标签:实例 求值 优先级 自己的 执行 关系 语言 对象 并且
前面一章我们已经说过C语言存在的一些问题和它晦涩的地方,让我们对这门神奇的语言有了更深的了解。现在这一章则集中精力来讨论C语言的声明,分为三块,首先是说明C语言声明晦涩难懂的原因和声明是如何形成的,其次就是学习怎样对C语言的声明进行分析,另外本文将详细来探讨一个分析C语言声明的工具——cdecl,分析和编写它的源代码。
C语言的声明晦涩难懂这一点应该是名不虚传的,比如说下面这个声明:
void (*signal(int sig, void(*func) (int)))(int);
这可不是吓人的,熟悉C语言的人会发现,这原来就是ANSI C标准中的信号的信号处理函数的函数原型,如果你没有听说过,那么你确实应该好好补补你的C语言了。那么这个函数原型是什么意思呢?后面会说明,在这里提出就是证明在C语言中,的确存在这种晦涩难懂的声明。
为什么在C语言中会存在这种晦涩难懂的声明呢?这里有几个原因。首先,在设计C语言的时候,由于人们对于“类型模型”尚属陌生,而且C语言进化而来的BCPL语言也是无类型语言,所以C语言先天有缺。然后出现了一种C语言设计哲学——要求对象的声明形式与它的使用形式尽可能相似,这种做法的好处是各种不同操作符的优先级在“声明”和“使用”时是一样的。比如说:
声明一个int型变量时:int n;
使用这个int型变量时:n
可以看出声明形式和使用形式非常相似。不过它也有缺点,它的缺点在于操作符的优先级是C语言中另外一个设计不当的地方。也就是说,C语言之前存在的操作符优先级的问题在这里又继续影响它的声明和定义,这就导致程序员需要记住特殊规则才能推测出一些稍微复杂的声明,当然之前也说过,C语言并不是为程序员设计的,它只是为编译器设计的。在C++中,这一点倒是有所改善,比如说int &p;就是声明p是一个只想整形地址的数也就是指针。C语言的声明存在的最大问题是你无法以一种人们所习惯的自然方式从左向右阅读一个声明,在ANSI C引入volatile和const关键字之后,情况就更糟糕了。由于这些关键字只能出现在声明中,这就使得声明形式与使用形式完全对得上号的越来越少了。我相信有很多学习C语言的人都搞不太清楚const与指针之间的声明关系,请看下面的例子:
const int * grape;
int const * grape;
int * const grape;
const int * const grape;
int const * const grape;
怎么样?如果你能正确的分析它们的含义,那么说明你的C语言学得不错,如果你已经晕了,那也不怪你,毕竟这种情况只会在C语言里出现。不过,还是让我们来解决这几个例题,首先我们要明白const关键字,它的名字经常误导人们,导致让人觉得它就是个常量,在这里有个更合适的词适合它,我们把它叫做”只读“,它是个变量,不过你只有读取它的权限,不能对它进行任何修改。我是这么分析这种const声明的:只要const出现在"*"这个符号之前,可能是int const *,也可能是const int *,总之,它出现在”*"之前,那么就说明它指向的对象是只读的。如果它在”*"这个符号之后,也就是说它靠近变量名,那么就说明这个指针是只读的。换句话也可以这么说,如果它出现在"*"之前,说明它修饰的是标识符int或者其他类型名,那么说明这个int的值是只读的,说明它指向的对象是常量;如果它出现在“*"之后,说明它修饰的是变量名grape,那么说明这个指针本身是只读的,说明这个指针为常量。这样再来看上面两个例题就很简单了,第一个和第二个的const均出现在"*"符号之前,而"*"之后没有const变量,那么说明这两个都是常量指针,也就是说指向的int值是只读的;第三个const则出现在"*"之后,而”*"之前没有,说明第三个是一个指针常量,这个指针是只读的;第四个和第五个const出现在“*"之前和之后,就说明它既是指针常量也是常量指针,指针本身和指针所指向的int值都是只读的。
看到这里,相信大家已经对C语言这种晦涩的声明语法有所体会了,这样看来,正常人都不是很喜欢这种晦涩的语法,可能只有编译器才会喜欢了吧!
