标签:xtend integer 10个 国内 main [1] idt 表达 title
Linux下C语言正则表达式使用详解 - Google Chrome (2013/5/2 16:40:37)
Linux下C语言正则表达式使用详解
标准的C和C++都不支持正则表达式,但有一些函数库可以辅助C/C++程序员完成这一功能,其中最著名的当数Philip Hazel的Perl-Compatible Regular Expression库,许多Linux发行版本都带有这个函数库。
C语言处理正则表达式常用的函数有regcomp()、regexec()、regfree()和regerror(),一般分为三个步骤,如下所示:
C语言中使用正则表达式一般分为三步:
1. 编译正则表达式 regcomp()
2. 匹配正则表达式 regexec()
3. 释放正则表达式 regfree()
下边是对三个函数的详细解释
1. int regcomp (regex_t *compiled, const char *pattern, int cflags)
这个函数把指定的正则表达式pattern编译成一种特定的数据格式compiled,这样可以使匹配更有效。函数regexec 会使用这个数据在目标文本串中进行模式匹配。执行成功返回0。
参数说明:
①regex_t 是一个结构体数据类型,用来存放编译后的正则表达式,它的成员re_nsub 用来存储正则表达式中的子正则表达式的个数,子正则表达式就是用圆括号包起来的部分表达式。
②pattern 是指向我们写好的正则表达式的指针。
③cflags 有如下4个值或者是它们或运算(|)后的值:
REG_EXTENDED 以功能更加强大的扩展正则表达式的方式进行匹配。
REG_ICASE 匹配字母时忽略大小写。
REG_NOSUB 不用存储匹配后的结果。
REG_NEWLINE 识别换行符,这样‘$‘就可以从行尾开始匹配,‘^‘就可以从行的开头开始匹配。
2. int regexec (regex_t *compiled, char *string, size_t nmatch, regmatch_t matchptr [], int eflags)
当我们编译好正则表达式后,就可以用regexec 匹配我们的目标文本串了,如果在编译正则表达式的时候没有指定cflags的参数为REG_NEWLINE,则默认情况下是忽略换行符的,也就是把整个文本串当作一个字符串处理。执行成功返回0。
regmatch_t 是一个结构体数据类型,在regex.h中定义:
typedef struct
{
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
成员rm_so 存放匹配文本串在目标串中的开始位置,rm_eo 存放结束位置。该函数虽然以regmatch_t数组的形式定义了参数,但是实际上regexec()函数只能匹配到一个,让人误解啊,特别注明一下。
参数说明:
①compiled 是已经用regcomp函数编译好的正则表达式。
②string 是目标文本串。
③nmatch 是regmatch_t结构体数组的长度。
④matchptr regmatch_t类型的结构体数组,存放匹配文本串的位置信息。
⑤eflags 有两个值
REG_NOTBOL 按我的理解是如果指定了这个值,那么‘^‘就不会从我们的目标串开始匹配。总之我到现在还不是很明白这个参数的意义;
REG_NOTEOL 和上边那个作用差不多,不过这个指定结束end of line。
3. void regfree (regex_t *compiled)
当我们使用完编译好的正则表达式后,或者要重新编译其他正则表达式的时候,我们可以用这个函数清空compiled指向的regex_t结构体的内容,请记住,如果是重新编译的话,一定要先清空regex_t结构体。
4. size_t regerror (int errcode, regex_t *compiled, char *buffer, size_t length)
当执行regcomp 或者regexec 产生错误的时候,就可以调用这个函数而返回一个包含错误信息的字符串。
参数说明:
①errcode 是由regcomp 和 regexec 函数返回的错误代号。
②compiled 是已经用regcomp函数编译好的正则表达式,这个值可以为NULL。
③buffer 指向用来存放错误信息的字符串的内存空间。
④length 指明buffer的长度,如果这个错误信息的长度大于这个值,则regerror 函数会自动截断超出的字符串,但他仍然会返回完整的字符串的长度。所以我们可以用如下的方法先得到错误字符串的长度。
