标签:取出 tween append 赋值 cto 组件 存在 any hosts
SQLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
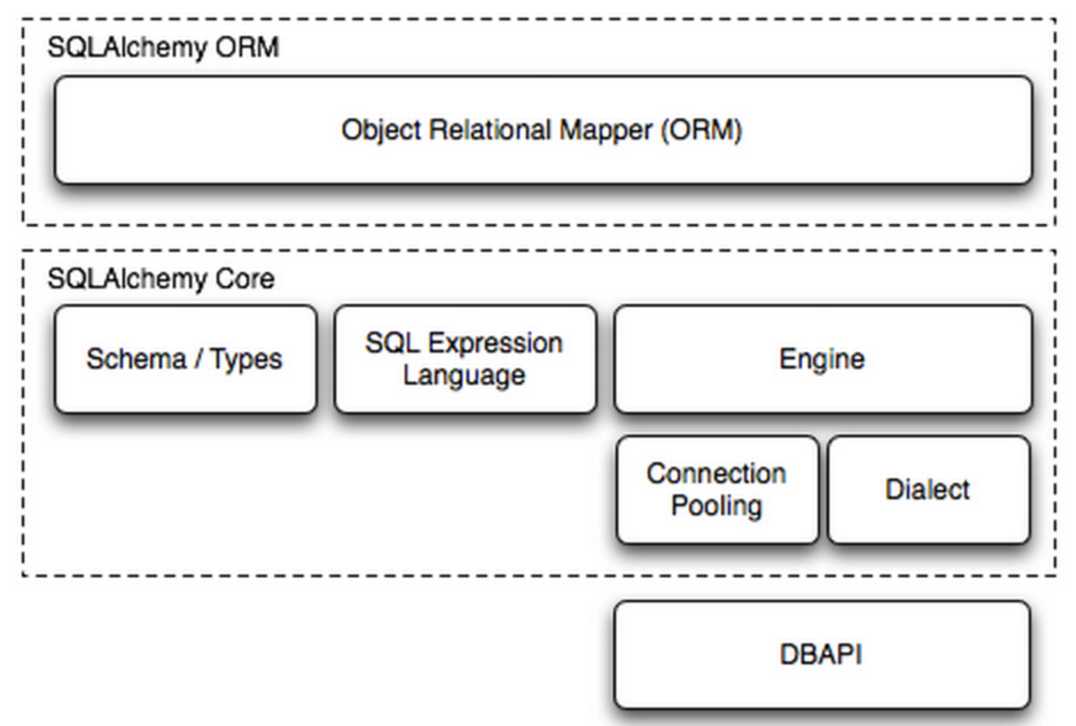
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html |
注意 :
1 写入数据库表汉字时候 需要加编码 charset=utf8
|
1
|
engine = create_engine(‘mysql+pymysql://root@127.0.0.1:3306/db2?charset=utf8‘) #1 连接已存在的数据库 |
2 查看执行输出 echo=true
|
1
|
engine = create_engine(‘sqlite:///dbyuan67.db‘, echo=True) |
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
#!/usr/bin/env python# -*- coding:utf-8 -*-from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) # 执行SQL# cur = engine.execute(# "INSERT INTO hosts (host, color_id) VALUES (‘1.1.1.22‘, 3)"# ) # 新插入行自增ID# cur.lastrowid # 执行SQL# cur = engine.execute(# "INSERT INTO hosts (host, color_id) VALUES(%s, %s)",[(‘1.1.1.22‘, 3),(‘1.1.1.221‘, 3),]# ) # 执行SQL# cur = engine.execute(# "INSERT INTO hosts (host, color_id) VALUES (%(host)s, %(color_id)s)",# host=‘1.1.1.99‘, color_id=3# ) # 执行SQL# cur = engine.execute(‘select * from hosts‘)# 获取第一行数据# cur.fetchone()# 获取第n行数据# cur.fetchmany(3)# 获取所有数据# cur.fetchall() |
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。


#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) Base = declarative_base() # 创建单表 class Users(Base): __tablename__ = ‘users‘ id = Column(Integer, primary_key=True) name = Column(String(32)) extra = Column(String(16)) __table_args__ = ( UniqueConstraint(‘id‘, ‘name‘, name=‘uix_id_name‘), Index(‘ix_id_name‘, ‘name‘, ‘extra‘), ) # 一对多 class Favor(Base): __tablename__ = ‘favor‘ nid = Column(Integer, primary_key=True) caption = Column(String(50), default=‘red‘, unique=True) class Person(Base): __tablename__ = ‘person‘ nid = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=True) favor_id = Column(Integer, ForeignKey("favor.nid")) # 多对多 class Group(Base): __tablename__ = ‘group‘ id = Column(Integer, primary_key=True) name = Column(String(64), unique=True, nullable=False) port = Column(Integer, default=22) class Server(Base): __tablename__ = ‘server‘ id = Column(Integer, primary_key=True, autoincrement=True) hostname = Column(String(64), unique=True, nullable=False) class ServerToGroup(Base): __tablename__ = ‘servertogroup‘ nid = Column(Integer, primary_key=True, autoincrement=True) server_id = Column(Integer, ForeignKey(‘server.id‘)) group_id = Column(Integer, ForeignKey(‘group.id‘)) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine)
ForeignKeyConstraint([‘other_id‘], [‘othertable.other_id‘]),
注意点:
1 类的__call__方法
对象加括号 即 对象() 就调用
|
1
2
|
Session = sessionmaker(bind=engine) #实例化 Session对象session = Session() # 对象加括号。 即 obj() 调用__call__方法 |
2 类的__repr__方法
当我们想要print(对象) 的时候,不想看到内存地址,而是要看对象封装的数据,比如self.name 等的值。就需要用到__repr__方法了
class Father(Base): __tablename__ = "father" id = Column(Integer,primary_key=True,nullable=False) name = Column(String(32)) age = Column(String(32)) son = relationship("Son") # 适合第二种插入数据的一对多方式 没有这条的话就需要按照第一种方式插入一对多数据 def __repr__(self): #打印对象的时候,就调用这里 ,我们可以直接打印对象 #只能return 字符串 return self.name + self.age