下面我们来看看声明是如何形成的:
首先要了解的东西叫做声明器——是所有声明的核心。声明器是标识符以及与它组合在一起的任何指针、函数括号、数组下标等。下面我列出一个声明器的组成部分,首先它可以有零个或多个指针,这些指针是否有const或是volatile关键字都没有关系,其次,一个声明器里有且只有一个直接声明器,这个直接声明器可以是只有一个标识符,或者是标识符[下标],或者是标识符(参数),或者是(声明器)。书中给出的表格可能有些困难,所以把它总结下来就是这么一个公式:
声明器 = 直接声明器( 标识符 or 标识符[下标] or 标识符(参数) or (声明器) ) + (零个或多个指针)
这个式子已经相当简洁了,不过早些时候提到过,()操作符在C语言中代表的意思太多了,在这里就体现了出来,它既表示函数,又表示声明器,还表示括号优先级。为了让大家更好的理解,我来举出一些例子给予说明:
有一个直接声明器,并且这个声明器为标识符:n
有一个直接声明器为标识符,还有一个指针: * n
有一个直接声明器为标识符[下标],还有一个指针: * n[10]
有一个直接声明器为标识符(参数): n(int x)
这些声明器看上去跟我们平时的声明很相似,但是好像又不完整,别着急,因为声明器只是声明的一个部分,下面我们来看一条声明的组成部分:C语言中的声明至少由一个类型说明符和一个声明器以及零个或多个其他声明器和一个分号组成。下面我们一一来介绍这每个部分:
首先类型说明符有这些:void、char、short、int、long、signed、unsigned、float、double以及结构说明符、枚举说明符、联合说明符。然后我们知道C语言的变量存储类型有auto、static、register,链接类型有extern、static,还有类型限定符const、volatile,这些都是C语言常见的关键字和各种类型,那么一个声明中至少要有一个类型说明符,这个很好理解,因为这个类型说明符告诉计算机我们要存储的数据类型。
声明器的部分见上面,我已经把它说得比较清楚了。
关于其他声明器,我举出一个例子大家就明白了:
char i, j;
看到它同时声明了两个变量,其中j就是其他声明器,这表示同一条声明语句中可以同时声明多个变量。
最后一个分号,是C语言中一条语句结束的标志。
至此,C语言的声明就已经很清楚了,不过要注意在声明的时候还是有一些其他规则,比如说函数的返回值不能是一个函数或数组,数组里面也不能含有函数。
了解了C语言声明的详细内容之后,我们再来看看如何分析C语言的声明:
接下来我们要做的事情就是,用通俗的语言把声明分解开来,分别解释各个组成部分。
在这里提一句,关于分析C语言的声明部分,在《C与指针》的第13章——高级指针话题中也有详细的描述,会一步一步从简单的声明到复杂的声明,再介绍一些高级指针的用法。而在本书中,我们将着重建立一个模型来分析所有的声明。
先来理解C语言声明的优先级规则:
A 声明从它的名字开始读取,然后按照优先级顺序依次读取
B 优先级从高到低依次是:
1. 声明中被括号括起来的部分
2. 后缀操作符:括号()表示这是一个函数;[]则表示这是一个数组
3. 前缀操作符:星号* 表示"指向...的指针“
C 如果const或volatile关键字存在,那么按我在前面所说的办法判断它们修饰标识符还是修饰类型
下面,还是给出一个例子来帮助理解:
char * const *(*next) ();
A 首先,变量名是next
B next被一个括号括住,而括号的优先级最高,所以”next是一个指向...的指针“
然后考虑括号外面的后缀操作符为(),所以”next是一个函数指针,指向一个返回值为...的函数“
然后考虑前缀操作符,从而得出”next是一个函数指针,指向一个返回值为...的指针的函数“
C 最后,char * const是一个指向字符的常量指针
所以,我们可以得出结论:next是一个函数指针,该函数返回一个指针,这个指针指向一个类型为char的常量指针。
当然,如果不想自己分析这些复杂的声明,你还有一个好的选择,就是用一个工具来帮助你分析;或者你想知道自己的分析对不对,也可以用到这个工具——cdecl,它是一个C语言声明的分析器,可以解释一个现存的C语言声明。下面我简述它的安装和使用过程,同样是在Linux上:
首先,安装命令
sudo apt install cdecl
然后直接输入应用程序名进入程序
cdecl
