标签:生成 put 分布 freelist text 分析 产生 类型 range
收到一封告警邮件:
Load average on xxx_server reached critical threshold values - 169.5
Current Load Avg = 169.5
是个生产环境的,
于是立马登上服务器看下状况
top - 05:01:00 up 88 days, 5:03, 4 users, load average: 185.10, 200.94, 193.27
Tasks: 3442 total, 172 running, 3269 sleeping, 0 stopped, 1 zombie
Cpu(s): 96.3%us, 2.8%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.9%si, 0.0%st
Mem: 527990848k total, 465240080k used, 62750768k free, 1593680k buffers
Swap: 31457276k total, 0k used, 31457276k free, 51934560k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
24225 oracle 20 0 256g 38m 29m R 68.8 0.0 16:31.12 oracle
34187 oracle 20 0 256g 37m 26m R 68.2 0.0 25:36.82 oracle
47581 oracle 20 0 256g 40m 27m R 68.2 0.0 226:48.02 oracle
35919 oracle 20 0 256g 44m 29m R 66.4 0.0 484:24.28 oracle
37934 oracle 20 0 256g 42m 29m R 64.8 0.0 460:41.09 oracle
24227 oracle 20 0 256g 43m 30m R 63.9 0.0 477:54.11 oracle
10826 oracle 20 0 256g 44m 30m R 63.0 0.0 518:04.92 oracle
64990 oracle 20 0 256g 148m 30m R 62.7 0.0 960:40.23 oracle
26610 oracle 20 0 256g 33m 26m R 60.2 0.0 5:10.04 oracle
31533 oracle 20 0 256g 37m 27m R 59.9 0.0 25:29.96 oracle
56682 oracle 20 0 256g 41m 30m R 59.3 0.0 443:13.79 oracle
39668 oracle 20 0 256g 37m 26m R 58.6 0.0 27:16.07 oracle
看了好几次,cpu的使用率一直是95%以上,前二十个都是oracle相关的进程,于是立马看下这些进程是什么sql在执行些什么
先随便找了一个cpu占比比较高的spid来看
select a.sid, a.serial#,a.username, a.osuser, b.spid,a.status
from v$session a, v$process b
where a.paddr= b.addr
and b.spid=40514
order by a.sid;
SID SERIAL# USERNAME OSUSER SPID STATUS
---------- ---------- ------------------------------ ------------------------------ ------------------------ --------
2793 883 MSP_ALL_DML app 40514 ACTIVE
SQL_TEXT
----------------------------------------------------------------
UPDATE SYNC_PROCESSING_STATUS
SET STATUS_IND = :1 , RETRY_COUNT = :2 ,
ERROR_MSG = :3 , UPDATE_DATE = :4
WHERE SYNC_ID = :5 AND PROCESS_TYPE = :6
AND CREATE_DATE > sysdate-7
而后又找了一两个占比比较高的spid,同样也是在执行这个sql
再具体看下数据库有哪些正在执行的session
SID SERIAL# SQL_ID Run_in_sec OS_user MACHINE
---------- ---------- ------------- ---------- ------------------------------ ----------------------------------------------------------------
SQL_TEXT
-----------------------------------------------
MODULE EVENT
---------------------------------------------------------------- ----------------------------------------------------------------
6826 13187 0vqfhz794y0ys 7 app xxxx_appserver
UPDATE SYNC_PROCESSING_STATUS SET STATUS_IND = :1 , RETRY_COUNT = :2 , ERROR_MSG = :3 , UPDATE_DATE = :4 WHERE SYNC_ID = :5 AND PROCESS_TYPE = :6 AND CREATE_DATE > sysdate-7
JDBC Thin Client latch free
10990 20293 0vqfhz794y0ys 7 app xxxxx_appserver
