标签:schema password cascade har 命名 姓名 ora des 服务
一、创建数据库:
语法:create {database|schema}[if not exists] db_name [default] character set[=] charset_name;
{}:表示必选项 []:表示可选 |:表示选择
如1:create database demo;
执行情况:当名为demo的数据库不存在时,执行后,创建成功,没有错误。
当名为demo的数据库已经存在时,执行后,不会重新创建,且报错。
如2:create database if not exists demo;
执行情况:当名为demo的数据库不存在时,执行后,创建成功,没有错误。
当名为demo的数据库已经存在时,执行后,不会重新创建,没有错误。
二、查看当前服务器下的数据库列表:
语法:show {databases|schemas} [like ‘pattern’| where expr];
如:show databases; (注意复数形式S)
三、修改数据库编码方式:
语法:alter {database|schema} [db_name] [default] character set [=] charset_name
四、删除数据库
语法:drop {database|schema} [if exists] db_name
drop database if exists demo;
五、创建数据库
第一步:打开数据库
语法:use db_name; (PS:查询当前打开的数据库:select database();)
第二步:查看数据库中存在的数据表:
语法:show tables [from db_name] [like ‘pattern’|where expr]; (注意复数形式S)
第三步:创建数据库表:
语法:create table [if not exists] table_name(
Column_name data_type,
….
)
例如:建立一个工资表,表的内容包含员工姓名、年龄、工资
create table tb1(
username varchar(20),
age tinyint unsigned,
salary float(8,2) unsigned
); (PS:最后一行没有逗号)
六、查看数据表结构:
语法:show columns from table_name;
例如: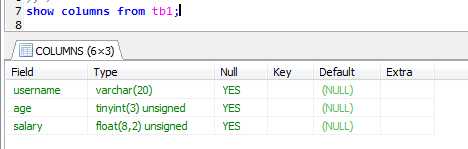
七、创建数据库表细节引申(约束)
约束的作用:1. 保证数据的完整性和一致性 2. 分为表级约束和列级约束
约束的类型包括:Not null(非空约束)、Primary key(主键约束)、Unique key(唯一约束)、Default(默认约束)、Foreign key(外键约束)
a、设置数据表的时候设定字段属性:空值与非空(null 以及not null)
例如:create table tb2(
username varchar(20) not null,//用户名不可为空
age tinyint unsigned null//年龄可为空
);
b、自动编号属性(auto_increment):在众多记录当着保证某条记录的唯一性
特殊点:1、必须与主键组合使用 2、默认情况下,起始值为1,每次的增量为1
例如:create table tb3(
id smallint unsigned auto_increment,
username varchar(20) not null,
age tinyint unsigned null
);
执行后,报错。自动编号的字段未被定义为主键。
c、主键约束:primary key 特点:每张表只能存在一个主键,主键保证记录的唯一性且主键自动为not null
例如:
create table tb3(
id smallint unsigned auto_increment primary key,
username varchar(20) not null,
age tinyint unsigned null
);
d、唯一约束:unique key 特点:保证记录的唯一性、字段可谓空值且每张表可以存在多个唯一约束
primary key和unique key都能保证数据的唯一性,区别在于primary key一张表里只能存在一个,unique key一张表可以存在多个。
e、默认约束:default 特点:当插入记录时,没有明确为字段赋值,则自动赋予默认值。
例如:create table tb7(
id smallint unsigned auto_increment primary key,
username varchar(20) not null unique key,
sex enum(‘1‘,‘2‘,‘3‘) default ‘3‘
)
sex字段:1:男,2:女,3:保密,默认值为保密。
f、外键约束:Foreign key 作用:1.保持数据的一致性,完整性。 2.实现一对一或一对多的关系
外键约束的要求:
(PS:编辑数据表的默认存储引擎:Mysql配置文件my.ini文件内:default-storage-engine=INNODB)
查看此表是否使用了刚设置的默认存储引擎,语法为:show create table tb_name;
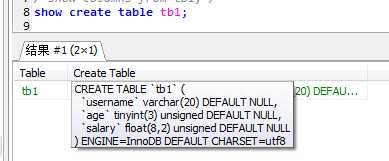
示例:
创建数据表省份表:
create table province(
id smallint unsigned auto_increment primary key,
pname varchar(20) not null
);
创建另一个表:
create table users(
id smallint unsigned auto_increment primary key,
username varchar(20) not null,
pid bigint,
foreign key (pid) references province(id)
);
运行后报错,错误的原因是子表中的pid字段数据类型与父表中id的数据类型不一样。
修改后运行:
create table users(
id smallint unsigned auto_increment primary key,
username varchar(20) not null,
pid smallint,
foreign key (pid) references province(id)
);
运行后报错,错误的原因是子表中的pid字段数据类型与父表中id的数据类型还是不一样。
再修改为:
create table users(
id smallint unsigned auto_increment primary key,
username varchar(20) not null,
pid smallint unsigned,
foreign key (pid) references province(id)
);
效果:Users为子表,province为父表。Pid为外键列,id参照列
查询以上记录是否创建索引:
ID为主键,主键会自动添加索引。
show index from province;


外键约束的参照操作:
例如:
create table users1(
id smallint unsigned auto_increment primary key,
username varchar(20) not null,
pid smallint unsigned,
foreign key (pid) references province(id) on delete cascade
);
插入记录:
insert province(pname) values (‘a‘);
insert province(pname) values (‘b‘);
insert province(pname) values (‘c‘);
insert users1(username,pid) values (‘tom‘,3);
insert users1(username,pid) values (‘john‘,3);
insert users1(username,pid) values (‘rose‘,1);
执行删除操作:delete from province where id=3;
允许后可以发现province标准c记录被删除,users1表中,pid为3的tom和John都被删除
八、增删改查:
a、增
添加单列:
语法:alter table tal_name add [column] col_name column_definition [first|after col_name]
First:新增列为第一列,省略则为最后一列
添加多列:
语法:alter table tal_name add [column] (col_name column_definition,…)
插入记录:(有三种方法)
方法一语法:insert [into] table_name[(col_name,…)]values(val,…)
例如:
create table users(
id smallint unsigned primary key auto_increment,
username varchar(20) not null,
password varchar(32) not null,
age tinyint unsigned not null default 10,
sex BOOL
);
分析:字段id是自动编号的,如果所有字段都要赋值的话,有两种方法:
第一种方法:insert users values (null,‘tom‘,‘123‘,25,1);
第二种方法:insert users values (default,‘jack‘,‘456‘,25,1);
查询select * from users;结果如下:
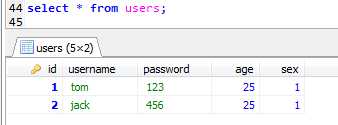
ps:对有默认值的字段进行复制的方法:
示例: 查看表:show columns from users;
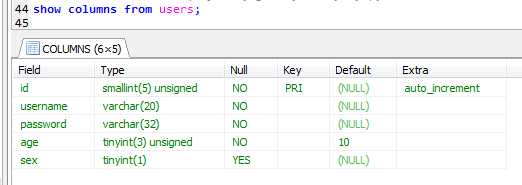
字段age有默认值10
插入一条记录,给age字段赋予值10,有以下两种方式:
insert users values (default,‘kiki‘,‘555‘,10,1);
insert users values (default,‘lucy‘,‘234‘,default,1);
查询结果:select * from users;
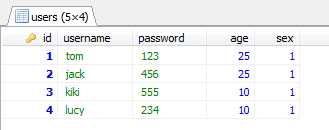
方法二语法:Insert [into] tbl_name set col_name={expr|default},…
说明:与第一种方式的区别在于,此方法可以使用子查询。
insert users set username=‘ben‘,password=‘123‘;
查询结果:select * from users;
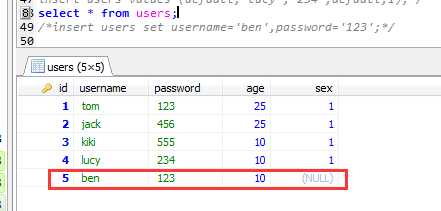
插入数据的第三种方法:
Insert [into] tbl_name [(col_name,…)]select …
说明:此方法可以将查询结果插入到指定数据表。
例如:建新表:
create table test(
id tinyint unsigned primary key auto_increment,
username varchar(20)
);
执行操作,将users表中年龄大于30的记录写入到test表
执行:insert test select username from users where age>=30;
执行后报错: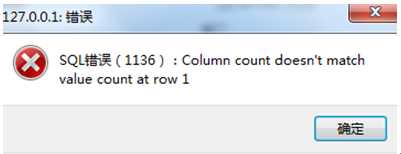
insert test(username) select username from users where age>=30;
执行后:select * from test;
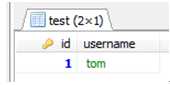
b、删
删除列:alter table tal_name drop [column] col_name;