然后直接输入,来检测一下我们刚刚分析的例子
cdecl> explain char * const *(*next) (); declare next as pointer to function returning pointer to const pointer to char
噢,看起来很不错嘛,我们分析得对,这个程序也解释得很棒,怎么样,是不是对这个程序感到好奇,下面我们来尝试自己实现这个程序:
首先我们想办法用一个图来表示分析声明的整个过程,上面给出的步骤很有用,但是还是不够直观,在书中作者给出了一个解码环的图来描述这个步骤,下面我把这个图大致的描述出来,有的地方可能加上我自己的理解和修改:
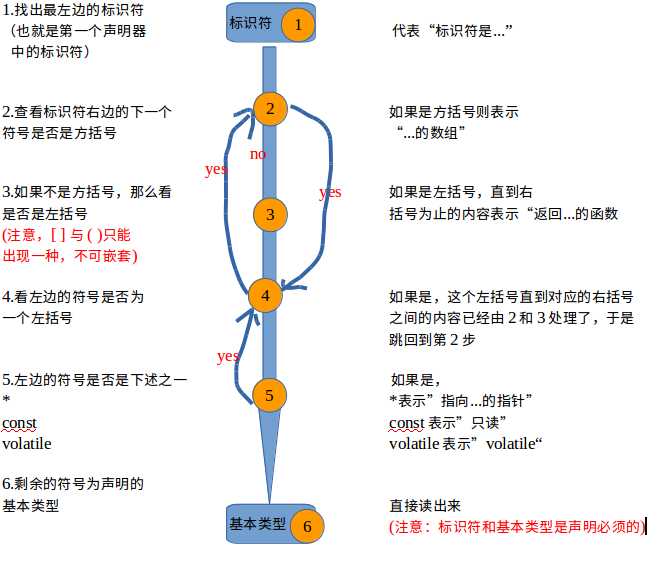
要注意的事项我已经把它们都标志出来了,现在让我们用这个流程图来分析一个实例:
char * const *(*next) ();
分析过程中另外有一点需要特别注意,那就是需要逐渐把已经处理过的片段“去掉”,这样便能知道还需要分析多少内容。
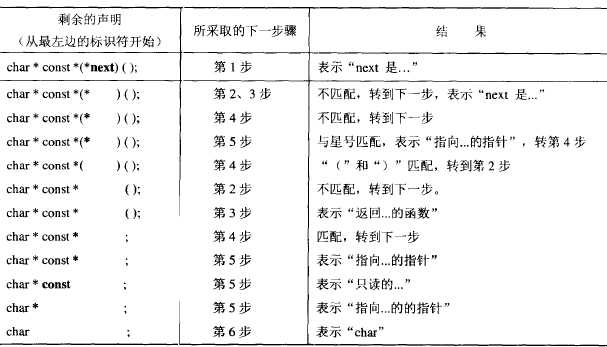
上面的表格就是这个表达式根据前面给出的流程图分析声明的全部过程,从表格中第一列可以看出这个表达式被处理过的部分在一步一步的去掉,这个程序的处理过程现在已经讲得非常清楚了,接下来,给出实现这个过程的具体代码,为了简单起见,暂且忽略错误处理部分,以及在处理结构、枚举、联合时只简单的用“struct”,“enum“和”union“来代表,假定函数的括号内没有参数列表,否则事情就变得复杂多了!这个程序可能要用到一些数据结构,比如说堆栈,像这种需要一个一个按序列读取的程序总是免不了要用到堆栈的,在表达式求值等其他应用也经常见到。
我们把用结构来包括每一种标记,首先定义数据结构
#include <stdio.h> #include <string.h> #include <ctype.h> #include <stdlib.h> #define MAXTOKENS 100 //一条声明中的标记数量 #define MAXTOKENLEN 64 //每个标记最长的长度 enum type_tag {IDENTIFIER, QUALIFIER, TYPE}; //定义类型标签,包括标识符、限定符、类型符 struct token{ //声明一个标记结构,其中type就是枚举变量中的类型 char type; char string[MAXTOKENLEN]; //类型的名字,例如int }; int top = -1; //栈顶 struct token stack[MAXTOKENS]; //栈的内存为MAXTOKENS struct token this; //刚刚读入的那个标记 #define pop stack[top--] //用宏定义两个函数,一个是push,一个是pop #define push(s) stack[++top] = s
定义好数据结构之后,main函数要做的第一步是找出标识符,然后按照上面的流程表执行就行
main() { read_to_first_identifier(); //找出第一个标识符 deal_with_declarator(); //进入处理标识的函数 printf("\n"); return 0; }
下面来介绍单个函数,首先是两个基本工具函数,一个是用来判断当前读取的标记的类型,另一个用来读取下一个标记到”this“
enum type_tag classify_string(void) //判断当前读取的标记是什么类型,返回值为枚举中的一个值 { char *s = this.string; //如果是const,则把这个标记的string成员改为"只读“ if(!strcmp(s, "const")){ strcpy(s, "read-only"); return QUALIFIER; } if(!strcmp(s, "volatile")) return QUALIFIER; if(!strcmp(s, "void")) return TYPE; if(!strcmp(s, "char")) return TYPE; if(!strcmp(s, "signed")) return TYPE; if(!strcmp(s, "unsigned")) return