标签:blog 可变 text jdk1.5 调用 null bin 数据存储 顺序
数组与集合的区别:
Java中的数组是存放同一类型数据的集合。数组可以存放基本数据类型的数据,也可以存放引用数据类型的数据,但数组的长度是固定的。
集合只能存放引用数据类型的数据,不能存放基本数据类型的数据,但集合的数目是可变的。
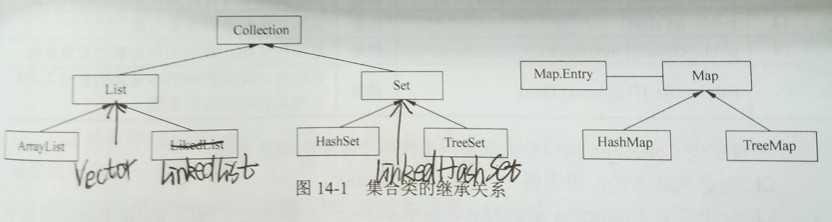
所有的集合类都存放在java.util包中
List接口是元素有序,可重复的集合,添加自定义类时需要重写equals()方法
ArrayList集合中,插入一个元素时,列表需要将插入点后面的所有元素向后移动,而在删除(remove())一个元素时,需要将被删除元素后面的所有元素向前移动
ArrayList集合允许所有的元素,包括null
例1:ArrayList的一些基本方法
public class ArrayListText{
public static void main(String[] args){
Collection<String> collection=new ArrayList<String>();
List<String> list=new ArrayList<String>();
collection.add("1");
collection.add("2");
collection.add("3");
list.add("A");
list.add("B");
list.add("C");
list.addAll(0,collection);//向指定位置添加一个集合的所有元素
System.out.println("list集合:"+list);
List<String> subList=list.subList(1,5);
System.out.println("subList集合:"+subList);
System.out.println("设置list集合元素前::"+list.get(3));
list.set(3,"Set");
System.out.println("设置list集合元素后::"+list.get(3));
System.out.println("list集合中,元素3的位置:"+list.indexOf("3")+",元素D的位置:"+list.indexOf("D"));//获取指定元素在集合中的索引位置,若不存在则返回-1
String arrString[]=list.toArray(new String[]{});//将集合转为字符串数组
for(String str:arrString){
System.out.print(str+" ");
}
System.out.println("\nlist集合是否为空:"+list.isEmpty());
list.clear();
System.out.println("\nlist集合是否为空:"+list.isEmpty());
}
}
结果:
list集合:[1,2,3,A,B,C]
subList集合:[2,3,A,B]
设置list集合元素前::A
设置list集合元素后::Set
list集合中,元素3的位置:2,元素D的位置:-1
1 2 3 Set B C
list集合是否为空:false
list集合是否为空:true
将数组转换为ArrayList集合
String[] str={"W","E","C","O","M","E"};
List<String> list=Arrays.asList(str);
ArrayList<String> arrList=new ArrayList<String>();
arrList.addAll(list);
LinkedList是链表类,链表结构的优点是便于向集合插入和删除元素。因为在插入或删除元素时,不需要移动任何元素,LinkedList也可以存在null元素
获取表头的方法:
getFirst():仅仅是获取表头 element():获取但不移除此链表头 peek():获取但不移除此链表头 poll():获取并移除此链表头 pop():获取并移除此链表头
例2:LinkedList获取链表头
public class LinkedListText{
public static void main(String[] args){
LinkedList<String> link=new LinkedList<String>();
link.add("1");
link.add("2");
link.add("3");
link.addFirst("F");
link.addLast("L");
LinkedList<String> newLink=new LinkedList<String>(link);
System.out.println("添加元素后:\n\t"+link);
System.out.println("get()方法获取表头:"+link.getFirst());
System.out.println("使用get()方法后:\n\t"+link);
System.out.println("element()方法获取表头:"+link.element());
System.out.println("使用element()方法后:\n\t"+link);
System.out.println("peek()方法获取表头:"+link.peek());
System.out.println("使用peek()方法后:\n\t"+link);
System.out.println("poll()方法获取表头:"+link.poll());