UPDATE SYNC_PROCESSING_STATUS SET STATUS_IND = :1 , RETRY_COUNT = :2 , ERROR_MSG = :3 , UPDATE_DATE = :4 WHERE SYNC_ID = :5 AND PROCESS_TYPE = :6 AND CREATE_DATE > sysdate-7
JDBC Thin Client latch free
10994 18173 0vqfhz794y0ys 7 app xxxxx_appserver
UPDATE SYNC_PROCESSING_STATUS SET STATUS_IND = :1 , RETRY_COUNT = :2 , ERROR_MSG = :3 , UPDATE_DATE = :4 WHERE SYNC_ID = :5 AND PROCESS_TYPE = :6 AND CREATE_DATE > sysdate-7
JDBC Thin Client latch free
6457 48363 0vqfhz794y0ys 7 app xxx_appserver
UPDATE SYNC_PROCESSING_STATUS SET STATUS_IND = :1 , RETRY_COUNT = :2 , ERROR_MSG = :3 , UPDATE_DATE = :4 WHERE SYNC_ID = :5 AND PROCESS_TYPE = :6 AND CREATE_DATE > sysdate-7
JDBC Thin Client latch free
(output还有很多,这里省略)
看到了基本上全是在执行这个sql,active的session大概170个左右在执行这个。
于是跑去OEM看了下执行计划,
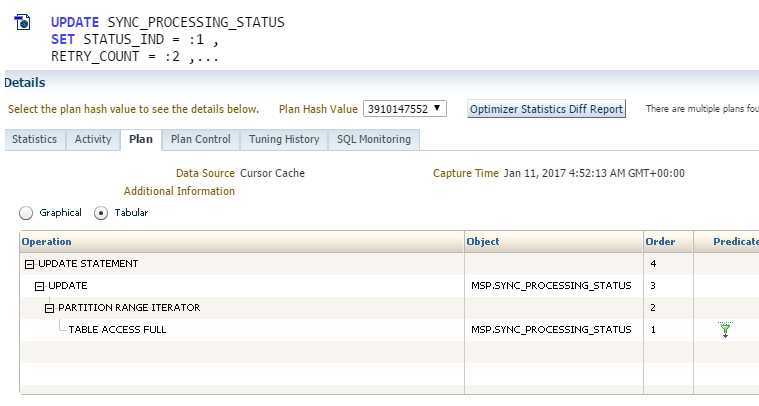
正在做全表扫描。
注意到了关键的一点,plan hash value有两个,于是猜测是不是执行计划变了导致的sql执行很慢,太多的session造成了热点快,从而造成了latch free的等待事件,从而cpu暴涨。
但是当时没有认证去分析latch的根源。
继续看了一下,
以前走的是index range scan,现在走的是full table scan。
并且关键的信息在于这张表的统计信息还是在2015年时候的,
execute dbms_stats.gather_table_stats(ownname=> ‘xx‘, tabname=> ‘SYNC_PROCESSING_STATUS‘, estimate_percent=> 5, cascade => true, degree => ‘8‘,NO_INVALIDATE => false);
在收集完统计信息之后,load正常了,cpu也降下去了。
==============ENDED====================================
问题就这样处理了,但是当时还是可以挖掘更多信息的,比如这个latch free的等待事件的分析,
这个事件会由很多的原因造成的,这里列举如下:
Shared pool 和library cache latch争用原因
Shared pool和library cache latch争用通常是由于硬分析引起。硬分析需要分配新的游标,或者将已经换出的游标重新执行。硬分析过多说明sql语句没有充分绑定变量。硬分析是代价十分昂贵的操作,在分析期间需要一直持有ibrary cache latch。
如果你的系统中存在大量的常量sql语句,当你将它们改为充分使用绑定变量后,对sharedpool latch和library cache latch的争用将会显著减少。更改sql语句,使用绑定变量,这通常需要修改应用程序。
Sharedpool latch争用原因二―― 过大的共享池
从oracle9i起,由于引入了多个子共享池的特性,过大的共享池不再是一种坏事。在9i之前,过大的共享池通常会引起sharedpool latch争用。共享池中可用内存分成不同的内存块(chunk),不同大小范围的块由不同的可用列表(freelist)来管理。在共享池中分配空间时,需要扫描可用列表,扫描期间,需要持有shared pool latch。过大的共享池会使得可用列表过长,从而使得sharedpool latch的持有时间变长。在高并发环境中,latch持有时间过长就可能造成latch争用(表现为较高的sleeps和misses值),尤其是大量使用常量sql的系统,对这样的系统,不要一味想着加大共享池,更重要的是想一想你为什么会需要保存这么多不能共享的语句到共享池中。
Library cache latch争用原因三――语句版本数过多
对于字符完全一致但是由于引用不同的对象而不能共享的sql语句,oracle使用多个子游标来指向该语句的不同版本。例如,系统中有三个名叫customer的表,但是属于不同的模式。则对于语句select * from customer,不同的模式执行该语句,语句字符上完全一样,其hash值完全一样,但是该语句无法共享,因为它引用的对象不同。所以会生成该语句的不同子版本。当一个sql语句有多个子版本时,oracle需要比较该语句的所有存在的子版本,在此期间需要持有librarycache latch,这样可能导致library cache latch争用。解决这种情况也很简单,在系统中,尽量不要使用相同的对象名。
Cache buffers chains latch
Cache buffers chains latch争用原因一 ―― 低效的sql语句
低效的sql语句是导致cache bufferschains latch争用的主要原因。在高并发系统中, atch free时间可能因此非常明显。典型的情况是,应用程序开启多个并发会话执行相同的低效sql,并且访问同样的数据集。
注意下面三点:
1.每次逻辑读都需要请求一次latch。
2.只有获得某个latch之后才会停止对该latch的不断请求。
3.在某个时刻,只有一个进程可以获得cache buffers chains latch,而该latch可能用于保护很多的数据块,其中的某些块可能正在被其他进程请求(当然,前面也已经提过,oracle9i允许只读性质的cache bufferschains latch共享)。
一般而言,较少的逻辑读意味着较少的latch请求,也就意味着较少的latch争用和更好的系统性能。所以,你应该找出导致cache bufferschains latch争用的低效sql语句,优化这些语句,尽量降低其逻辑读。那些buffers_get/executions比值较大的sql可能就是你需要调整的语句。