#!/usr/bin/env python # -*- coding:utf-8 -*- from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) Base = declarative_base() # 创建单表 class Users(Base): __tablename__ = ‘users‘ id = Column(Integer, primary_key=True) name = Column(String(32)) extra = Column(String(16)) __table_args__ = ( UniqueConstraint(‘id‘, ‘name‘, name=‘uix_id_name‘), Index(‘ix_id_name‘, ‘name‘, ‘extra‘), ) def __repr__(self): return "%s-%s" %(self.id, self.name) # 一对多 class Favor(Base): __tablename__ = ‘favor‘ nid = Column(Integer, primary_key=True) caption = Column(String(50), default=‘red‘, unique=True) def __repr__(self): return "%s-%s" %(self.nid, self.caption) class Person(Base): __tablename__ = ‘person‘ nid = Column(Integer, primary_key=True) name = Column(String(32), index=True, nullable=True) favor_id = Column(Integer, ForeignKey("favor.nid")) # 与生成表结构无关,仅用于查询方便 favor = relationship("Favor", backref=‘pers‘) # 多对多 class ServerToGroup(Base): __tablename__ = ‘servertogroup‘ nid = Column(Integer, primary_key=True, autoincrement=True) server_id = Column(Integer, ForeignKey(‘server.id‘)) group_id = Column(Integer, ForeignKey(‘group.id‘)) group = relationship("Group", backref=‘s2g‘) server = relationship("Server", backref=‘s2g‘) class Group(Base): __tablename__ = ‘group‘ id = Column(Integer, primary_key=True) name = Column(String(64), unique=True, nullable=False) port = Column(Integer, default=22) # group = relationship(‘Group‘,secondary=ServerToGroup,backref=‘host_list‘) class Server(Base): __tablename__ = ‘server‘ id = Column(Integer, primary_key=True, autoincrement=True) hostname = Column(String(64), unique=True, nullable=False) def init_db(): Base.metadata.create_all(engine) def drop_db(): Base.metadata.drop_all(engine) Session = sessionmaker(bind=engine) session = Session()
obj = Users(name="alex0", extra=‘sb‘) session.add(obj) session.add_all([ Users(name="alex1", extra=‘sb‘), Users(name="alex2", extra=‘sb‘), ]) session.commit()
|
1
2
|
session.query(Users).filter(Users.id > 2).delete()session.commit() |
session.query(Users).filter(Users.id > 2).update({"name" : "099"})
session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + "099"}, synchronize_session=False)
session.query(Users).filter(Users.id > 2).update({"num": Users.num + 1}, synchronize_session="evaluate")
session.commit()
ret = session.query(Users).all() ret = session.query(Users.name, Users.extra).all() ret = session.query(Users).filter_by(name=‘alex‘).all() ret = session.query(Users).filter_by(name=‘alex‘).first()
# 条件 ret = session.query(Users).filter_by(name=‘alex‘).all() ret = session.query(Users).filter(Users.id > 1, Users.name == ‘eric‘).all() ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == ‘eric‘).all() ret = session.query(Users).filter(Users.id.in_([1,3,4])).all() ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name=‘eric‘))).all() from sqlalchemy import and_, or_ ret = session.query(Users).filter(and_(Users.id > 3, Users.name == ‘eric‘)).all() ret = session.query(Users).filter(or_(Users.id < 2, Users.name == ‘eric‘)).all() ret = session.query(Users).filter( or_( Users.id < 2, and_(Users.name == ‘eric‘, Users.id > 3), Users.extra != "" )).all() # 通配符 ret = session.query(Users).filter(Users.name.like(‘e%‘)).all() ret = session.query(Users).filter(~Users.name.like(‘e%‘)).all() # 限制 ret = session.query(Users)[1:2] # 排序 ret = session.query(Users).order_by(Users.name.desc()).all() ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 分组 from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all() ret = session.query( func.max(Users.id), func.sum(Users.id), func.min(Users.id)).group_by(Users.name).all() ret = session.query( func.max(Users.id), func.sum(Users.id), func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() # 连表 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() ret = session.query(Person).join(Favor).all() ret = session.query(Person).join(Favor, isouter=True).all() # 组合 q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union(q2).all() q1 = session.query(Users.name).filter(Users.id > 2) q2 = session.query(Favor.caption).filter(Favor.nid < 2) ret = q1.union_all(q2).all()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
|
#!/usr/bin/env python#_*_coding:utf-8_*_import sqlalchemyfrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Indexfrom sqlalchemy.orm import sessionmaker, relationshipfrom sqlalchemy import create_engineengine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/db3?charset=utf8", max_overflow=5)Base = declarative_base() # 生成一个SQLORM 基类class Son(Base): __tablename__ = ‘son‘ id = Column(Integer,primary_key=True) name = Column(String(32)) # 创建普通索引index=True age = Column(String(32)) # 创建唯一索引 唯不为空可以为null unique=True father_id = Column(Integer,ForeignKey("father.id")) # def __repr__(self): # 打印对象的时候,就调用这里 ,我们可以直接打印对象 # # 只能return 字符串 # return self.name+str(self.age)class Father(Base): __tablename__ = "father" id = Column(Integer,primary_key=True,nullable=False) name = Column(String(32)) age = Column(String(32)) son = relationship("Son",backref=‘father‘) # 适合第二种插入数据的一对多方式 没有这条的话就需要按照第一种方式插入一对多数据 # def __repr__(self): #打印对象的时候,就调用这里 ,我们可以直接打印对象 # #只能return 字符串 # return self.name + str(self.age)# 1 创建 删除 表Base.metadata.create_all(engine) # 创建两个表# Base.metadata.drop_all(engine) # 删除两个表# 2 插入数据# #这两行触发sessionmaker类下的__call__方法,return得到 Session实例,赋给变量session,所以session可以调用Session类下的add,add_all等方法# 建立连接Session = sessionmaker(bind=engine)session = Session()#第一种 插入一对多关系第一种方法# f1 = Father(name="liujianzuo_1",age=22)# f2 = Father(name="liujianzuo_2",age=21)# # #先将 字典表的数据commit到数据库,否则建立多关系表的外键会报错# session.add(f1)# session.add(f2)# session.commit() # 先提交字典表的数据 防止son表建立数据 无对应外键关联# ## ## w1 = Son(name="little1 zuo 3",age=2,father_id=1)# w2 = Son(name="little zuo 4",age=3,father_id=2)# session.add_all([w1,w2])# session.commit()# # 第二种 上面的relationship应用,这种不用先提交字典表f3 = Father(name="liujianzuo",age=18)# #w1 = Son(name="little1 zuo 5",age=2,)w2 = Son(name="little zuo 6",age=3,)w3 = Son(name="little zuo w3",age=3,)## f3.son=[w1,w2] # son的relationship作用 如果是已经有 w1 w2 对象就需要f3.son# # 如果已经创建过关系,再次添加新的关系就要 f3.son.append(w3) 不然重新赋值 到这原来的 w1 w2 为null了关系#f3.son=[w1,w2]# session.add_all([f3,w1,w2]) #两种添加都行session.add_all([f3])session.commit()# 如果根据已经存储过的id的对应关系# 就不能用 f2.son= 了,后面我们打印了f2.son字段,是一个列表,如果继续=就会把 query取出的数据 清空,重新赋值,# 这样再add——all 数据的时候我们取出的id的对应关系的那条记录就没了。