标签:span 错误 not str 设备驱动 函数 处理过程 开始 没有
参考 http://www.yesky.com/20010813/192117.shtml
结构化程序设计思想认为:程序 = 数据结构 + 算法。数据结构体现了整个系统的构架,所以数据结构通常都是代码分析的很好的着手点,对Linux内核分析尤其如此。
比如,把进程控制块结构分析清楚了,就对进程有了基本的把握;
再比如,把页目录结构和页表结构弄懂了,两级虚存映射和内存管理也就掌握得差不多了。
为了体现循序渐进的思想,在这我就以Linux对中断机制的处理来介绍这种方法。
首先,必须指出的是:在此处,中断指广义的中断概义,它指所有通过idt进行的控制转移的机制和处理;它覆盖以下几个常用的概义:中断、异常、可屏蔽中断、不可屏蔽中断、硬中断、软中断 … … …
I、硬件提供的中断机制和约定
一.中断向量寻址:
硬件提供可供256个服务程序中断进入的入口,即中断向量;
中断向量在保护模式下的实现机制是中断描述符表idt,idt的位置由idtr确定,idtr是个48位的寄存器,高32位是idt的基址,低16位为idt的界限(通常为2k=256*8);
idt中包含256个中断描述符,对应256个中断向量;每个中断描述符8位,其结构如图一
二.异常处理机制:
Intel公司保留0-31号中断向量用来处理异常事件:当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,异常的处理程序由操作系统提供,中断向量和异常事件对应如表一:
表一、中断向量和异常事件对应表
| 中断向量号 | 异常事件 | Linux的处理程序 |
| 0 | 除法错误 | Divide_error |
| 1 | 调试异常 | Debug |
| 2 | NMI中断 | Nmi |
| 3 | 单字节,int 3 | Int3 |
| 4 | 溢出 | Overflow |
| 5 | 边界监测中断 | Bounds |
| 6 | 无效操作码 | Invalid_op |
| 7 | 设备不可用 | Device_not_available |
| 8 | 双重故障 | Double_fault |
| 9 | 协处理器段溢出 | Coprocessor_segment_overrun |
| 10 | 无效TSS | Incalid_tss |
| 11 | 缺段中断 | Segment_not_present |
| 12 | 堆栈异常 | Stack_segment |
| 13 | 一般保护异常 | General_protection |
| 14 | 页异常 | Page_fault |
| 15 | Spurious_interrupt_bug | |
| 16 | 协处理器出错 | Coprocessor_error |
| 17 | 对齐检查中断 | Alignment_check |
II、Linux的中断处理
硬件中断机制提供了256个入口,即idt中包含的256个中断描述符(对应256个中断向量)。
而0-31号中断向量被intel公司保留用来处理异常事件,不能另作它用。对这0-31号中断向量,操作系统只需提供异常的处理程序,当产生一个异常时,处理机就会自动把控制转移到相应的处理程序的入口,运行相应的处理程序;而事实上,对于这32个处理异常的中断向量,此版本(2.2.5)的Linux只提供了0-17号中断向量的处理程序,其对应处理程序参见表一、中断向量和异常事件对应表;也就是说,17-31号中断向量是空着未用的。
既然0-31号中断向量已被保留,那么,就是剩下32-255共224个中断向量可用。这224个中断向量又是怎么分配的呢?在此版本(2.2.5)的Linux中,除了0x80 (SYSCALL_VECTOR)用作系统调用总入口之外,其他都用在外部硬件中断源上,其中包括可编程中断控制器8259A的15个irq;事实上,当没有定义CONFIG_X86_IO_APIC时,其他223(除0x80外)个中断向量,只利用了从32号开始的15个,其它208个空着未用。
这些中断服务程序入口的设置将在下面有详细说明。
一.相关数据结构
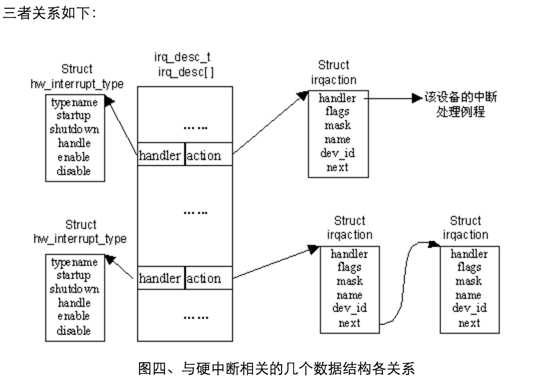
我的理解:handler指的是哪个处理器来处理这个;action是实际的处理例程。action会交给handler处理。不知道对不对。
http://www.yesky.com/20010813/192117_2.shtml
三. Bottom_half处理机制
在此版本(2.2.5)的Linux中,中断处理程序从概念上被分为上半部分(top half)和下半部分(bottom half);在中断发生时上半部分的处理过程立即执行,但是下半部分(如果有的话)却推迟执行。内核把上半部分和下半部分作为独立的函数来处理,上半部分决定其相关的下半部分是否需要执行。必须立即执行的部分必须位于上半部分,而可以推迟的部分可能属于下半部分。
那么为什么这样划分成两个部分呢?
由此可见,没有必要每次中断都调用下半部分;只有bh_mask 和 bh_active的对应位的与为1时,才必须执行下半部分(do_botoom_half)。所以,如果在上半部分中(也可能在其他地方)决定必须执行对应的半部分,那么可以通过设置bh_active的对应位,来指明下半部分必须执行。当然,如果bh_active的对应位被置位,也不一定会马上执行下半部分,因为还必须具备另外两个条件:首先是bh_mask的相应位也必须被置位,另外,就是处理的时机,如果下半部分已经标记过需要执行了,现在又再次标记,那么内核就简单地保持这个标记;当情况允许的时候,内核就对它进行处理。
如果在内核有机会运行其下半部分之前给定的设备就已经发生了100次中断,那么内核的上半部分就运行100次,下半部分运行1次。
内核中的某些底半处理过程是和特定设备相关的,而其他一些则更一般一些。表二列出了内核中通用的底半处理过程。
| TIMER_BH(定时器) | 在每次系统的周期性定时器中断中,该底半处理过程被标记为活动状态,并用来驱动内核的定时器队列机制。 |
| CONSOLE_BH(控制台) | 该处理过程用来处理控制台消息。 |
| TQUEUE_BH(TTY 消息队列) | 该处理过程用来处理 tty 消息。 |
| NET_BH(网络) | 用于一般网络处理,作为网络层的一部分 |
| IMMEDIATE_BH(立即) | 这是一个一般性处理过程,许多设备驱动程序利用该过程对自己要在随后处理的任务进行排队。 |
四.中断处理全过程
由前面的分析可知,对于0-31号中断向量,被保留用来处理异常事件;0x80中断向量用来作为系统调用的总入口点;而其他中断向量,则用来处理外部设备中断;这三者的处理过程都是不一样的。
标签:span 错误 not str 设备驱动 函数 处理过程 开始 没有
原文地址:http://www.cnblogs.com/charlesblc/p/6261741.html