标签:pre 指定 字段排序 where 映射 sql查询 四种 更新 比较
最近在开发jSqlBox过程中,研究树形结构的操作,突然发现一种新的树结构数据库存储方案,在网上找了一下,没有找到雷同的(也可能是花的时间不够),现介绍如下: 目前常见的树形结构数据库存储方案有以下四种,但是都存在一定问题:
1)Adjacency List::记录父节点。优点是简单,缺点是访问子树需要遍历,发出许多条SQL,对数据库压力大。
2)Path Enumerations:用一个字符串记录整个路径。优点是查询方便,缺点是插入新记录时要手工更改此节点以下所有路径,很容易出错。
3)Closure Table:专门一张表维护Path,缺点是占用空间大,操作不直观。
4)Nested Sets:记录左值和右值,缺点是复杂难操作。
以上方法都存在一个共同缺点:操作不直观,不能直接看到树结构,不利于开发和调试。
本文介绍的方法我暂称它为“简单粗暴多列存储法”,它与Path Enumerations有点类似,但区别是用很多的数据库列来存储一个占位符(1或空值),如下图(https://github.com/drinkjava2/Multiple-Columns-Tree/blob/master/treemapping.jpg) 左边的树结构,映射在数据库里的结构见右图表格:
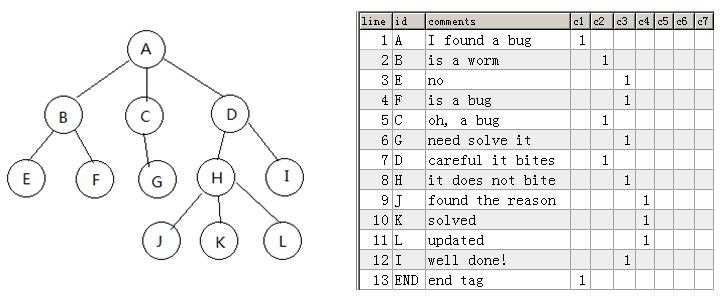
各种SQL操作如下:
1.获取(或删除)指定节点下所有子节点,已知节点的行号为"X",列名"cY":
select *(or delete) from tb where
line>=X and line<(select min(line) from tb where line>X and (cY=1 or c(Y-1)=1 or c(Y-2)=1 ... or c1=1))
例如获取D节点及其所有子节点:
select * from tb where line>=7 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
删除D节点及其所有子节点:
delete from tb where line>=7 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
仅获取D节点的次级所有子节点:
select * from tb where line>=7 and c3=1 and line< (select min(line) from tb where line>7 and (c2=1 or c1=1))
2.查询指定节点的根节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<=X and c1=1)
例如查I节点的根节点:
select * from tb where line=(select max(line) from tb where line<=12 and c1=1)
3.查询指定节点的上一级父节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<X and c(Y-1)=1)
例如查L节点的上一级父节点:
select * from tb where line=(select max(line) from tb where line<11 and c3=1)
3.查询指定节点的所有父节点, 已知节点的行号为"X",列名"cY":
select * from tb where line=(select max(line) from tb where line<X and c(Y-1)=1)
union select * from tb where line=(select max(line) from tb where line<X and c(Y-2)=1)
...
union select * from tb where line=(select max(line) from tb where line<X and c1=1)
例如查I节点的所有父节点:
select * from tb where line=(select max(line) from tb where line<12 and c2=1)
union select * from tb where line=(select max(line) from tb where line<12 and c1=1)
4.插入新节点:
视需求而定,例如在J和K之间插入一个新节点T:
update tb set line=line+1 where line>=10;
insert into tb (line,id,c4) values (10,‘T‘,1)
这是与Path Enumerations模式最大的区别,插入非常方便,只需要利用SQL将后面的所有行号加1即可,无须花很大精力维护path字串,
不容易出错。
另外如果表非常大,为了避免update tb set line=line+1 造成全表更新,影响性能,可以考虑增加
一个GroupID字段,同一个根节点下的所有节点共用一个GroupID,所有操作均在groupID组内进行,例如插入新节点改为:
update tb set line=line+1 where groupid=2 and line>=8;
insert into tb (groupid,line,c4) values (2, 8,‘T‘)
因为一个groupid下的操作不会影响到其它groupid,对于复杂的增删改操作甚至可以在内存中完成操作后,一次性删除整个group的内容
并重新插入一个新group即可。
总结:
以上介绍的这种方法优点有:
1)直观易懂,方便调试,是所有树结构数据库方案中唯一所见即所得,能够直接看到树的形状的方案,空值的采用使得树形结构一目了然。
2)SQL查询、删除、插入非常方便,没有用到Like语法。
3)只需要一张表
4)兼容所有数据库
5)占位符即为实际要显示的内容应出现的地方,方便编写Grid之类的表格显示控件
缺点有
1)不是无限深度树,数据库最大允许列数有限制,通常最多为1000,这导致了树的深度不能超过1000,而且考虑到列数过多对性能也有影响, 使用时建议定一个比较小的深度限制例如100。
2)SQL语句比较长,很多时候会出现c9=1 or c8=1 or c7=1 ... or c1=1这种n阶乘式的查询条件