System.out.println("使用poll()方法后:\n\t"+link);
System.out.println("pop()方法获取表头:"+link.pop());
System.out.println("使用pop()方法后:\n\t"+link);
System.out.println("******使用链表的先进先出*******");
int len=newLink.size();
for(int i=0;i<len;i++){
System.out.print(newLink.poll()+" ");
}
}
}
结果:
添加元素后:
[F,1,2,3,L]
get()方法获取表头:F
使用get()方法后:
[F,1,2,3,L]
element()方法获取表头:F
使用element()方法后:
[F,1,2,3,L]
peek()方法获取表头:F
使用peek()方法后:
[F,1,2,3,L]
poll()方法获取表头:F
使用poll()方法后:
[1,2,3,L]
pop()方法获取表头:1
使用pop()方法后:
[2,3,L]
*****使用链表的先进先出*****
F 1 2 3 L
Set集合是元素无序,不可重复的集合,允许包含null元素,添加自定义类一定要重写equals()和hashcode()方法
HashSet类可以快速地定位一个元素,但放到HashSet集合中的元素需要重写equals()和hashcode()方法,而TreeSet集合将放进其中的元素按序存放
HashSet是按哈希算法来存放集合中的元素的,使用哈希算法可以提高存取的效率
HashSet集合的特点:1.不能保证元素的排列顺序,集合中元素的顺序随时有可能发生改变 2.集合中最多允许存在一个null元素 3.HashSet集合不是线程同步的
LinkedHashSet插入性能略低于HashSet,但在迭代访问Set里的全部元素时有很好的性能,LinkedHashSet()使用链表维护了一个添加进集合中的顺序,导致当我们遍历LinkedHashSet集合元素时是按添加进去的顺序遍历的,但不能说明它是有序的!
TreeSet类实现了java.util包中的Set接口和SortedSet接口,TreeSet集合中的元素在默认情况下是升序排序
TreeSet集合的特点:1.向TreeSet中添加的元素必须是同一个类的 2.从小到大遍历 3.自定义类没有实现Comparable接口时,当向TreeSet中添加此对象时,报错
例2:自定义类实现Comparable接口
class Person implements Comparable{
private String name;
private String age;
public Person(){
}
public Person(String name,int age){
this.name=name;
this.age=age;
}
public int compareTo(Person per){
if(this.age>per.age){
return 1;
}else if(this.age<per.age){
return -1;
}else{
return this.name.compareTo(per.name);
}
}
public String toString(){
return ("姓名:"+name+",年龄:"+age+"\n");
}
}
public class TreeSetDemo{
public static void main(String[] args){
Set<Person> tset=new TreeSet<Person>();
tset.add(new Person("小强",21));
tset.add(new Person("小伟",23));
tset.add(new Person("小强",21));
tset.add(new Person("小强",21));
tset.add(new Person("小琴",20));
tset.add(new Person("小婷",20));
System.out.println(tset);
}
}
结果:
[姓名:小婷,年龄:20
,姓名:小琴,年龄:20
,姓名:小强,年龄:21
,姓名:小伟,年龄:23
]
集合的输出:1.Iterator:迭代器输出(提供遍历各种集合类型的迭代器) 2.foreach:JDK1.5新增的输出
迭代删除:
Iterator<String> it=link.iterator();
while(it.hasNext){
it.next();
it.remove();
}
注释:在调用remove()方法前需要使用next()方法指定要删除的元素,否则运行时将产生IllegalStateException异常
Map接口提供的是key-value的映射,其中key不允许重复,每一个key只能映射一个value,常用String类作为Map的键
一个key-value对是一个Entry,所有的Entry是用Set存放的,不可重复。key是用Set来存放的,不可重复,value是用Collection存放的,可重复
Map.Entry接口是静态的,所以可以直接使用”外部类.内部类“的形式调用
HashMap类是实现Map集合,对于元素的添加和删除有着较高的效率。HashMap类提供所有可选的映射操作,并允许使用null值和null键,但必须保证键是唯一的,HashMap是非同步的,也不保证映射顺序
例3:获取Map集合中的全部key和value
public class HashMapDemo{
