标签:1.3 root timestamp include hunk prefix dir database socket
1 使用规范
1.1 实例级备份恢复
1.2 库、表级别备份恢复
1.3 SQL结果备份及恢复
1.4 表结构备份
2 mysqldump
2.1 原理
2.2 重要参数
2.3 使用说明
2.3.1 实例备份恢复
2.3.2 部分备份恢复
3 PerconaXtraBackup
3.1 innobackupex原理(全量说明)
3.2 重要参数
3.2.1 备份参数
3.2.2 准备还原参数
3.2.3 备份目录拷贝参数
3.3 使用说明
3.3.1 实例备份及恢复
3.3.1.1 全量备份
3.3.1.2 增量备份恢复
3.3.2 部分备份
第一次发布博客,发现目录居然不会生成,后续慢慢熟悉博客园的设置。回正文~~~
使用innobackupex,在业务空闲期执行,考虑到IO影响及 FLUSH TABLE WITH READ LOCAK 拷贝非INNODB文件的锁表时间。。
常规备份中,使用innobackupex在从库备份执行,在无从库的情况下,允许在业务低峰期对整个实例拷贝。
考虑 数据量、磁盘IO情况、恢复难度问题。
mysqldump锁表时间长,备份时间长,但是导入方便,适合数据量小但是表格多 的库/表级别备份。
innobackupex锁表时间短,备份时间短,但是恢复较复杂,需要discord tablespace及 import TABLESPACE,除非允许备份文件成立单个实例,适合表数据量大但表格数量少的库/表级别备份。
如果是单表简单查询,使用mysqldump,添加where条件,例如:mysqldump -S /tmp/mysql3330.sock -uroot -p --databases db1 --tables tb1 tb2 tb3 -d >/data/backup/3330/mysqldump_20161229.sql 。
如果是复杂SQL查询结果,使用 INTO OUTFILE,如下:
1 #FIELDS TERMINATED BY ‘,‘ 字段间分割符 2 #OPTIONALLY ENCLOSED BY ‘"‘ 将字段包围 对数值型无效 3 #LINES TERMINATED BY ‘\n‘ 换行符 4 5 #查询导出 6 select * into outfile ‘/tmp/pt.txt‘ FIELDS TERMINATED BY ‘,‘ OPTIONALLY ENCLOSED BY ‘"‘ LINES TERMINATED BY ‘\n‘ from pt where id >3; 7 8 #加载数据 9 load data infile ‘/tmp/pt1.txt‘ into table pt FIELDS TERMINATED BY ‘,‘ OPTIONALLY ENCLOSED BY ‘"‘ LINES TERMINATED BY ‘\n‘
使用mysqldump,添加-d参数。
支持功能多且全面,但是锁表时间是个风险点,使用时注意,同时,若是5.6版本之前的,要充分考虑buffer pool的使用情况。
通过general log查看mysqldump运行原理,详细流程见代码块 mysqldump。
mysqldump运行中,第一步,会检查数据库的配置情况,例如是否设置GTID模式及参数配置;第二步,锁所有表格,只允许读操作;第三步,逐个拷贝表格,生成创建表格上SQL(字符集为binary),再SELECT * FROM 表格 生成数据脚步(字符集为UTF8);第4步,解锁。
当导出全实例或者大数据库时,这里有2个需要注意到问题:
1 执行SQL:mysqldump -S /tmp/mysql3330.sock -uroot -p --databases zero >/data/backup/3330/mysqldump_20161229.sql 2 3 2016-12-27T14:38:27.782875Z 1732 Connect root@localhost on using Socket 4 2016-12-27T14:38:27.803572Z 1732 Query /*!40100 SET @@SQL_MODE=‘‘ */ 5 2016-12-27T14:38:27.804096Z 1732 Query /*!40103 SET TIME_ZONE=‘+00:00‘ */ 6 2016-12-27T14:38:27.804528Z 1732 Query SHOW VARIABLES LIKE ‘gtid\_mode‘ #检查是否设置了GTID 7 2016-12-27T14:38:27.813387Z 1732 Query SELECT LOGFILE_GROUP_NAME, FILE_NAME, TOTAL_EXTENTS, INITIAL_SIZE, ENGINE, EXTRA FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = ‘UNDO LOG‘ AND FILE_NAME IS NOT NULL AND LOGFILE_GROUP_NAME IS NOT NULL AND LOGFILE_GROUP_NAME IN (SELECT DISTINCT LOGFILE_GROUP_NAME FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = ‘DATAFILE‘ AND TABLESPACE_NAME IN (SELECT DISTINCT TABLESPACE_NAME FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_SCHEMA IN (‘zero‘))) GROUP BY LOGFILE_GROUP_NAME, FILE_NAME, ENGINE, TOTAL_EXTENTS, INITIAL_SIZE ORDER BY LOGFILE_GROUP_NAME 8 2016-12-27T14:38:27.816987Z 1732 Query SELECT DISTINCT TABLESPACE_NAME, FILE_NAME, LOGFILE_GROUP_NAME, EXTENT_SIZE, INITIAL_SIZE, ENGINE FROM INFORMATION_SCHEMA.FILES WHERE FILE_TYPE = ‘DATAFILE‘ AND TABLESPACE_NAME IN (SELECT DISTINCT TABLESPACE_NAME FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_SCHEMA IN(‘zero‘)) ORDER BY TABLESPACE_NAME, LOGFILE_GROUP_NAME 9 2016-12-27T14:38:27.819423Z 1732 Query SHOW VARIABLES LIKE ‘ndbinfo\_version‘ 10 2016-12-27T14:38:27.824802Z 1732 Init DB zero 11 