标签:-- 如图所示 span ges tin count distinct style partition
1.partition by和order by
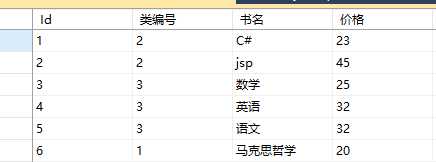
先看三个小需求:
①查询出各个类编号的书本的数量。
select count (类编号) as 数量, 类编号 from Books group by 类编号
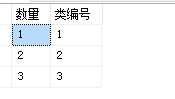
结果如图所示,这个时候用的是group by。
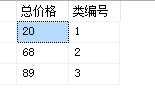
②查询出每一类编号中书的单价和。(例子:类编号为2的书的单价和)
select distinct sum (价格) over(partition by 类编号 order by 类编号 ) as 总价格 ,类编号 from Books
结果如图所示,用的是partition by。
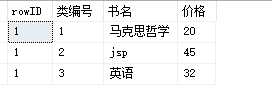
③查询出每一类编号中价格最高的一本书。
select * from ( select ROW_NUMBER() over(partition by 类编号 order by 价格 desc) as rowID,类编号,书名,价格 from Books ) a where rowid=1 --切记一定要给括号里面的数据集合起一个别名,要不然一直报错
结果如下图所示,
看完三个例子之后,总结一下:
group by是对检索结果的保留行进行单纯分组,一般总爱和聚合函数一块用例如AVG(),COUNT(),max(),main()等一块用。 而结果返回的一般只有一条反映统计值的记录
partition by用于给结果集分组,能返回一个分组中的多条记录。
标签:-- 如图所示 span ges tin count distinct style partition
原文地址:http://www.cnblogs.com/sdadx/p/6344810.html