MySQL源码自定义了hash表,因为hash表具有O(1)的查询效率,所以,源码中大量使用了hash结构。下面就来看下hash表的定义:
【源代码文件include/hash.h mysys/hash.c】
typedef uint my_hash_value_type;
typedef uchar *(*my_hash_get_key)(const uchar *,size_t*,my_bool);
typedef void (*my_hash_free_key)(void *);
typedef struct st_hash {
size_t key_offset,key_length; /* Length of key if const length */
size_t blength;
ulong records;
uint flags;
DYNAMIC_ARRAY array; /* Place for hash_keys */
my_hash_get_key get_key;
void (*free)(void *);
CHARSET_INFO *charset;
} HASH;
typedef struct st_hash_info {
uint next; /* index to next key */
uchar *data; /* data for current entry */
} HASH_LINK;
hash的特点:
1. hash的每一个元素都存放在array动态数组中
2. 给定一个key值,通过hash算法来计算它在array中的位置
3.
array中的元素存放的是hash_link对象,而使用hash表的对象必须自己申请内存,把地址存放在hash_link->data中
4. 根据key获取一个元素hash_link->data时,需要强制转换成保存进去的类型。
5.
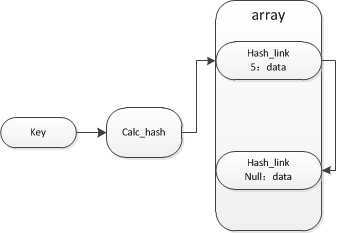
hash表虽然使用calc_hash来计算hash值,但会按照array的位置(hash_mask函数)来进行存放。
用一个图来表示下:
下面看下hash表的函数:
1. _my_hash_init(HASH *hash, uint growth_size, CHARSET_INFO
*charset,
ulong size, size_t key_offset, size_t key_length,
my_hash_get_key get_key,
void (*free_element)(void*), uint flags)
hash:初始化一个hash表
growth_size:初始化hash->array的增长大小
get_key:需要自定义一个从record获取key的方法,然后hash表针对这个key计算hash
free_element:hash中的元素,只记录data的指针,需要自己定义free的方法
2. my_hash_free_elements(HASH *hash)
根据hash->elements的值,从array的0到elements来释放hash_link中的data。
最后hash->elements置为0。
3. my_hash_key(const HASH *hash, const uchar *record, size_t
*length,
my_bool first)
根据record和hash中定义的get_key方法来获取key值。
4. my_hash_first(const HASH *hash, const uchar *key, size_t
length,
HASH_SEARCH_STATE *current_record)
根据key,length值来查找hash中的data。如果有hash冲突,就返回第一个。
5. my_hash_insert(HASH *info, const uchar *record)
插入record到hash表中:
1. 如果需要hash_unique,会先使用my_hash_search进行查询。
2. 然后计算cacl_hash&&hash_mask来计算位置。
6. my_hash_element(HASH *hash, ulong idx)
获取在hash表位置是idx的元素。
为完待续.....