标签:传递 instance let profile jar 参数 track ant pre
1. 开发环境
Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6.2 Hadoop 2.6.4 IntelliJ IDEA 2016.1.1
2. 创建项目
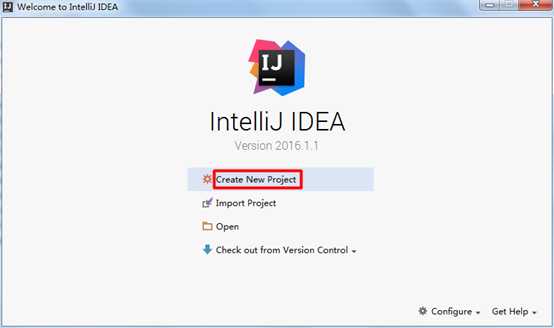
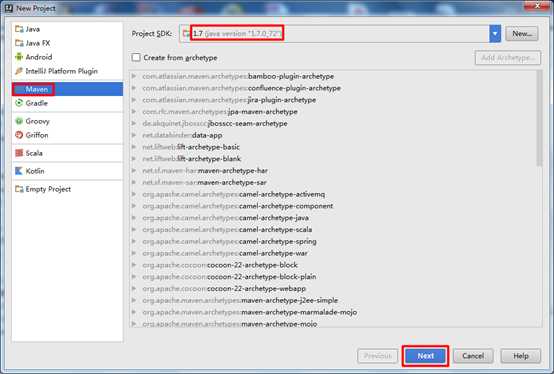
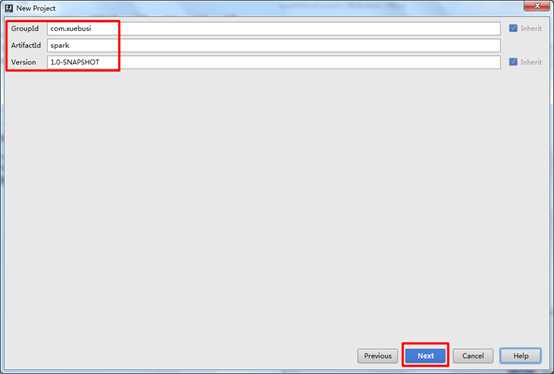
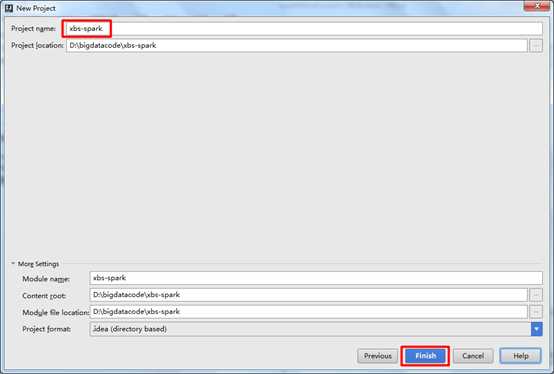
1) 新建Maven项目
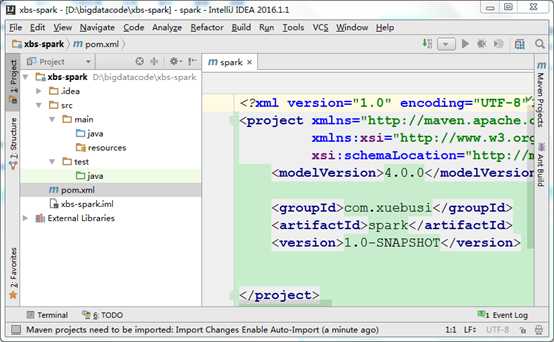
2) 在pom文件中导入依赖
pom.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.xuebusi</groupId> <artifactId>spark</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <encoding>UTF-8</encoding> <!-- 这里对jar包版本做集中管理 --> <scala.version>2.10.6</scala.version> <spark.version>1.6.2</spark.version> <hadoop.version>2.6.4</hadoop.version> </properties> <dependencies> <dependency> <!-- scala语言核心包 --> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <!-- spark核心包 --> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> </dependency> <dependency> <!-- hadoop的客户端,用于访问HDFS --> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-make:transitive</arg> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <!-- 由于我们的程序可能有很多,所以这里可以不用指定main方法所在的类名,我们可以在提交spark程序的时候手动指定要调用那个main方法 --> <!-- <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.xuebusi.spark.WordCount</mainClass> </transformer> </transformers> --> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
虽然我们的pom文件中的jar包依赖准备好了,但是在Project的External Libraries缺少Maven依赖:
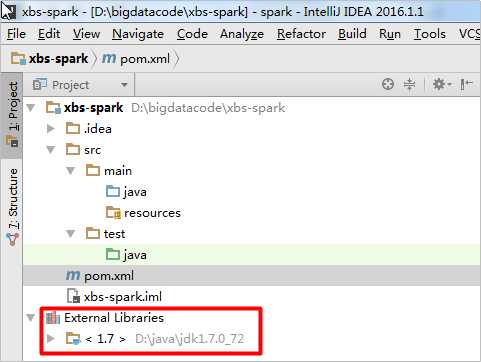
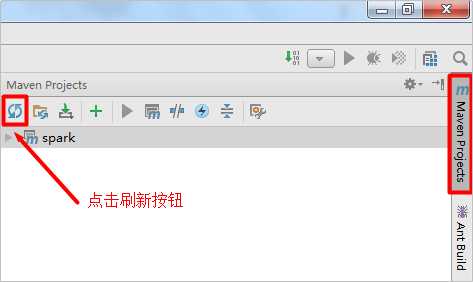
需要点击右侧的Maven Project侧边栏中的刷新按钮,才会导入Maven依赖,前提是保证电脑能够联网,Maven可能会到中央仓库下载一些依赖:
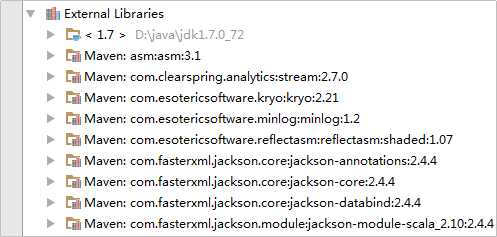
在左侧的Project侧边栏中的External Libraries下就可以看到新导入的Maven依赖了:
但是在pom.xml文件中还有错误提示,因为src/main/和src/test/这两个目录下面没有scala目录:
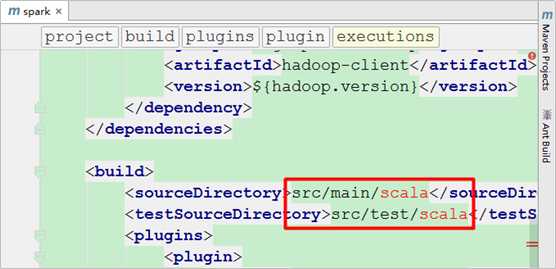
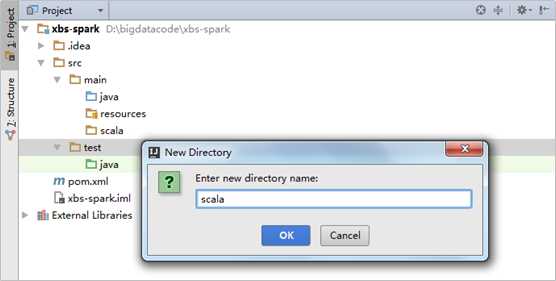