删除多列:alter table tal_name drop [column] col_name,drop [column] col_name1,…
删除主键约束:alter table tbl_name drop primary key
删除唯一约束:alter table tbl_name drop {index|key} index_name
删除外键约束:alter table tbl_name drop foreign key fk_symbol
使用语句:show create table users3;查看表结构
CREATE TABLE `users3` (
`username` varchar(10) NOT NULL,
`pid` smallint(5) unsigned DEFAULT NULL,
`id` smallint(5) unsigned NOT NULL DEFAULT ‘0‘,
`age` tinyint(3) unsigned NOT NULL DEFAULT ‘15‘,
KEY `pid` (`pid`),
CONSTRAINT `users3_ibfk_1` FOREIGN KEY (`pid`) REFERENCES `province` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
删除约束:alter table users3 drop foreign key users3_ibfk_1;
执行后再查看表结构::show create table users3;
CREATE TABLE `users3` (
`username` varchar(10) NOT NULL,
`pid` smallint(5) unsigned DEFAULT NULL,
`id` smallint(5) unsigned NOT NULL DEFAULT ‘0‘,
`age` tinyint(3) unsigned NOT NULL DEFAULT ‘15‘,
KEY `pid` (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
发现还是存在索引的。如果不想要, 可以执行:alter table users3 drop index pid;
再次查看结构::show create table users3;
CREATE TABLE `users3` (
`username` varchar(10) NOT NULL,
`pid` smallint(5) unsigned DEFAULT NULL,
`id` smallint(5) unsigned NOT NULL DEFAULT ‘0‘,
`age` tinyint(3) unsigned NOT NULL DEFAULT ‘15‘
) ENGINE=InnoDB DEFAULT CHARSET=utf8
单表删除:delete from tbl_name [where_condition]
例如:delete from users where id = 5;
c、改
修改列定义:
Alter table tbl_name modify [column] col_name column_definition [first|after col_name]
比如:以下表,id字段并没有摆在第一个(虽然位置没有关系)
修改下:Alter table users3 modify id smallint unsigned first;
查询表结构:show columns from users3;
修改列名称:alter table tbl_name change [column] old_col_name new_col_name column_definition [first|after col_name]
执行后:alter table users3 change pid p_id tinyint unsigned not null;
查看表结构:show columns from users3;
更改数据表的名字:
方法1:alter table tbl_name rename[to|as] new_tbl_name
方法2:rename table tbl_name to new_tbl_name [,tbl_name2 to new_tbl_name2]…
单表更新update
Update [low_priority][ignore]table_reference set col_name1={expr1|default}{, col_name2={expr2|default}}…[where where_condition]
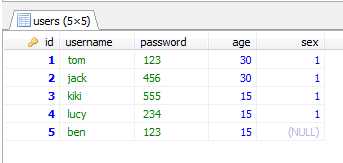
更新记录:update users set age = age + 5 where 1;
查看记录:select * from users;
添加约束:
添加主键约束:
语法:alter table tbl_name add [constraint [symbol]] primary key [index_type](index_col_name,…)
例如:建表如下:
create table users3(
username varchar(10) not null,
pid smallint unsigned
);
查看表的结构:show create table users3;
为表添加一列:alter table users3 add id smallint unsigned;
将新添加的列设置为主键:alter table users3 add primary key(id);
或alter table users3 add constraint pk_users3_id primary key(id);
添加唯一约束:(主键约束只有一个,唯一约束可以有多个)
Alter table tbl_name add [constraint [symbol]] unique [index|key][index_name][index_type](index_col_name,…)
例如:alter table users3 add unique (username);