Cache buffers chains latch争用原因二―― 热点块
热点块是导致cache bufferschains latch争用的另外一个主要原因。当多个进程重复访问一个或多个由同一个cache buffers chains latch保护的块时会导致该问题。这通常是应用程序引起的。在这种情况下,增加cache bufferschains latch的个数对热点块导致的争用没有什么作用。因为数据块分布在哪个hash bucket和hash chain上是由块地址(dba:data block address)和hash bucket的个数决定的,和hash latch的个数没有关系。只要块地址和hash bucket数没有改变,这些热点块还是会分布在原来的hash bucket和hash chain上,还是由原来的hash latch保护,那么就还会对这些hash latch产生争用。除非系统中latch数目显著的增加(这样每个latch管理的hash bucket就会很少,甚至一个latch管理一个hash bucket,这样原来的热点块可能就会有其他的几个latch来管理,而不再需要争用原来的那个latch)。
解决这样的cache bufferschains latch争用,最好的方法是找出热点块。通过latch free等待事件的p1raw参数可以知道是否是因为热点块导致了latch争用。(在oracle10g中,cache buffers chains latch的相关等待事件不再是latchfree,而是cachebuffers chains)。P1raw参数是latch的地址。如果多个会话都在等待同一个latch地址,那么恭喜你遇到热点块问题了。
Cache buffers chains latch争用原因三―― 过长的hash chain
多个数据块可能分配到同一个hash bucket上。这些块组成一个链表(hash chain)。在一个大型系统中,一个hash bucket中可能有上百个数据块。从一个hash chain链表中搜索某个块,需要获得cache bufferschains latch,串行的进行。如果链表太长,使得latch持有时间相应增加,可能导致其他进程请求cache buffers chains latch失败。
-----------------------------------------------------------------------
如果要进一步分析的话,可以用如下sql来看下这个latch的具体信息
v$session的latch free等待事件p2就是指的latch的类型,然后用如下sql查看latch类型
SELECT LATCH#, NAME FROM V$LATCH WHERE LATCH# = 98;
SELECT * FROM V$LATCHHOLDER;
SQL>select latch#,name,gets,misses,sleeps from v$latch where name like ‘cache buffer%‘;
在这个查询结果里我们可以看到记录了数据库启动以来的所有cahce buffer chains的latch的状况,gets表示总共有这么多次请求,misses表示请求失败的次数(加锁不成功),而sleeps 表示请求失败休眠的次数,通过sleeps我们可以大体知道数据库中latch的竞争是否严重,这也间接的表征了热点块的问题是否严重。由于v$latch是一个聚合信息,我们并不能获得哪些块可能存在频繁访问。那我们要来看另一个view信息,那就是v$latch_children,v$latch_children.addr记录的就是这个latch的地址。
SQL>select addr,LATCH#,CHILD#,gets,misses,sleeps from v$latch_children where name = ‘cache buffers chains‘ and rownum < 21;
主要分析latch free等待事件的就是这些v$latch,v$latchholder,v$latch_children,v$latchname,v$latch_parent这么几个视图,以后有时间再详细分析一下这几个视图的用法,以及从latch去确定某个block热点块的思路。
============================
当然关于这种执行计划突变的原因也有很多,本例是因为统计信息的原因,也有很多其他原因,比如比较常见的绑定变量窥探(数据量突变)等等,以后遇到了在具体分析。
在事后又大致看了一下,后续的sql执行计划也都走的是index range scan这个hash plan value为1107144300的执行计划了
SQL> SELECT DISTINCT sql_id, plan_hash_value
2 FROM dba_hist_sqlstat q
3 WHERE SNAP_ID BETWEEN 130811 AND 130812
AND q.sql_id=‘0vqfhz794y0ys‘; 4
SQL_ID PLAN_HASH_VALUE
------------- ---------------
0vqfhz794y0ys 3910147552
0vqfhz794y0ys 1107144300
select SQL_ID,first_load_time,EXECUTIONS,LOADS,PARSE_CALLS from v$sqlarea where sql_id=‘0vqfhz794y0ys‘;
select sql_id,plan_hash_value, child_number, executions, parse_calls, buffer_gets, is_bind_sensitive, is_bind_aware from v$sql where sql_id = ‘‘;
==========================ENDED===================================
标签:生成 put 分布 freelist text 分析 产生 类型 range
原文地址:http://www.cnblogs.com/deff/p/6288245.html