故此用appendf2 = session.query(Father).filter_by(id=1).first()print(f2,w1,w2)# exit()# f2.son=[w1,w2] # 错误f2.son.append(w1,w2)# session.add_all([f3,w1,w2])session.add_all([f3])session.commit()# 可以根据father对象查到关联的son信息是因为 relationship原因。# son = relationship("Son",backref=‘father‘)# 而 根据son 对象查到father信息我们也需要在Son类定义如下# father = relationship("Father",)# 但是如果我不想 就可以用backref了# son = relationship("Son",backref=‘father‘) 这句话是将Son类也加个映射为# father = relationship("Father",)# 省去重新定义# repr 显示print(f3.son) # 在son下定义 __repr__ 才能打印返回对象封装的字段for i in f3.son: # f3。son 是一个列表 print(i.name)# 单表跟连表查询# print(session.query(Father).all()) # [liujianzuo_122, liujianzuo_221] 不加all 是sql select * from father# print(session.query(Father.name,Son.name).join(Son).all())#[(‘liujianzuo_1‘, ‘little1 zuo 3‘), (‘liujianzuo_2‘, ‘little zuo 4‘)] # 不加all 是sql select * from father# print(session.query(Father.name.label("f_name"),Son.name.label("s_name")).join(Son))# lable 是字段别名设置# 不加all 是sql select * from father‘‘‘是如下语句 不加all()SELECT father.name AS f_name, son.name AS s_nameFROM father JOIN son ON father.id = son.father_id‘‘‘# 过滤查询 filter 是模糊 == in filter_byprint(session.query(Father).filter(Father.id.in_([1,])).all())# [liujianzuo_122] 模糊匹配id号 ,可以写多个print(session.query(Father).filter_by(id=2).all()) # [liujianzuo_221] |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
#!/usr/bin/env python# -*- coding:utf-8 -*-from sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Indexfrom sqlalchemy.orm import sessionmaker, relationshipfrom sqlalchemy import create_engine# engine = create_engine(‘sqlite:///dbyuan674uu.db‘, echo=True)engine = create_engine(‘mysql+pymysql://root:123456@127.0.0.1:3306/db1?charset=utf8‘) #1 连接已存在的数据库Base = declarative_base() #2 创建ORM的基类class Men_to_Wemon(Base): __tablename__ = ‘men_to_wemon‘ nid = Column(Integer, primary_key=True) men_id = Column(Integer, ForeignKey(‘men.id‘)) women_id = Column(Integer, ForeignKey(‘women.id‘))class Men(Base): __tablename__ = ‘men‘ id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) # gf= relationship("Women", secondary=Men_to_Wemon.__table__)class Women(Base): __tablename__ =‘women‘ id = Column(Integer, primary_key=True) name = Column(String(32)) age= Column(String(16)) bf=relationship("Men",secondary=Men_to_Wemon.__table__,backref=‘gf‘) # backref=‘gf‘ 相当于在men类定义了gf字段# 创建表# Base.metadata.create_all(engine) # 3 在数据库生成表# 删除表# Base.metadata.drop_all(engine) # 3 在数据库生成表# 插入数据Session = sessionmaker(bind=engine)session = Session()# 第一种 插入数据# 数据汉字报错。。。。