size_t length = regerror (errcode, compiled, NULL, 0);
下边是一个连续查找文本中匹配字符串的例子:
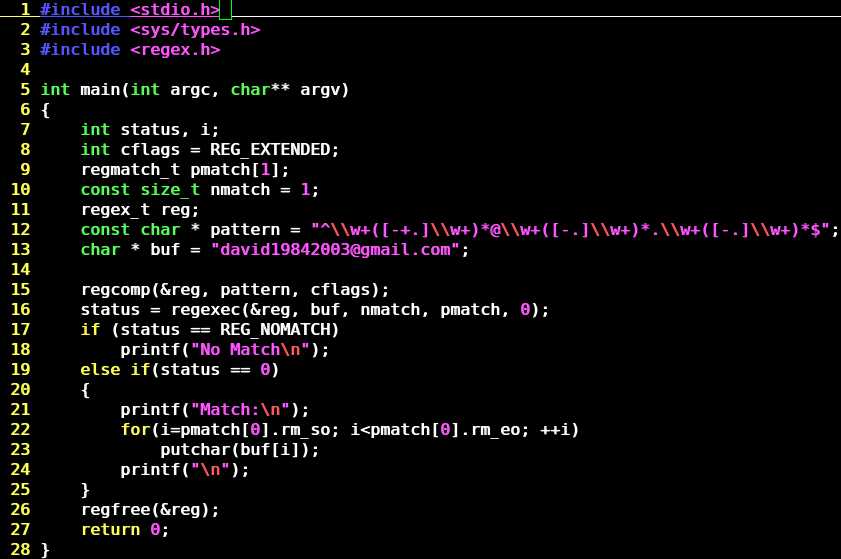
#include <stdio.h>
#include <string.h>
#include <regex.h>
// 提取子串
char* getsubstr(char *s, regmatch_t *pmatch)
{
static char buf[100] = {0};
memset(buf, 0, sizeof(buf));
memcpy(buf, s+pmatch->rm_so, pmatch->rm_eo - pmatch->rm_so);
return buf;
}
int main(void)
{
regmatch_t pmatch;
regex_t reg;
const char *pattern = "[a-z]+"; // 正则表达式
char buf[] = "HELLOsaiYear2012@gmail.com"; // 待搜索的字符串
regcomp(®, pattern, REG_EXTENDED); //编译正则表达式
int offset = 0;
while(offset < strlen(buf))
{
int status = regexec(®, buf + offset, 1, &pmatch, 0);
/* 匹配正则表达式,注意regexec()函数一次只能匹配一个,不能连续匹配,网上很多示例并没有说明这一点 */
if(status == REG_NOMATCH)
printf("No Match\n");
else if(pmatch.rm_so != -1)
{
printf("Match:\n");
char *p = getsubstr(buf + offset, &pmatch);
printf("[%d, %d]: %s\n", offset + pmatch.rm_so + 1, offset + pmatch.rm_eo, p);
}
offset += pmatch.rm_eo;
}
regfree(®); //释放正则表达式
return 0;
} |
正则表达式梳理(unix) - aten_xie的专栏 - 博客频道 - CSDN.NET - Google Chrome (2013/4/16 18:14:01)
分类: SHELL2011-03-04 22:51 945人阅读 收藏 举报 正则表达式(regular experience RE)是一种字符模式,用于在查找过程中匹配指定的字符。在大多数程序中,正则表达式都被置于两个正斜杠之间。例如:/test/ 就是由正斜杠界定的正则表达式,它将匹配被查找的行中任何位置出现的相同模式。
正则表达式元字符
元字符是这样一类字符,它们表达的是不同于字面本身的含义。正则表达式元字符是由各种执行模式匹配操作的程序来解析,例如:sed、grep、awk等。
常用正则表达式的元字符如下:
| 元字符 | 功能 | 实例 | 匹配结果 | 备注 |
| ^ | 行首定位符 | /^test/ | 匹配所有以test开头的行 | 空格、TAB等也是作为字符进行匹配的。 |
| $ | 行尾定位符 | /test$/ | 匹配所有以test结尾的行 | |
| . (点) | 匹配除“/n”之外的任何单个字符 | /t..t/ | 匹配包含一个t,后跟两个字符,在跟一个t的行。 | 任意单个字符包含空格和TAB键。
即:“t t” 也是满足匹配条件的。
若要匹配包括“/n”在内的任意字符,请使用诸如“[/s/S]”之类的模式。 |
| * | 零次或多次匹配前面的字符或子表达式 | /t*est/ | 匹配包含0个或者多个t后跟est的行。可以匹配:est、test、ttest | |
| + | 一次或多次匹配前面的字符或子表达式 | /t+est/ | 匹配包含1个或者多个t后跟est的行。可以匹配:test、ttest。字符串“est”则无法进行匹配了。 | |
| ? | 零次或者一次匹配前面的字符串或者子表达式 | /t?est/ | 匹配包含0个或者1个t后跟est的行。可以匹配:test、est。 | ttest 也是符合匹配标准的,因为ttest字符串中包含整个test。
当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是“非贪心的”。“非贪心的”模式匹配搜索到的、尽可能短的字符串,而默认的“贪心的”模式匹配搜索到的、尽可能长的字符串。例如,在字符串“oooo”中,“o+?”只匹配单个“o”,而“o+”匹配所有“o”。 |