TYPE; if(!strcmp(s, "short")) return TYPE; if(!strcmp(s, "int")) return TYPE; if(!strcmp(s, "long")) return TYPE; if(!strcmp(s, "float")) return TYPE; if(!strcmp(s, "double")) return TYPE; if(!strcmp(s, "struct")) return TYPE; if(!strcmp(s, "union")) return TYPE; if(!strcmp(s, "enum")) return TYPE; return INDENTIFIER; //如果标记既不是限定符也不是类型符,那就是标识符 } void gettoken(void) //读取下一个标记到”this“ { char *p = this.string; while((*p = getchar()) == ‘ ‘); //跳过所有的空白字符 if(isalnum(*p)){ //如果遇到标记(标记必须以字母或数字开头) while(isalnum(*++p = getchar())); ungetc(*p, stdin); *p = ‘\0‘; this.type = classify_string(); return ; } if(*p == ‘*‘){ //如果遇到指针 strcpy(this.string, "pointer to"); this.type = ‘*‘; return ; } this.string[1] = ‘\0‘; this.type = *p; return ; }
接下来看读取第一个标识符,并且同时从左至右扫描声明,遇到标记则压入栈中
read_to_first_identifer() //[流程中的第一步] { gettoken(); while(this.type != IDENTIFIER){ push(this); gettoken(); } printf("%s is ",this.string); gettoken(); }
找到标识符的同时,标记的左半部分我们也已经压入了栈中,接下来处理标识符之后可能存在的数组、函数
deal_with_declarator() { switch(this.type){ //查看当前标记的类型 case ‘[‘: deal_with_arrays(); //如果是数组,那么执行对数组的处理[流程中的第二步] break; case ‘(‘: //如果是函数,那么执行对函数的处理[流程中的第三步] deal_witch_function_args(); } deal_with_pointers(); //处理指针,流程中的第五步 while(top >= 0){ if(stack[top].type == ‘(‘){ //判断是否是左括号,流程中的第四步 pop; gettoken(); deal_with_declaration(); }else{ printf("%s ",pop.string); } } }
接下来就是编写这些处理函数
deal_with_arrays() { while(this.type == ‘[‘){ printf("array "); gettoken(); if(isdigit(this.string[0])){ printf("0..%d ",atoi(this.string) - 1); gettoken(); } gettoken(); printf("of "); } } deal_with_fucntion_args() { while(this.type != ‘)‘){ gettoken(); } gettoken(); printf("function returning "); } deal_with_pointers() { while(stack[top].type == ‘*‘){ printf("%s ", pop.string); } }
以上就是整个程序简单版的代码,为了增加一些趣味,有兴趣的朋友可以用昨天的lint检查程序对上面的程序做出检查,从而完善这个简单版的程序。
标签:实例 求值 优先级 自己的 执行 关系 语言 对象 并且
原文地址:http://www.cnblogs.com/monster-prince/p/6212820.html