分别在main和test目录之上点击鼠标右键选择new->Directory创建scala目录:
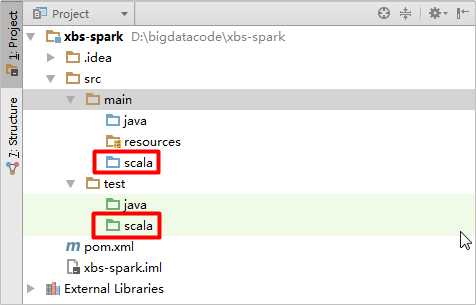
由于新创建的scala文件夹前面的图标颜色和java文件夹不一样,我们需要再次点击右侧Maven Project侧边栏中的刷新按钮,其颜色就会发生变化:
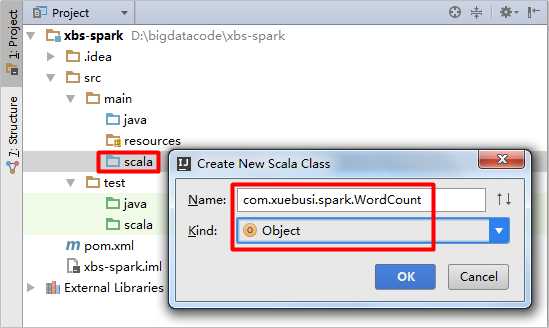
在scala目录下面创建WordCount(类型为Object):
3. 编写WordCount程序
下面是使用scala语言编写的Spark的一个简单的单词计数程序:
package com.xuebusi.spark import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * Created by SYJ on 2017/1/23. */ object WordCount { def main(args: Array[String]) { //创建SparkConf val conf: SparkConf = new SparkConf() //创建SparkContext val sc: SparkContext = new SparkContext(conf) //从文件读取数据 val lines: RDD[String] = sc.textFile(args(0)) //按空格切分单词 val words: RDD[String] = lines.flatMap(_.split(" ")) //单词计数,每个单词每出现一次就计数为1 val wordAndOne: RDD[(String, Int)] = words.map((_, 1)) //聚合,统计每个单词总共出现的次数 val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_) //排序,根据单词出现的次数排序 val fianlResult: RDD[(String, Int)] = result.sortBy(_._2, false) //将统计结果保存到文件 fianlResult.saveAsTextFile(args(1)) //释放资源 sc.stop() } }
4. 打包
将编写好的WordCount程序使用Maven插件打成jar包,打包的时候也要保证电脑能够联网,因为Maven可能会到中央仓库中下载一些依赖:
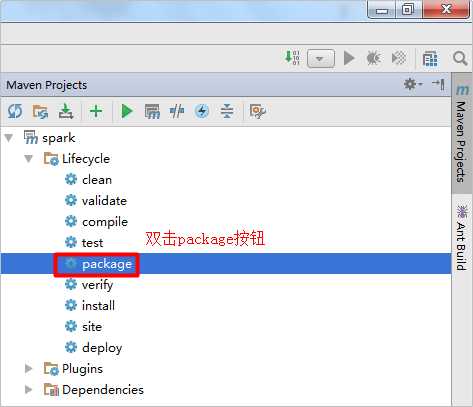
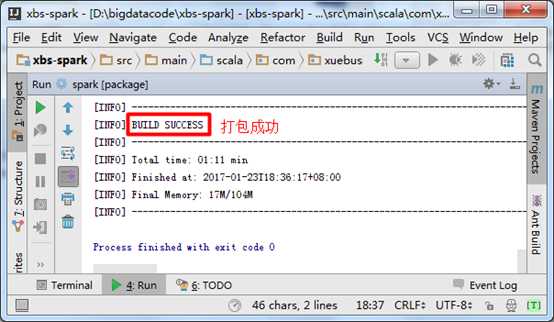
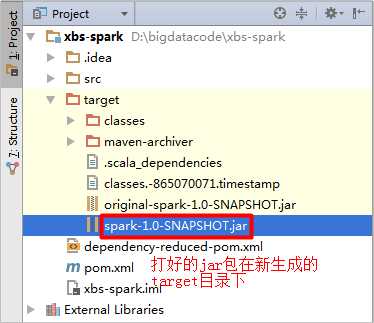
在jar包名称上面点击鼠标右键选择“Copy Path”,得到jar包在Windows磁盘上的绝对路径:D:\bigdatacode\xbs-spark\target\spark-1.0-SNAPSHOT.jar,在下面上传jar包时会用到此路径。
5. 上传jar包
使用SecureCRT工具连接Spark集群服务器,将spark-1.0-SNAPSHOT.jar上传到服务器:
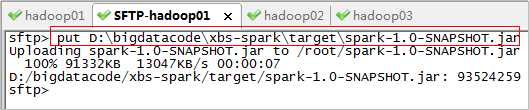
6. 同步时间
date -s "2017-01-23 19:19:30"
7. 启动Zookeeper
/root/apps/zookeeper/bin/zkServer.sh start
8. 启动hdfs
/root/apps/hadoop/sbin/start-dfs.sh
HDFS的活跃的NameNode节点:
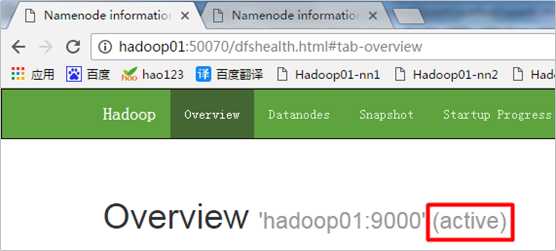
HDFS的备选NameNode节点:
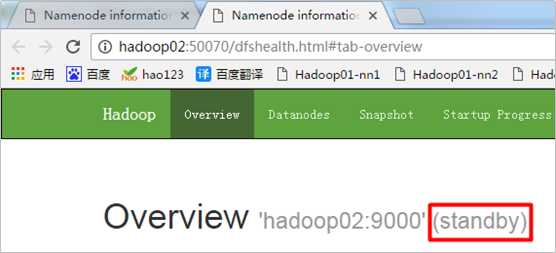
9. 启动Spark集群
/root/apps/spark/sbin/start-all.sh
启动单个Master进程使用如下命令:
/root/apps/spark/sbin/start-master.sh
Spark活跃的Master节点:
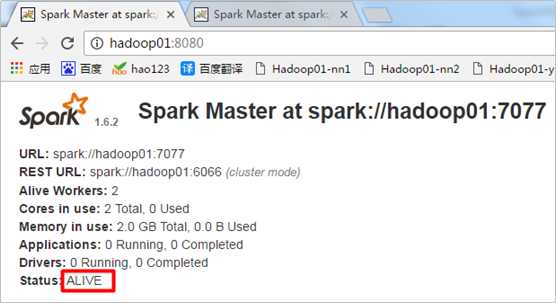
Spark的备选Master节点:
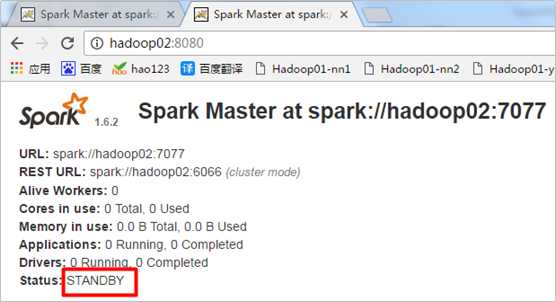
10. 准备输入数据

11. 提交Spark程序
提交Spark的WordCount程序需要两个参数,一个输入目录,一个输出目录,首先确定输出目录不存在,如果存在则删除:
hdfs dfs -rm -r /wordcount/output
使用spark-submit脚本提交spark程序:
/root/apps/spark/bin/spark-submit --master spark://hadoop01:7077,hadoop02:7077 \ --executor-memory 512m --total-executor-cores 7 --class com.xuebusi.spark.WordCount /root/spark-1.0-SNAPSHOT.jar hdfs://hadoop01:9000/wordcount/input hdfs://hadoop01:9000/wordcount/output
通过Spark的UI界面来观察程序执行过程:
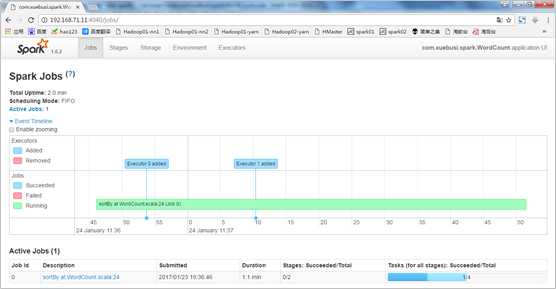
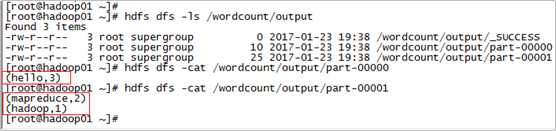
12. 查看结果
附1:程序打包日志

1 D:\java\jdk1.7.0_72\bin\java -Dmaven.home=D:\apache-maven-3.2.1 -Dclassworlds.conf=D:\apache-maven-3.2.1\bin\m2.conf -Didea.launcher.port=7533 "-Didea.launcher.bin.path=D:\java\IntelliJ_IDEA\IntelliJ IDEA Community Edition 2016.1.1\bin" -Dfile.encoding=UTF-8 -classpath "D:\apache-maven-3.2.1\boot\plexus-classworlds-2.5.1.jar;D:\java\IntelliJ_IDEA\IntelliJ IDEA Community Edition 2016.1.1\lib\idea_rt.jar" com.intellij.rt.execution.application.AppMain org.codehaus.classworlds.Launcher -Didea.version=2016.1.1 package 2 [INFO] Scanning for projects... 3 [INFO] 4 [INFO] Using the builder org.apache.maven.lifecycle.internal.builder.singlethreaded.SingleThreadedBuilder with a thread count of 1 5 [INFO] 6 [INFO] ------------------------------------------------------------------------ 7 [INFO] Building spark 1.0-SNAPSHOT 8 [INFO] ------------------------------------------------------------------------ 9 [INFO] 10 [INFO] --- maven-resources-plugin:2.6:resources (default-resources) @ spark --- 11 [INFO] Using ‘UTF-8‘ encoding to copy filtered resources. 