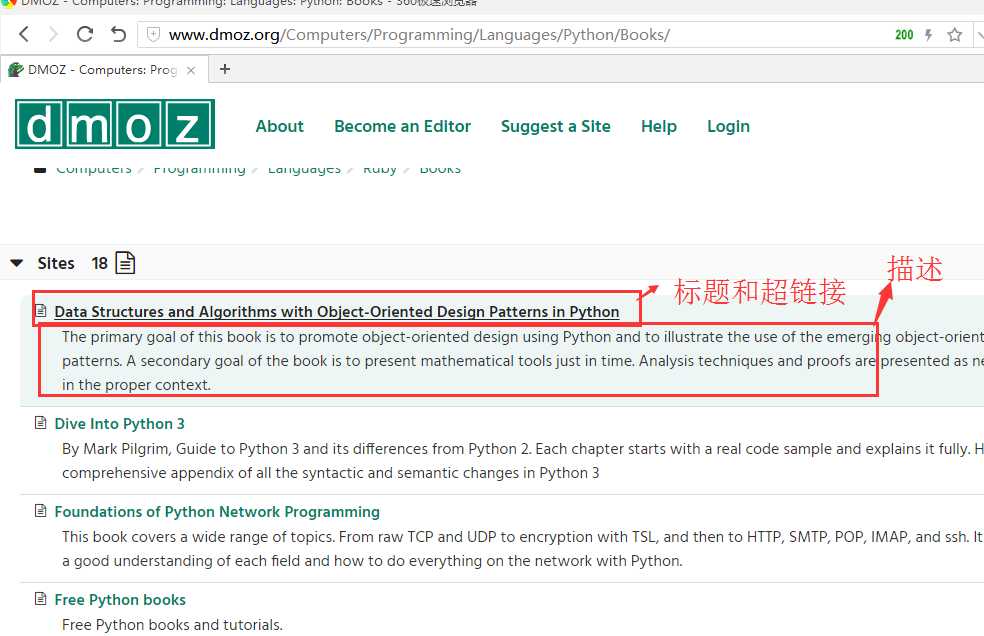
将该导航网站搜索出结果的页面http://www.dmoz.org/Computers/Programming/Languages/Python/Books/里面标题,及标题的超链接和描述爬下来。
使用scrapy抓取一个网站一共需要四个步骤。
---创建一个scrapy项目
---定义item容器
---编写爬虫
---储存内容
1.新建一个项目
scrapy startproject demoscrapy
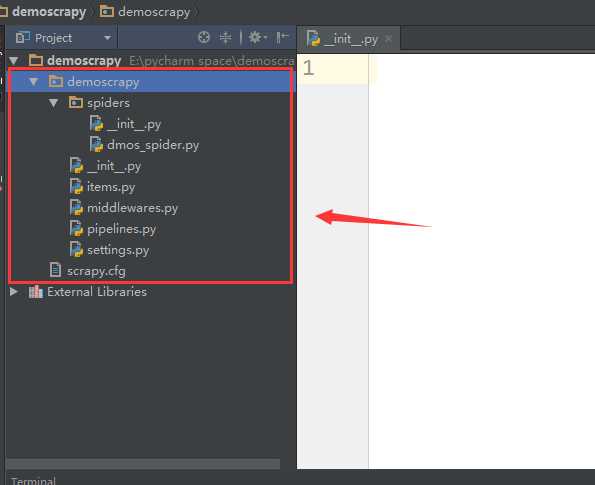
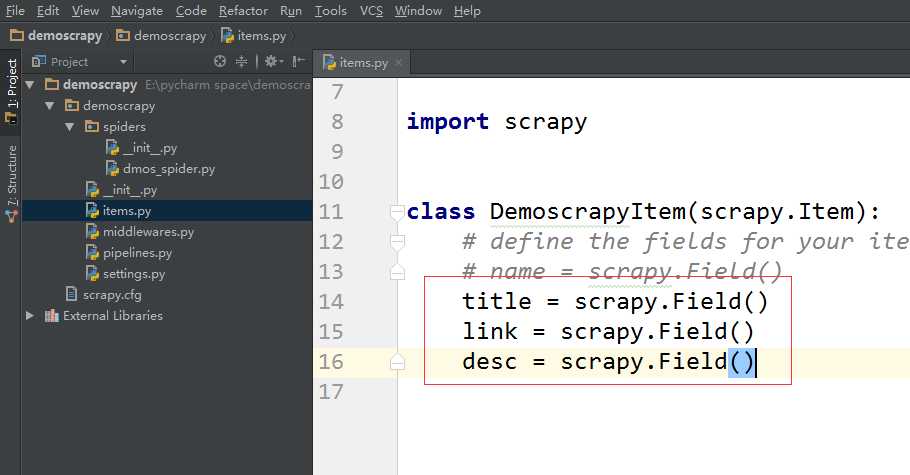
2.定义item容器(定义要爬取的内容)
3.编写爬虫(这里以官网的教程为例子)
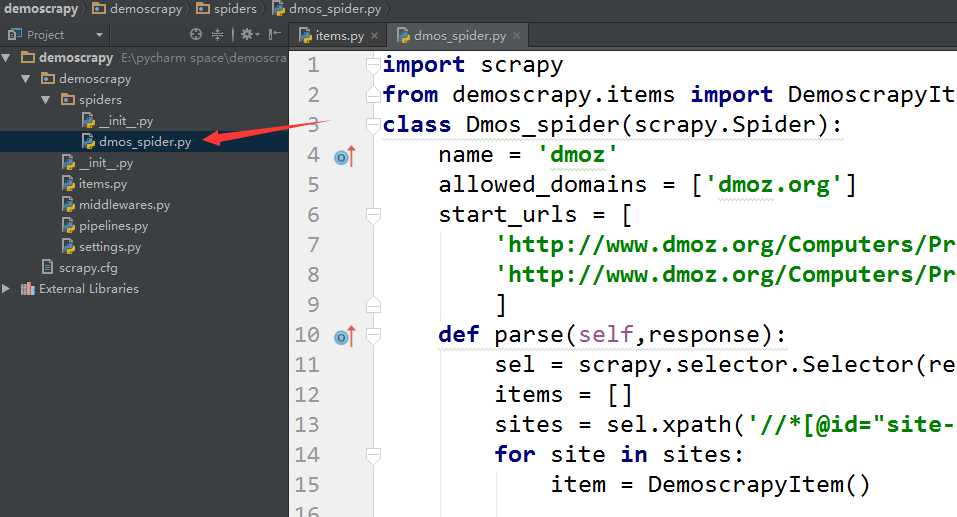
import scrapyclass Dmos_spider(scrapy.Spider):
name = ‘dmoz‘ #爬虫的名字
allowed_domains = [‘dmoz.org‘] #爬虫允许域名范围
start_urls = [
‘http://www.dmoz.org/Computers/Programming/Languages/Python/Books/‘, #爬取的页面
‘http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/‘
]
4.储存内容
import scrapy
from demoscrapy.items import DemoscrapyItem
class Dmos_spider(scrapy.Spider):
name = ‘dmoz‘
allowed_domains = [‘dmoz.org‘]
start_urls = [