2016-12-27T14:38:27.825015Z 1732 Query SHOW CREATE DATABASE IF NOT EXISTS `zero` #生成创建数据库的的脚步 12 2016-12-27T14:38:27.825381Z 1732 Query show tables #检查该数据库里边有多少表格,根据这些表格来开始lock table 13 2016-12-27T14:38:27.825969Z 14 1732 Query LOCK TABLES `dsns` READ /*!32311 LOCAL */,`pt` READ 15 /*!32311 LOCAL */,`sbtest20` READ /*!32311 LOCAL */ 16 #锁表,仅允许读操作 17 18 ########################################每个表格重复部分############################################################ 19 2016-12-27T14:38:27.826324Z 1732 Query show table status like ‘dsns‘ 20 2016-12-27T14:38:27.832651Z 1732 Query SET SQL_QUOTE_SHOW_CREATE=1 21 2016-12-27T14:38:27.832930Z 1732 Query SET SESSION character_set_results = ‘binary‘ 22 2016-12-27T14:38:27.833169Z 1732 Query show create table `dsns` 23 #字符集修改为 binary,生成架构SQL 24 2016-12-27T14:38:27.833448Z 1732 Query SET SESSION character_set_results = ‘utf8‘ 25 2016-12-27T14:38:27.833793Z 1732 Query show fields from `dsns` 26 2016-12-27T14:38:27.834697Z 1732 Query show fields from `dsns` 27 2016-12-27T14:38:27.835598Z 1732 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `dsns` 28 #字符集修改为 utf8,导出数据SQL 29 2016-12-27T14:38:27.836129Z 1732 Query SET SESSION character_set_results = ‘binary‘ 30 2016-12-27T14:38:27.836401Z 1732 Query use `zero` 31 2016-12-27T14:38:27.836644Z 1732 Query select @@collation_database 32 2016-12-27T14:38:27.836949Z 1732 Query SHOW TRIGGERS LIKE ‘dsns‘ 33 2016-12-27T14:38:27.837738Z 1732 Query SET SESSION character_set_results = ‘utf8‘ 34 ########################################每个表格重复部分############################################################ 35 36 #每个表格的导出都重复上述部分 37 38 2016-12-27T14:38:28.525530Z 1732 Query SET SESSION character_set_results = ‘utf8‘ 39 2016-12-27T14:38:28.525832Z 1732 Query UNLOCK TABLES 40 #解锁,允许读写
以下参数在使用过程中,需要留意,根据实际情况添加:
只导出表结构
主要参数相见代码模 mysqldump主要参数,并非所有参数内容,这些参数较常使用。

1 [root@localhost zero]# mysqldump --help 2 Dumping structure and contents of MySQL databases and tables. 3 Usage: mysqldump [OPTIONS] database [tables] 4 OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...] 5 OR mysqldump [OPTIONS] --all-databases [OPTIONS] 6 7 8 --no-defaults Don‘t read default options from any option file, 9 except for login file. 10 --defaults-file=# Only read default options from the given file #. 11 12 13 -A, --all-databases Dump all the databases. This will be same as --databases 14 with all databases selected. 15 -Y, --all-tablespaces 16 Dump all the tablespaces. 17 -y, --no-tablespaces 18 Do not dump any tablespace information. 19 --add-drop-database Add a DROP DATABASE before each create. 20 --add-drop-table Add a DROP TABLE before each create. 21 (Defaults to on; use --skip-add-drop-table to disable.) 22 --add-drop-trigger Add a DROP TRIGGER before each create. 23 --add-locks Add locks around INSERT statements. 24 (Defaults to on; use --skip-add-locks to disable.) 25 26 27 --apply-slave-statements 28 Adds ‘STOP SLAVE‘ prior to ‘CHANGE MASTER‘ and ‘START 29 SLAVE‘ to bottom of dump. 30 31 32 -B, --databases Dump several databases. Note the difference in usage; in 33 this case no tables are given. All name arguments are 34 regarded as database names. ‘USE db_name;‘ will be 35 included in the output. 