标签:cas cat 中心 实验 ges output 规则 文字 str
Weilin Huang——【arXiv2016】Accurate Text Localization in Natural Image with Cascaded Convolutional Text Network
目录
- 作者和相关链接
- 背景介绍
- 方法概括
- 方法细节
- 实验结果
- 总结与收获点
- 参考文献
作者和相关链接

背景介绍
-
自底向上方法(bottom up)的一般流程
- Step 1: 用滑动窗口或者MSER/SWT等方法提取候选区域
- Step 2: 字符级分类器(SVM,CNN等)
- Step 3: 后处理,如文本线形成(字符聚类、字符分组),单词切割等
-
自底向上方法(bottom up)的缺点
- Step1一般使用的是低级特征(像素级),不够鲁棒,对于光强不均匀,形变较大等的目标都无法提取出候选区域
- Step1产生的候选区域往往很多,对后续字符级分类器的压力很大,且候选区域越多也会造成整体效率不高
- 后处理往往很复杂,需要很多人工的规则,参数,而且不通用,尤其当库的变化比较大时,参数很可能需要修改
- 多步的pipeline容易造成误差积累,且整体性能被每一步所限制
-
从传统方法到引入CNN方法后的改进
- 字符级CNN的缺点:unreliable, inefficient,complicated,not robust
- 改进思路一:从字符级CNN到字符串级CNN(文本线级CNN、文本块级CNN)
- 利用文本区域的上下文信息,更加鲁棒;
- 不再需要复杂的后处理,更加可靠通用;
- 改进思路二:修改CNN结构,从经典的Conv+pool+FC修改成FCN(全卷积)
- 计算共享,更加高效
- 去掉FC,可以处理各种尺度的输入
- CNN不再只是做分类,而且做回归,对位置也做regression
方法概括


Figure 1. Two-step coarse-to-fine text localization results by the proposed Cascaded Convolutional Text Network (CCTN). A coarse text network detects text regions (which may include multiple or single text lines) from an image, while a fine text network further refines the detected regions by accurately localizing each individual text line. The ORANGE bounding box indicates a detected region by the coarse text network. We have two options for each text region: (i) directly output the bounding box as a final detection (solid ORANGE); (ii) refine the detected region by the fine text network (dashed ORANGE), and generate an accurate location for each text line (RED solid central line). The refined regions may include multiple text lines or an ambiguous text line (e.g., very small-scale text).
-
- 本文的方法主要分两大步,先用一个coarse-CNN检测粗略的文字区域(文字块),如图Figure1中的黄色虚线部分;再用fine-CNN提取文字区域中的文本线,如图Figuire1的红线。图中的黄色实现表示有些coase CNN得到的文字区域可以直接作为text line输出。
-
关键点——对VGG16的修改成coarse/fine CNN
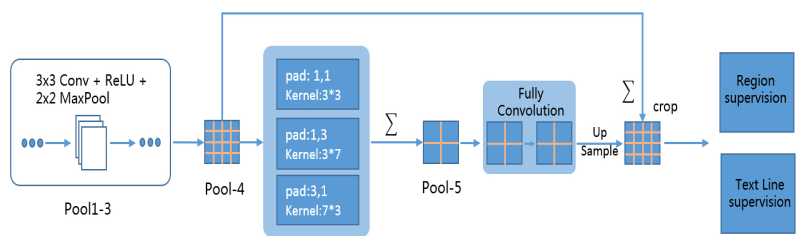
-
- 卷积核从3*3变成3种:3*7,3*3,7*3(多形状),并且多个卷积还是并行的,而不是连续的!
- 引入了2个1*1的fully convolution 代替了原来的fully connected层:输入图像大小可以任意,因为都是卷积,没有全连接
- 多个层进行融合(多尺度):pool5进行了2*2池化,所以最后要进行up sample之后才能和pool4进行融合
方法细节


coarse CNN(左图)和fine CNN(右图)用到的GT

coarse CNN的输出(b)和fine CNN的输出(e和f)
-
- coarse CNN的输入是整张图直接resize成500的,而fine CNN的输入是coase CNN得到的候选区域,但是候选区域需要进行在边界padding 50,并把整张图resize成500*500的。