3)树的节点整体移动操作比较麻烦,需要将整个子树平移或上下称动,当节点须要经常移动时,不建议采用这种方案。对于一些只增减,不常移动节点的应用如论坛贴子和评论倒比较合适。
4)列非常多时,空间占用有点大。
突 然发现上面的方法还是太笨了,如果不用多列而是只用一个列来存储深度等级,则可以不受数据库列数限制,从而进化为无限深度树,虽然不再具有所见即所得的效 果,但是在性能和简单性上要远远超过上述“简单粗暴多列存储法”,暂时给它取名"朱氏深度树V2.0法"(备注:如果已有人发明了这个方法,删掉前两个字 就好了),方法如下: 如下图 (https://github.com/drinkjava2/Multiple-Columns-Tree/blob/master/treemappingv2.png) 左边的树结构,映射在数据库里的结构见右图表格,注意每个表格的最后一行必须有一个END标记,level设为0:
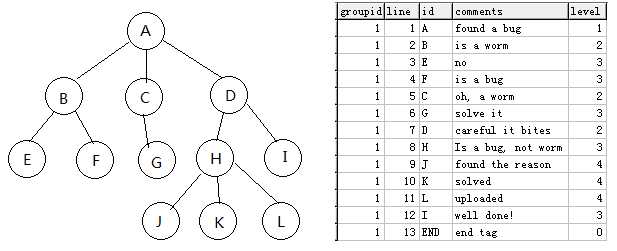
1.获取指定节点下所有子节点,已知节点的行号为X,level为Y, groupID为Z
select * from tb2 where groupID=Z and
line>=X and line<(select min(line) from tb where line>X and level<=Y and groupID=Z)
例如获取D节点及其所有子节点:
select * from tb2 where groupID=1 and
line>=7 and line< (select min(line) from tb2 where groupid=1 and line>7 and level<=2)
删除和获取相似,只要将sql中select * 换成delete即可。
仅获取D节点的次级所有子节点:(查询条件加一个level=Y+1即可):
select * from tb2 where groupID=1 and
line>=7 and level=3 and line< (select min(line) from tb2 where groupid=1 and line>7 and level<=2)
2.查询任意节点的根节点, 已知节点的groupid为Z
select * from tb2 where groupID=Z and line=1 (或level=1)
3.查询指定节点的上一级父节点, 已知节点的行号为X,level为Y, groupID为Z
select * from tb2 where groupID=Z and
line=(select max(line) from tb2 where groupID=Z and line<X and level=(Y-1))
例如查L节点的上一级父节点:
select * from tb2 where groupID=1
and line=(select max(line) from tb2 where groupID=1 and line<11 and level=3)
4.查询指定节点的所有父节点, 已知节点的行号为X,深度为Y:
select * from tb2 where groupID=Z and
line=(select max(line) from tb2 where groupID=Z and line<X and level=(Y-1))
union select * from tb2 where groupID=Z and
line=(select max(line) from tb2 where groupID=Z and line<X and level=(Y-2))
...
union select * from tb2 where groupID=Z and
line=(select max(line) from tb2 where groupID=Z and line<X and level=1)
例如查I节点的所有父节点:
select * from tb2 where groupID=1 and
line=(select max(line) from tb2 where groupID=1 and line<12 and level=2)
union select * from tb2 where groupID=1 and
line=(select max(line) from tb2 where groupID=1 and line<12 and level=1)
5.插入新节点:例如在J和K之间插入一个新节点T:
update tb2 set line=line+1 where groupID=1 and line>=10;
insert into tb (groupid,line,id,level) values (1,10,‘T‘,4);
总结: 此方法优点有:
1) 是无限深度树
2) 虽然不象第一种方案那样具有所见即所得的效果,但是依然具有直观易懂,方便调试的特点。
3) 能充分利用SQL,查询、删除、插入非常方便,SQL比第一种方案简单多了,也没有用到like模糊查询语法。
4) 只需要一张表。
5) 兼容所有数据库。
6) 占用空间小
缺点有:
1)树的节点整体移动操作有点麻烦, 适用于一些只增减,不常移动节点的场合如论坛贴子和评论等。当确实需要进行复杂的移动节点操作时,一种方案是在内存中进行整个树的操作并完成排序,操作完成后删除整个旧group再整体将新group一次性批量插入数据库。
1月22日补充:
节点的移动操作有点麻烦,只是相对于查询/删除/插入来说,并不是说难上天了。例如在MySQL下移动整个B节点树到H节点下,并位于J和K之间的操作如下:
update tb2 set tempno=line*1000000 where groupid=1;
set @nextNodeLine=(select min(line) from tb2 where groupid=1 and line>2 and level<=2);
update tb2 set tempno=9*1000000+line, level=level+2 where groupID=1 and line>=2 and line< @nextNodeLine;
set @mycnt=0;
update tb2 set line=(@mycnt := @mycnt + 1) where groupid=1 order by tempno;