36 37 38 --master-data[=#] This causes the binary log position and filename to be 39 appended to the output. If equal to 1, will print it as a 40 CHANGE MASTER command; if equal to 2, that command will 41 be prefixed with a comment symbol. This option will turn 42 --lock-all-tables on, unless --single-transaction is 43 specified too (in which case a global read lock is only 44 taken a short time at the beginning of the dump; don‘t 45 forget to read about --single-transaction below). In all 46 cases, any action on logs will happen at the exact moment 47 of the dump. Option automatically turns --lock-tables 48 off. 49 -n, --no-create-db Suppress the CREATE DATABASE ... IF EXISTS statement that 50 normally is output for each dumped database if 51 --all-databases or --databases is given. 52 -t, --no-create-info 53 Don‘t write table creation info. 54 -d, --no-data No row information. 55 -p, --password[=name] 56 Password to use when connecting to server. If password is 57 not given it‘s solicited on the tty. 58 -P, --port=# Port number to use for connection. 59 60 61 --replace Use REPLACE INTO instead of INSERT INTO. 62 63 64 --set-gtid-purged[=name] 65 Add ‘SET @@GLOBAL.GTID_PURGED‘ to the output. Possible 66 values for this option are ON, OFF and AUTO. If ON is 67 used and GTIDs are not enabled on the server, an error is 68 generated. If OFF is used, this option does nothing. If 69 AUTO is used and GTIDs are enabled on the server, ‘SET 70 @@GLOBAL.GTID_PURGED‘ is added to the output. If GTIDs 71 are disabled, AUTO does nothing. If no value is supplied 72 then the default (AUTO) value will be considered. 73 --single-transaction 74 Creates a consistent snapshot by dumping all tables in a 75 single transaction. Works ONLY for tables stored in 76 storage engines which support multiversioning (currently 77 only InnoDB does); the dump is NOT guaranteed to be 78 consistent for other storage engines. While a 79 --single-transaction dump is in process, to ensure a 80 valid dump file (correct table contents and binary log 81 position), no other connection should use the following 82 statements: ALTER TABLE, DROP TABLE, RENAME TABLE, 83 TRUNCATE TABLE, as consistent snapshot is not isolated 84 from them. Option automatically turns off --lock-tables. 85 86 87 --tables Overrides option --databases (-B). 88 --triggers Dump triggers for each dumped table. 89 (Defaults to on; use --skip-triggers to disable.) 90 -u, --user=name User for login if not current user.
语法主要有以下三类:
Usage: mysqldump [OPTIONS] database [tables] OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...] OR mysqldump [OPTIONS] --all-databases [OPTIONS]
#实例备份 mysqldump -S /tmp/mysql3330.sock -uroot -p --all-datqabases >/data/backup/3330/mysqldump_20161229.sql #实例恢复 #新建实例后,导入脚本 mysql --socket=/tmp/mysql3306.sock -uroot -p < /data/backup/3330/mysqldump_20161229.sql