Figure 3. (b) An resized 500×500 input image, and the actual receptive filed of new Pool-5, which is computed as the response area in the input image by propagating the error of a single
neuron in the new Pool-5.
- 对于coarse CNN得到的text region,如何判断是否要refine(跑fine CNN)还是直接输出为单个文本线?
- 对coarse CNN得到的heatmap进行二值化(阈值0.3)
- 计算图中的area ratio和borderline ratio,如果前者大于0.7,且后者大于5,则直接输出为单个文本线
- 否则要进行refine。先将图像按1.2倍crop下来,并按边界padding 50(0),整个patch块resize成500成500,输入到fine CNN中去进行refine得到更细致的文本线进行输出
- 对于fine CNN得到的两张heatmap,如何结合得到精确的text line(bounding box)输出?
- 每个heatmap都用MAR(minimum area rectangle)得到rectangle(text line的高度要乘2)
- 对两张heatmap得到的rectangle进行组合(怎么组合作者没提)得到精确的的文本线输出

实验结果
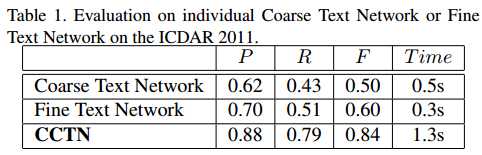
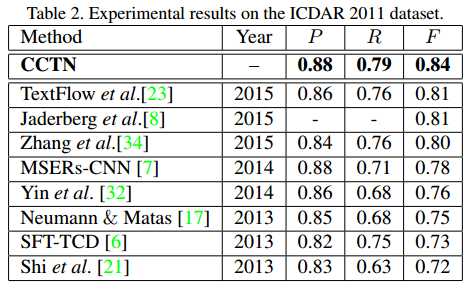
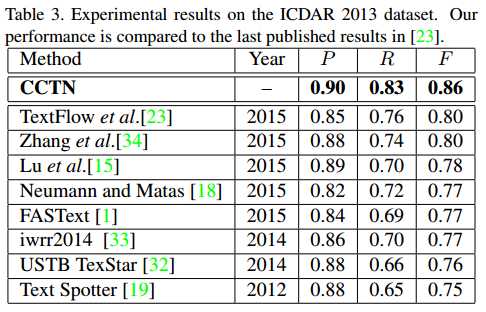
- 运行时间:1.3s
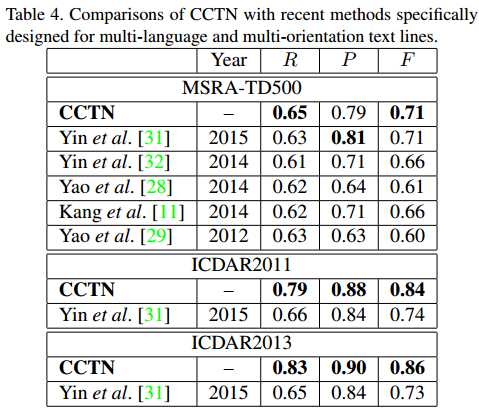
- coarse CNN和fine CNN对比

总结与收获点
- 本文的亮点有两点,第一是解决问题的思路从bottom up的pipeline改成了现在流行的top down,先检测候选的文本块区域,再在粗略的文本区域中找出更精细的文本线。这种方法鲁棒性,可靠性,效率,方法的复杂度都更好。第二个亮点在于把传统的CNN改造成可以用来检测文字区域,改进的点在修改卷积核长宽比,引入全卷积代替全连接,多层融合这三点。
论文阅读(Weilin Huang——【arXiv2016】Accurate Text Localization in Natural Image with Cascaded Convolutional Text Network)
标签:cas cat 中心 实验 ges output 规则 文字 str
原文地址:http://www.cnblogs.com/lillylin/p/6276889.html