12 [INFO] Copying 0 resource 13 [INFO] 14 [INFO] --- maven-compiler-plugin:2.5.1:compile (default-compile) @ spark --- 15 [INFO] Nothing to compile - all classes are up to date 16 [INFO] 17 [INFO] --- scala-maven-plugin:3.2.2:compile (default) @ spark --- 18 [WARNING] Expected all dependencies to require Scala version: 2.10.6 19 [WARNING] com.xuebusi:spark:1.0-SNAPSHOT requires scala version: 2.10.6 20 [WARNING] com.twitter:chill_2.10:0.5.0 requires scala version: 2.10.4 21 [WARNING] Multiple versions of scala libraries detected! 22 [INFO] Nothing to compile - all classes are up to date 23 [INFO] 24 [INFO] --- maven-resources-plugin:2.6:testResources (default-testResources) @ spark --- 25 [INFO] Using ‘UTF-8‘ encoding to copy filtered resources. 26 [INFO] skip non existing resourceDirectory D:\bigdatacode\spark-wordcount\src\test\resources 27 [INFO] 28 [INFO] --- maven-compiler-plugin:2.5.1:testCompile (default-testCompile) @ spark --- 29 [INFO] Nothing to compile - all classes are up to date 30 [INFO] 31 [INFO] --- scala-maven-plugin:3.2.2:testCompile (default) @ spark --- 32 [WARNING] Expected all dependencies to require Scala version: 2.10.6 33 [WARNING] com.xuebusi:spark:1.0-SNAPSHOT requires scala version: 2.10.6 34 [WARNING] com.twitter:chill_2.10:0.5.0 requires scala version: 2.10.4 35 [WARNING] Multiple versions of scala libraries detected! 36 [INFO] No sources to compile 37 [INFO] 38 [INFO] --- maven-surefire-plugin:2.12.4:test (default-test) @ spark --- 39 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-booter/2.12.4/surefire-booter-2.12.4.pom 40 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-booter/2.12.4/surefire-booter-2.12.4.pom (3 KB at 1.7 KB/sec) 41 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-api/2.12.4/surefire-api-2.12.4.pom 42 