‘http://www.dmoz.org/Computers/Programming/Languages/Python/Books/‘,
‘http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/‘
]
def parse(self,response): #处理爬去结果
sel = scrapy.selector.Selector(response)
items = []
sites = sel.xpath(‘//*[@id="site-list-content"]/div/div[3]‘) #通过xpath处理页面节点
for site in sites:
item = DemoscrapyItem()
item[‘title‘] = site.xpath(‘a/div/text()‘).extract()
item[‘link‘] = site.xpath(‘a/@href‘).extract()
item[‘desc‘] = site.xpath(‘div/text()‘).extract()
items.append(item)
return items
scrapy crawl dmoz -o items.json -t json
-o 输出文件 -t 以json格式储存
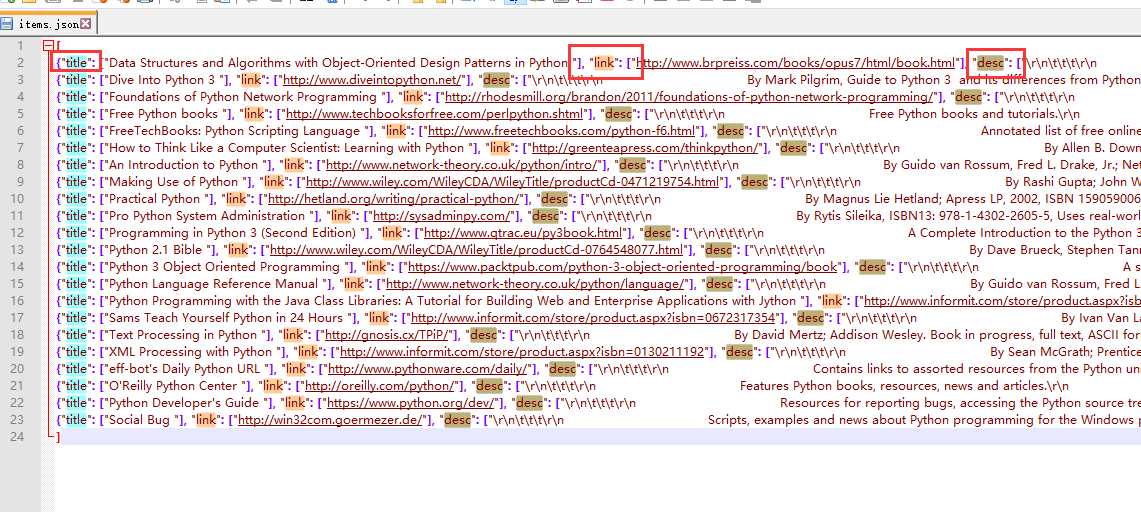
注*在存储的时候,要通过xpath抓取想要的数据。
google浏览器有xpath插件可以安装下。
更详细的xpath教程
http://www.w3school.com.cn/xpath/index.asp
标签:.json des sch back return 分享 python爬虫 sources ide
原文地址:http://www.cnblogs.com/cui0x01/p/6211982.html