上例需要在表中新增一个名为tempno的整数类型列, 这是个懒人算法,虽然简单明了,但是对整棵树进行了重新排序,所以效率并不高。 在需要频繁移动节点的场合下,用Adjacency List方案可能更合适一些。
如 果需要频繁移动节点的场合,又想保留方案2高效查询的优点,还有一种方案就是再添加一个父节点pid字段和两个辅助字段tempno和 temporder用于排序,(暂时称其为“深度树V3.0法"), 这样相当于V2.0法和Adjacency List模式的合并了,优点是每次移动节点,只需要更改PID即可,不需要复杂的算法,一次可以任意移动、增加、删除多个节点,最后统一调用以下算法简单 地进行一下重排序即可,下面这个示例完整演示了一个Adjacency List模式到V2.0模式的转换,这相当于一个重新给树建查询索引的过程:
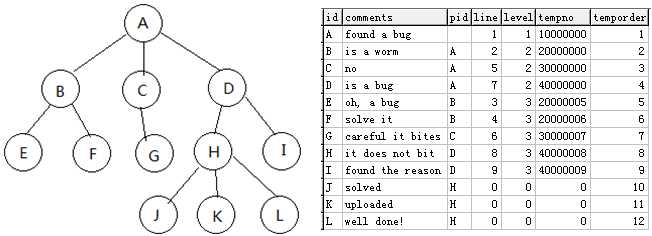
create table tb3 ( id varchar(10), comments varchar(55), pid varchar(10), line integer, level integer, tempno bigint, temporder integer ) insert into tb3 (id,comments,Pid) values(‘A‘,‘found a bug‘,null); insert into tb3 (id,comments,Pid) values(‘B‘,‘is a worm‘,‘A‘); insert into tb3 (id,comments,Pid) values(‘C‘,‘no‘,‘A‘); insert into tb3 (id,comments,Pid) values(‘D‘,‘is a bug‘,‘A‘); insert into tb3 (id,comments,Pid) values(‘E‘,‘oh, a bug‘,‘B‘); insert into tb3 (id,comments,Pid) values(‘F‘,‘solve it‘,‘B‘); insert into tb3 (id,comments,Pid) values(‘G‘,‘careful it bites‘,‘C‘); insert into tb3 (id,comments,Pid) values(‘H‘,‘it does not bit‘,‘D‘); insert into tb3 (id,comments,Pid) values(‘I‘,‘found the reason‘,‘D‘); insert into tb3 (id,comments,Pid) values(‘J‘,‘solved‘,‘H‘); insert into tb3 (id,comments,Pid) values(‘K‘,‘uploaded‘,‘H‘); insert into tb3 (id,comments,Pid) values(‘L‘,‘well done!‘,‘H‘); set @mycnt=0; update tb3 set line=0,level=0, tempno=0, temporder=(@mycnt := @mycnt + 1) order by id; update tb3 set level=1, line=1 where pid is null; update tb3 set tempno=line*10000000 where line>0; update tb3 a, tb3 b set a.level=2, a.tempno=b.tempno+a.temporder where a.level=0 and a.pid=b.id and b.level=1; set @mycnt=0; update tb3 set line=(@mycnt := @mycnt + 1) where level>0 order by tempno; update tb3 set tempno=line*10000000 where line>0; update tb3 a, tb3 b set a.level=3, a.tempno=b.tempno+a.temporder where a.level=0 and a.pid=b.id and b.level=2; set @mycnt=0; update tb3 set line=(@mycnt := @mycnt + 1) where level>0 order by tempno; update tb3 set tempno=line*10000000 where line>0; update tb3 a, tb3 b set a.level=4, a.tempno=b.tempno+a.temporder where a.level=0 and a.pid=b.id and b.level=3; set @mycnt=0; update tb3 set line=(@mycnt := @mycnt + 1) where level>0 order by tempno;
以上算法利用了SQL的功能,将原来可能需要非常多SQL递归查询的过程转变成了有限次数(=树最大深度)的SQL操作,为了突出算法,以上示例
假设只有一个根节点,删除了groupid和endtag,实际使用中要完善一下这个细节, order by
id也可改成以其它字段排序。因时间关系我就不给出V2.0模式到Adjacency
List模式逆推的算法了(也即pid为空,根据V2.0表格倒过来给pid赋值的过程),不过这个算法倒不重要,因为通常v3.0表中每一行会一直保存
着一个pid)。
总结一下:
Adjacency List模式:移/增/删节点方便,查询不方便
深度树V2.0模式:查询方便,增/删节点方便,但存在效率问题,移动节点不方便
深度树V3.0模式:移/增/删节点方便,查询方便,缺点是每次移/增/删节点后要重建line和level值以供查询用。它是结合了上两种模式
的合并体,并可以根据侧重,随时在这两种模式(修改模式和查询模式)间切换。v3.0法相当于给Adjacency List模式设计了一个查询索引。
标签:pre 指定 字段排序 where 映射 sql查询 四种 更新 比较
原文地址:http://www.cnblogs.com/drinkjava2/p/6344161.html
{kind=link}
{kind=link}