添加外键约束:alter table tbl_name add [constraint[symbol]]foreign key [index_name](index_col_name,…)reference_definition
添加或删除默认约束:alter table tbl_name alter [column]col_name {set default literal|drop default}
添加是:set default literal
删除是: drop default
例如:在表中添加列:alter table users3 add age tinyint unsigned not null;
添加约束,为字段age添加默认值15
Alter table users3 alter age set default 15;
d、查
查找表记录:
语法:select expr,… from table_name (PS: expr表示表达式)
例如:select * frome tb1;(查找出所有记录)
查询表达式解析:
Select select_expr [,select_expr…]
{
From table_references
[where where_condition]
[group by {col_name|position}[asc|desc],…]
[having where_condition]
[ORDER BY {col_name|expr|positon}[asc|desc],…]
[limit{[offset,]row_count|row_count offset offset}]
}
查询表达式:每一个表达式表示想要的一列,必须有至少一个
多个列之间以英文逗号分隔
星号(*)表示所有列。Tbl_name.*可以表示命名表的所有列。
查询表达式可以使用[as]alias_name为其赋予别名。
别名可用于group by,order by或having子句。
例如:select username,id from users
select users.id,users.username from users(与上面查询方式不同的是,指定了哪张表的id及username,在多表查询中用得到)
赋予别名(在PHP中用得到):例如select id,username from users;
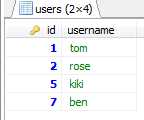
使用:select id AS UID,username AS uname from users;
结果:
其中AS是可以省略的,例如:select id UID,username uname from users;
但是不建议省略,因为省略的话会出现错误,如下:
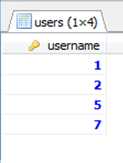
select id username from users;(username作为id的别名),结果是:
对查询的结果进行分组:group by
[group by {col_name|position}[asc|desc],…]
Asc是升序,默认的 desc是降序
查询:select * from users;结果是:
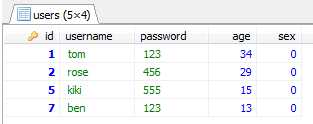
select * from users group by password;结果是:
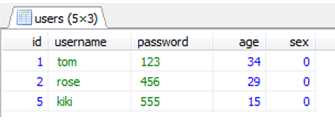
select * from users group by 1;
(后面添加数字是指字段值的位置,1表示安装id分组,2表示按照username分组)
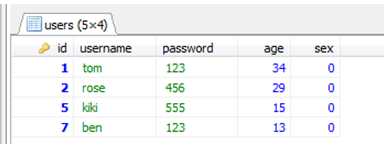
设置分组条件:having
select sex from users group by 1 having age>30;
执行后会报错: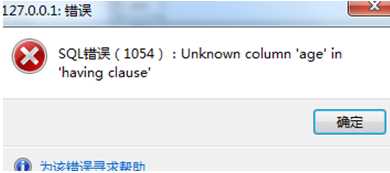
保证having条件的字段age必须出现在当前的select语句当中,或者having条件时聚合函数。
聚合函数是指常规的max,min,avg,sum等函数
select sex,age from users group by 1 having age>30; 运行正确。
或者使用一下方法:select sex from users group by 1 having count(id)>=2;
对查询结果进行排序:[order by {col_name|expr|position}[asc|desc],…]
select * from users order by id desc;
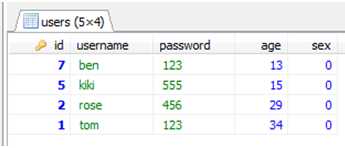
按照两个字段进行排序:如下:
select * from users order by age desc;
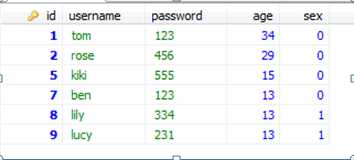
查询出age为13的记录有三条,再按照id降序排。
select * from users order by age desc,id desc;
限制查询结果返回的数量:limit
[limit {[offset,]row_count|row_count OFFSET offset}]
例如:select * from users;结果:
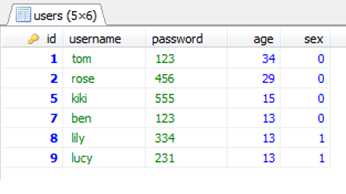
查询只想返回前两条数据,执行:select * from users limit 2;
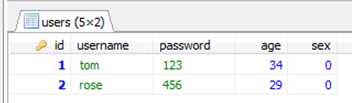
查询只想返回第3、4两条数据,执行:select * from users limit 2,2;
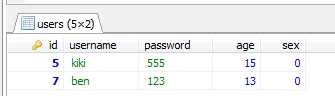
查询只想返回第5、6两条数据,执行:select * from users limit 4,2;
标签:schema password cascade har 命名 姓名 ora des 服务
原文地址:http://www.cnblogs.com/Crystalling/p/6223499.html