1 #指定单个或者多个DB备份 2 mysqldump -S /tmp/mysql3330.sock -uroot -p db1 db2 db3 >/data/backup/3330/mysqldump_20161229.sql 3 mysqldump -S /tmp/mysql3330.sock -uroot -p --databases db1 db2 db3 >/data/backup/3330/mysqldump_20161229.sql 4 5 #指定单个或者多个表格备份 6 mysqldump -S /tmp/mysql3330.sock -uroot -p --databases db1 --tables tb1 tb2 tb3 >/data/backup/3330/mysqldump_20161229.sql 7 mysqldump -S /tmp/mysql3330.sock -uroot -p db1 tb1 tb2 tb3 >/data/backup/3330/mysqldump_20161229.sql 8 9 #只导出单个表格的某些行数据 10 mysqldump -S /tmp/mysql3330.sock -uroot -pycf.com zero pt --where=‘1=1 limit 2‘ >/data/backup/3330/mysqldump_20161229.sql 11 12 #只备份表结构,不要表数据 13 mysqldump -S /tmp/mysql3330.sock -uroot -p --databases db1 --tables tb1 tb2 tb3 -d >/data/backup/3330/mysqldump_20161229.sql 14 15 #只备份表数据,不要表结构 16 mysqldump -S /tmp/mysql3330.sock -uroot -pycf.com zero pt --where=‘id>3‘ --no-create-info >/data/backup/3330/mysqldump_20161229.sql 17 18 #恢复数据 19 source /data/backup/3330/mysqldump_20161229.sql
PerconaXtraBackup软件中,含有xtrabackup跟innobackupex,xtrabackup中不备份表结构,innobackupex调用xtrabackup子线程后再备份表结构,故常用innobackupex,xtraback不做日常使用。目前支持 Myisam,innodb,可以备份 .frm, .MRG, .MYD, .MYI, .MAD, .MAI, .TRG, .TRN, .ARM, .ARZ, .CSM, CSV, .opt, .par, innoDB data 及innobdb log 文件。
对数据库文件进行copy操作,同时建立多一个xtrabackup log 同步mysql的redo线程,copy数据文件结束时,flush table with read lock,拷贝非innodb数据文件的文件,拷贝结束后解锁。原理图见下图(图片来自知数堂)。通过general log查看mysqldump运行原理,详细流程见代码块 innobackupex。
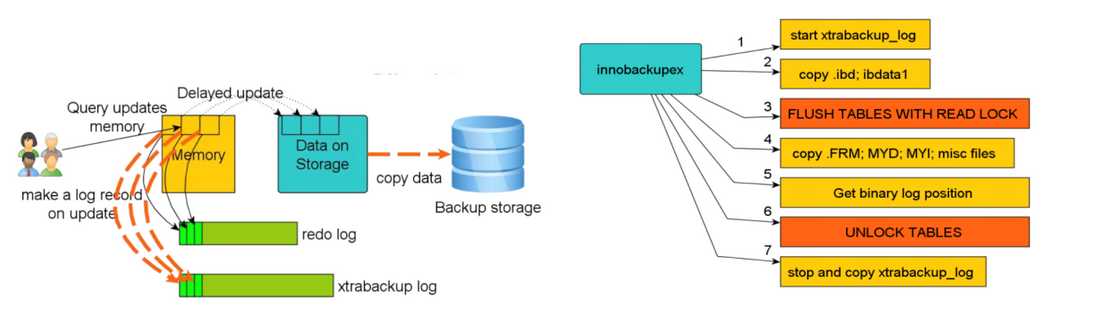
这里需要注意2个点:
innobackupex锁表时间是 data文件及log文件copy结束时,才锁表,锁表时长为拷贝non-InnoDB tables and files的时长,相对时间较短,对业务影响小。
copy数据文件的过程中,由于是不锁表,允许数据进行DML操作,这里需要注意,如果这个时候,拷贝的过程中有大事务一直没有提交,界面显示log scanned up,持续copy binlog追上数据库的binlog文件,并且该时间点刚好所有事务已提交(这里测试的时候,如果是单条 insert ,delete,update的大事务,则是要等待单条完成才提交,但是如果是begin事务里边的,不用等待是否commit or rollback,begin里边的单条事务执行结束,则就开始提交,恢复的时候,当作是undo 事务,不会提交该事物,回滚该事务)。大事务容易导致备份时长加长,IO占用。
1 2016-12-26T15:18:39.627366Z 1659 Connect root@localhost on using Socket 2 2016-12-26T15:18:39.627789Z 1659 Query SET SESSION wait_timeout=2147483 3 2016-12-26T15:18:39.628193Z 1659 Query SHOW VARIABLES 4 #记录LSN号码,开始copy ibd文件 5 2016-12-26T15:18:55.673740Z 1659 Query SET SESSION lock_wait_timeout=31536000 6 2016-12-26T15:18:55.674281Z 1659 Query FLUSH NO_WRITE_TO_BINLOG TABLES 7 #强制把没有 还没写入binlog 磁盘文件的缓存 强制刷新到磁盘 8 #开始拷贝数据库文件,这里需要注意,如果这个时候,拷贝的过程中有大事务一直没有提交,则会一直拷贝其产生的 ,界面显示log scanned up,直到copy binlog追上数据库的binlog文件,并且该时间点刚好所有事务已提交(这里测试的时候,如果是单条 insert ,delete,update的大事务,则是要等待单条完成才提交,但是如果是begin事务里边的,不用等待是否commit or rollback,begin里边的单条事务执行结束,则就开始提交,恢复的时候,当作是undo 事务,不会提交该事物,回滚该事务。 ) 9 2016-12-26T15:18:55.676345Z 1659 Query FLUSH TABLES WITH READ LOCK 10 #锁表,只允许读,不允许写及其他架构修改操作 11 #拷贝除innodb 数据文件外的其他所有文件,包括表结构等,Starting to backup non-InnoDB tables and files 12 2016-12-26T15:18:59.691409Z 1659 Query SHOW MASTER STATUS 13 #记录 备份到的 binlog文件及position位置,这个记录在 xtrabackup_binlog_info 文件,可提供复制使用 14 2016-12-26T15:18:59.734418Z 1659 Query SHOW VARIABLES 15 2016-12-26T15:18:59.754530Z 1659 Query FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS 16 2016-12-26T15:18:59.968452Z 1659 Query UNLOCK TABLES 17 #解锁,表格恢复可写,架构可修改 18 2016-12-26T15:18:59.991046Z 1659 Query SELECT UUID() 19 2016-12-26T15:19:00.005980Z 1659 Query SELECT VERSION()
根据 BACKUP-DIR/xtrabackup_logfile创建新的logfile,xtrabackup为子进程,不连接数据库服务.