| [] | 匹配一组字符中的任一个 | /[Tt]est/ | 匹配包含Test或者test行 | |
| [x-y] | 匹配指定范围内的一个字符 | /[A-Z]est/ | 匹配后面跟着est的一个A至Z之间的字符。 | [0-9]:用来匹配任意数字
[A-Za-z]:用来匹配任意字母 |
| [^] | 匹配不在指定组内的字符 | /[^A-Z]/ | 匹配不在范围A至Z之间的任一个字符 | |
| / | 用来转义元字符 | /test/*/ | 匹配包含test,后面跟一个*号的所有行。 | ////用来匹配“/”符号自身 |
| /< | 词首定位符 | // | 匹配包含以love开头的词的行。如:love、lover | vi和grep支持 |
| /> | 词尾定位符 | /love/>/ | 匹配包含以love结尾的词的行。
如:aalove | vi和grep支持 |
| /(pattern/) | 匹配模式pattern,并将之存储在寄存器中,供之后使用。 | //(love/)able /1r/ | 最多可以使用9个标签,模式中最左边的标签是第一个。例如:模式love被保存为标签1,用/1表示。左边这个例子中,查找串是一个loveable 后跟 lover的长串。 | sed、vi、grep支持。
例如:
sed “s//(love/)//1able/” 功能是将文件中的love替换成loveable。 |
x/{m/} 或
x/{m,/} 或
x/{m,n/} | 字符x的重复出现;
m次,至少m次,至少m次且不超过n次。 | o/{5,10/} | 匹配包含5-10个连续的字母o的行。 | vi和grep支持 |
grep支持的正则表达式元字符
| 元字符 | 功能 | 实例 | 匹配结果 | 备注 |
| ^ | 行首定位符 | grep “^test” datafile | 打印所有以test开头的行 | |
| $ | 行尾定位符 | grep “test$” datafile | 打印所有以test结尾的行 | |
| . (点) | 匹配除“/n”之外的任何单个字符 | /t..t/ | 匹配包含一个t,后跟两个字符,在跟一个t的行。 | |
| * | 零次或多次匹配前面的字符或子表达式 | /t*est/ | 匹配包含0个或者多个t后跟est的行。可以匹配:est、test、ttest | |
| [] | 匹配一组字符中的任一个 | /[Tt]est/ | 匹配包含Test或者test行 | |
| [^] | 匹配不在指定组内的字符 | /[^A-Z]/ | 匹配不在范围A至Z之间的任一个字符 | |
| /< | 词首定位符 | // | 匹配包含以love开头的词的行。如:love、lover | vi和grep支持 |
| /> | 词尾定位符 | /love/>/ | 匹配包含以love结尾的词的行。
如:aalove | vi和grep支持 |
| /(pattern/) | 匹配模式pattern,并将之存储在寄存器中,供之后使用。 | //(love/)able /1r/ | 最多可以使用9个标签,模式中最左边的标签是第一个。例如:模式love被保存为标签1,用/1表示。左边这个例子中,查找串是一个loveable 后跟 lover的长串。 | sed、vi、grep支持。
例如:
sed “s//(love/)//1able/” 功能是将文件中的love替换成loveable。 |
x/{m/} 或
x/{m,/} 或
x/{m,n/} | 字符x的重复出现;
m次,至少m次,至少m次且不超过n次。 | o/{5,10/} | 匹配包含5-10个连续的字母o的行。 |
C语言正则表达式详解 regcomp() regexec() regfree()详解_正则表达式教程 - Google Chrome (2013/4/10 12:09:15)
C语言中嵌入正则表达式
常用正则表达式-月光博客 - Google Chrome (2013/4/10 10:09:16)
正则表达式用于字符串处理、表单验证等场合,实用高效。现将一些常用的表达式收集于此,以备不时之需。
匹配中文字符的正则表达式:
[\u4e00-\u9fa5]
评注:匹配中文还真是个头疼的事,有了这个表达式就好办了
匹配双字节字符(包括汉字在内):[^\x00-\xff]
评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)
匹配空白行的正则表达式:\n\s*\r
评注:可以用来删除空白行
匹配HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*?