public static void main(String[] arg){
Map<Integer,String> map=new HashMap<Integet,String>();
map.put(1,"清华大学");
map.put(2,"北京大学");
map.put(3,"复旦大学");
map.put(4,"武汉大学");
map.put(5,"中国科技大学");
map.put(6,"中国矿业大学");
Set<Integer> set=map.keySet();
Iterator<Integet> itKey=set.iterator();
System.out.println("Map集合中全部的key:");
while(itKey.hasNext()){
System.out.print(itKey.next()+" ");
}
System.out.println();
Collection<String> c=map.values();
Iterator<String> itValue=c.iterator();
System.out.println("Map集合中全部的value:");
while(itValue.hasNext()){
System.out.print(itValue.next()+" ");
}
}
}
结果:
Map集合中全部的key:
1 2 3 4 5 6
Map集合中全部的value:
清华大学 北京大学 复旦大学 武汉大学 中国科技大学 中国矿工大学
例4:使用Iterator输出Map集合
public class hashMapDemo{
public static void main(String[] args){
Map<Integer,String> map=new HashMap<Integet,String>();
map.put(1,"清华大学");
map.put(2,"北京大学");
map.put(3,"复旦大学");
map.put(4,"武汉大学");
map.put(5,"中国科技大学");
map.put(6,"中国矿业大学");
Set<Map.Entry<Integer,String>> set=map.entrySet();
Iterator<Map.Entry<Integet,String>> it=set.iterator();
System.out.println("Key--------Value");
while(it.hasNext()){
Map.Entry<Integer,String> mapEntry=it.next();
System.out.println(""+mapEntry.getKey()+"-------"+mapEntry.getValue());
}
}
}
结果:
key------value
1-----清华大学
2-----北京大学
3-----复旦大学
4-----武汉大学
5-----中国科技大学
6-----中国矿业大学
使用foreach输出:
for(Map.Entry<Integet,String> mapEntry:map.entryKey()){
System.out.println(""+mapEntry.getKey()+"-------"+mapEntry.getValue());
}
TreeMap类不但实现了Map接口,还实现了SortedMap接口,因此,TreeMap集合中的映射关系具有一定的顺序性。与HashMap相比,TreeMap集合对元素的添加、删除和定位映射性能较低
Collections类可以对集合的元素进行排序、反序、去极值、循环移位、查询和修改等功能,还可以将集合对象设置不可变、对集合对象实现同步控制等方法。
Collections类所提供的方法均为静态方法,可以直接通过“类名.方法()"的形式调用
Collections常用方法:addAll(Collection c,T...elements)--Collections.addAll(list,"1","2","3") binarySearch(List list,T key)-使用此方法前必须先使用sort(List list,Comparator c)方法进行排序 copy(List dest,List src)//将src集合中的所有元素复制到dest集合中 fill(List list,T obj)//使用指定元素替换指定集合中的所有元素 max(Collection coll) max(Collection coll,Comparator c) replaceAll(List list,T oldVal,T newVal)//使用另一个元素替代集合中指定的所有元素 reverse(List list)
Stack-栈是一种特殊的线性表,它仅限于在表尾进行元素的添加与删除操作。栈的表尾成为栈顶,表头成为栈底。栈是采用“先进后出”的数据存储方式,若栈中没有任何元素,则成为空栈。栈是Vector的子类
empty()//判断该栈是否为空,若为空返回true peek()//获取栈顶元素,但不删除它 pop()//获取栈顶元素,并删除它 push()//将元素添加到栈顶中 search()、、查找指定元素在栈中位置,起始位置为1,不是0
Hashtable类是Map的子类,是JDK1.0是出现的,Hashtable类是同步的,线程安全的,不允许存放null键和null值,其他功能与HashMap类似
标签:blog 可变 text jdk1.5 调用 null bin 数据存储 顺序
原文地址:http://www.cnblogs.com/xiaoshimei/p/6227603.html