1 #全量备份 实例备份及恢复 2 #备份 3 innobackupex --defaults-file=/data/mysql/mysql3330.cnf --user=root --password=ycf.com --no-timestamp /data/backup/3330/20161229 4 innobackupex --apply-log /data/backup/3330/20161229 5 6 #恢复 7 innobackupex --copy-back --datadir=/data/mysql/mysql3350/data /data/backup/3330/20161229
1 #增量备份 2 innobackupex --defaults-file=/data/mysql/mysql3376.cnf --user=root --password=ycf.com --no-timestamp --incremental-basedir=/data/backup/3330/20161229 --incremental /data/backup/mysql3376/20161230diff 3 4 innobackupex --defaults-file=/data/mysql/mysql3376.cnf --user=root --password=ycf.com --no-timestamp --incremental-basedir=/data/backup/3330/20161230diff --incremental /data/backup/mysql3376/20161231diff 5 6 #增量恢复 7 #现在完整备份文件中中应用redo日志,记得是redo-only, redo-only, redo-only, redo-only, 不是readonly,打死记得,不要乱来!!!!!! 8 innobackupex --apply-log --redo-only /data/backup/3330/20161229 9 10 #应用第一个增量备份文件的redo日志到完整备份文件夹中 11 innobackupex --apply-log --redo-only /data/backup/3330/20161229 --incremental-dir=/data/backup/mysql3376/20161230diff 12 13 #应用最后一个增量备份文件的redo日志到完整备份文件夹中,可以直接apply-log 14 innobackupex --apply-log /data/backup/3330/20161229 --incremental-dir=/data/backup/mysql3376/20161231diff
1 #部分备份 2 #指定数据库备份 3 innobackupex --defaults-file=/data/mysql/mysql3330.cnf --databases=‘zero mysql‘ --user=root --password=ycf.com --no-timestamp /data/backup/3330/20161202 4 5 #指定表格备份 6 #3.1 --include 使用正则表达式 7 8 #3.2 --table-file 备份的完整表名写在file文件中 9 vim /tmp/backupfile #每行写一个库名,或者一个表的全名(database.table),写完库名或者表名后,千万不要有空格或者其他空白符号,会导致识别不了该表格或者库名,从而导致跳过 10 innobackupex --defaults-file=/data/mysql/mysql3330.cnf --tables-file=/tmp/backupfile --user=root --password=ycf.com --no-timestamp /data/backup/3330/20161204 11 12 #3.3 --databases 完整库名和表名写在一起,用空格隔开 13 innobackupex --defaults-file=/data/mysql/mysql3330.cnf --user=root --password=ycf.com --no-timestamp --databases=zero.s1 /data/backup/3330/20161229 14 15 #指定表格恢复(开启独立表空间) 16 #首先要自己现在需要恢复的数据库上,创建该表格,然后discard tablespace,拷贝ibd文件过来,chown 文件所有者及用户组为mysql,再 import tablespace。 17 #如果有大量表格,用这个操作就比较麻烦,需要一个个来创建,包括指定数据库,也是这样处理,整个数据库先创建之后,在一个个表格discard,再import。 18 ALTER TABLE S1 DISCARD TABLESPACE; 19 ALTER TABLE S1 import TABLESPACE;
标签:1.3 root timestamp include hunk prefix dir database socket
原文地址:http://www.cnblogs.com/xinysu/p/6229991.html