/>
评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力
匹配首尾空白字符的正则表达式:^\s*|\s*$
评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式
匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
评注:表单验证时很实用
匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
评注:网上流传的版本功能很有限,上面这个基本可以满足需求
匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
评注:表单验证时很实用
匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}
评注:匹配形式如
0511-4405222 或 021-87888822
匹配腾讯QQ号:[1-9][0-9]{4,}
评注:腾讯QQ号从10000开始
匹配中国邮政编码:[1-9]\d{5}(?!\d)
评注:中国邮政编码为6位数字
匹配身份证:\d{15}|\d{18}
评注:中国的身份证为15位或18位
匹配ip地址:\d+\.\d+\.\d+\.\d+
评注:提取ip地址时有用
匹配特定数字:
^[1-9]\d*$
//匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$
//匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 +
0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$
//匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$
//匹配负浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
//匹配浮点数
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 +
0)
^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$ //匹配非正浮点数(负浮点数 +
0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
评注:最基本也是最常用的一些表达式
原载地址:http://lifesinger.3322.org/myblog/?p=185
本文章要提供的这些表达式是url
卡号 数字 邮编 QQ号 整数 英文 中文正则代码哦,下面我们来一一注明吧。
Url
: /^http://[A-Za-z0-9]+.[A-Za-z0-9]+[/=?%-&_~`@[]‘:+!]*([^<>""])*$/,
//地址正则
IdCard
: /^d{15}(d{2}[A-Za-z0-9])?$/, //卡号正则
Currency
: /^d+(.d+)?$/,
Number
: /^d+$/, //数字
Zip
: /^[1-9]d{5}$/, //邮编
QQ
: /^[1-9]d{4,8}$/, //QQ正则
Integer
: /^[-+]?d+$/,
Double
: /^[-+]?d+(.d+)?$/,
English
: /^[A-Za-z]+$/, //英语
Chinese
: /^[u0391-uFFE5]+$/, 汉字
Username
: /^[a-z]w{3,}$/i,
UnSafe
: /^(([A-Z]*|[a-z]*|d*|[-_~!@#$%^&*.()[]{}<>?\/‘"]*)|.{0,5})$|s/,
linux C regex正则表达式函数库 - crocodile的记录空间 - 51CTO技术博客 - Google Chrome (2013/4/1 13:53:29)
C中的正则表达式如何实现呢,以regex系列函数来简要说明:
标准的linux c与c++不支持正则表达式;
以POSIX函数库中的Regex系列函数来说明在Linux c下如何使用正则表达式:
1、编译正则表达式:
Regcomp函数,生成regex_t数据结构;
int Regcomp(regex_t *preg, const char *regex, int cflags);
参数说明:
preg:用来保存编译的结果;
regex:字符串,表示被编译的正则表达式;
cflags:编译开关控制细节;
REG_EXTEND代表使用扩展正则表达式模式;
REG_ICASE表示对规则中字符串不区分大小写;
REG_NOSUB只检查是否有符合规则的子串
2、匹配正则表达式:
利用regcomp生成的数据结构regex_t *preg 调用regexec()函数完成模式匹配:
int regexec(
const regex_t *preg,
const char *string,
size_t match,
regmatch_t pmatch[],
int eflags
);
typedef struct {
regoff_t rm_so;
regoff_t rm_eo;
} regmatch_t;
参数说明:
preg:用来编译后的模式匹配数据结构regex_t 常量;