未# m1=Men(name=‘alex‘,age=18)# m2=Men(name=‘xx‘,age=18)# w1=Women(name=‘ss‘,age=40)# w2=Women(name=‘cc‘,age=45)# session.add_all([m1,m2,w1,w2,])# session.commit()# t1=Men_to_Wemon(men_id=1,women_id=2) # 插入关系# session.add_all([t1,])# session.commit()# 第二种插入数据 一对多又讲过m1=session.query(Men).filter_by(id=2).first() # 查询id为2的男人print(m1)w1=session.query(Women).all() # 查询所有女人 为列表对象m1.gf=w1 # 设置绑定关系 2号男跟所有女人 此时关系表2号还没绑定 如果2好已经有关系绑定。这里也不是所有women 只是某一个元素的话,就需要是m1.gf.append(w1)了,如果w1是一个列表的话就要m1.gf.extend(w1)了session.add_all([m1,]) # 参考一对多 中的。session.commit()# 需要注意的地方:# 1 查询时如果不加all,first等,得到的是sql语句,加上后,才是具体的结果;而all的结果是一个列表。# 2 m1.gf是一个列表,里面存放着符合条件的对象。# 3 filter与filter_by的区别:filter是拿键值对的参数,filter_by是拿条件判断的参数。 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
from sqlalchemy import create_engine,and_,or_,func,Tablefrom sqlalchemy.ext.declarative import declarative_basefrom sqlalchemy import Column, Integer, String,ForeignKeyfrom sqlalchemy.orm import sessionmaker,relationshipengine = create_engine(‘mysql+pymysql://root@127.0.0.1:3306/com?charset=utf8‘)Base = declarative_base() #生成一个SqlORM 基类class HostToGroup(Base): __tablename__=‘host_2_group‘ nid=Column(Integer,primary_key=True) host_id=Column(Integer,ForeignKey("host.id")) group_id=Column(Integer,ForeignKey("group.id"))class Host(Base): __tablename__ = ‘host‘ id = Column(Integer,primary_key=True,autoincrement=True) hostname = Column(String(64),unique=True,nullable=False) ip_addr = Column(String(128),unique=True,nullable=False) port = Column(Integer,default=22) group = relationship(‘Group‘, secondary=HostToGroup.__table__, backref=‘host_list‘) #group =relationship("Group",back_populates=‘host_list‘) def __repr__(self): return "<id=%s,hostname=%s, ip_addr=%s>" %(self.id, self.hostname, self.ip_addr)class Group(Base): __tablename__ = ‘group‘ id = Column(Integer,primary_key=True) name = Column(String(64),unique=True,nullable=False) # host_list=relationship(‘Host‘ ,secondary=HostToGroup.__table__,) def __repr__(self): return "<id=%s,name=%s>" %(self.id,self.name)Base.metadata.create_all(engine) #创建所有表结构if __name__ == ‘__main__‘: SessionCls = sessionmaker(bind=engine) session = SessionCls() # # g1 = Group(name=‘g1‘) # g2 = Group(name=‘g2‘) # g3 = Group(name=‘g3‘) # g4 = Group(name=‘g4‘) # session.add_all([g1,g2,g3,g4]) # h1 = Host(hostname=‘h1‘,ip_addr=‘192.168.1.56‘) # h2 = Host(hostname=‘h2‘,ip_addr=‘192.168.1.57‘,port=10000) # h3 = Host(hostname=‘ubuntu‘,ip_addr=‘192.168.1.58‘,port=10000) # # # # session.add_all([h1,h2,h3]) # session.commit() # groups = session.query(Group).all() # h2 = session.query(Host).filter(Host.hostname==‘h2‘).first() # h2.group = groups[:-1] # print("===========>",h2.group) g4 = session.query(Group).filter(Group.name==‘g4‘).first() print(g4) obj1 = session.query(Host).filter(Host.hostname==‘h1‘).update({‘port‘:444}) h2= session.query(Host).filter(Host.hostname==‘h1‘).first() # g4.host_list.append(h2) # h2.group.append(g4) session.commit() |
标签:取出 tween append 赋值 cto 组件 存在 any hosts
原文地址:http://www.cnblogs.com/mosson/p/6257147.html