string:字符串,表示被匹配的字符串;
nmatch:被匹配的个数;
pmatch:匹配的结果数组;
rm_so 表示满足规则的子串在string中的起始偏移量
rm_eo 表示满足规则的子串在string中的后续偏移量
eflags:匹配的特性
REG_NOTBOL 是否是第一行
REG_NOTEOL 是否是最后一行
3、报告错误信息
size_t regerror(int errcode, const regex_t *preg, char *errbuf, size_t errbuf_size);
参数说明:
errcode:来自regcomp及regexec函数的错误代码;
preg:regcomp编译结果;
errbuf:缓冲区的错误信息字符串;
errbuf_size:缓存区的错误信息字符串长度;
4、释放正则表达式:
void regfree(regex_t *preg);
无返回结果,释放regcomp编译的regex_t指针;
5、正则表达式框架:
int mymatch(char *buf)
{
const char *regex = "href=\"[^ >]*\"";
regex_t preg;
const size_t nmatch = 10;
regmatch_t pm[nmatch];
if (regcomp(&preg, regex, 0) != 0) { /*编译正则表达式失败 */
perror("regcomp");
exit(1);
}
int z, i;
z = regexec(&preg, buf, nmatch, pm, 0);
if (z == REG_NOMATCH)/*无匹配项 */
{
return 0;
}
else/*有匹配的超链接 */
{
for (i = 0; i < nmatch && pm[i].rm_so != -1; ++i)/*把超链接都提取出*/
{
/*对匹配链接的操作*/
}
}
regfree(&preg);/*释放正则表达式*/
}
6、正则表达式实例:
#include <stdio.h>
#include <sys/types.h>
#include <regex.h>
#include <string.h>
static char* substr(const char*str, unsigned start, unsigned end)
{
unsigned n = end - start;
static char stbuf[256];
strncpy(stbuf, str + start, n);
stbuf[n] = 0;
return stbuf;
}
int main(int argc, char** argv)
{
char * pattern;
int x, z, lno = 0, cflags = 0;
char ebuf[128], lbuf[256];
regex_t reg;
regmatch_t pm[10];
const size_t nmatch = 10;
pattern = argv[1];
z = regcomp(®, pattern, cflags);
if (z != 0)
{
regerror(z, ®, ebuf, sizeof(ebuf));
fprintf(stderr, "%s: pattern ‘%s‘ \n", ebuf, pattern);
return 1;
}
while(fgets(lbuf, sizeof(lbuf), stdin))
{
++lno;
if ((z = strlen(lbuf)) > 0 && lbuf[z-1] == ‘\n‘)
lbuf[z - 1] = 0;
z = regexec(®, lbuf, nmatch, pm, 0);
if (z == REG_NOMATCH) continue;
else if (z != 0)
{
regerror(z, ®, ebuf, sizeof(ebuf));
fprintf(stderr, "%s: regcom(‘%s‘)\n", ebuf, lbuf);
return 2;
}
for (x = 0; x < nmatch && pm[x].rm_so != -1; ++ x)
{
if (!x) printf("d: %s\n", lno, lbuf);
printf(" $%d=‘%s‘\n", x, substr(lbuf, pm[x].rm_so, pm[x].rm_eo));
}
}
regfree(®);
return 0;
}
编译执行
bitwangbin@mac:~/code/c/regex > gcc regexp.c -o regexp
bitwangbin@mac:~/code/c/regex > ./regexp ‘regex[a-z]*‘ < regexp.c
0003: #include <regex.h>;
$0=‘regex‘
0020: regex_t reg;
$0=‘regex‘
0037: z = regexec(®, lbuf, nmatch, pm, 0);
$0=‘regexec‘
笔记整理——Linux下C语言正则表达式
标签:xtend integer 10个 国内 main [1] idt 表达 title
原文地址:http://www.cnblogs.com/stlong/p/6289107.html