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-api/2.12.4/surefire-api-2.12.4.pom (3 KB at 2.4 KB/sec) 43 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/maven-surefire-common/2.12.4/maven-surefire-common-2.12.4.pom 44 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/maven-surefire-common/2.12.4/maven-surefire-common-2.12.4.pom (6 KB at 3.2 KB/sec) 45 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/plugin-tools/maven-plugin-annotations/3.1/maven-plugin-annotations-3.1.pom 46 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/plugin-tools/maven-plugin-annotations/3.1/maven-plugin-annotations-3.1.pom (2 KB at 1.7 KB/sec) 47 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/plugin-tools/maven-plugin-tools/3.1/maven-plugin-tools-3.1.pom 48 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/plugin-tools/maven-plugin-tools/3.1/maven-plugin-tools-3.1.pom (16 KB at 12.0 KB/sec) 49 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/maven-surefire-common/2.12.4/maven-surefire-common-2.12.4.jar 50 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-api/2.12.4/surefire-api-2.12.4.jar 51 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-booter/2.12.4/surefire-booter-2.12.4.jar 52 Downloading: http://repo.maven.apache.org/maven2/org/apache/maven/plugin-tools/maven-plugin-annotations/3.1/maven-plugin-annotations-3.1.jar 53 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/plugin-tools/maven-plugin-annotations/3.1/maven-plugin-annotations-3.1.jar (14 KB at 10.6 KB/sec) 54 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-booter/2.12.4/surefire-booter-2.12.4.jar (34 KB at 21.5 KB/sec) 55 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/maven-surefire-common/2.12.4/maven-surefire-common-2.12.4.jar (257 KB at 161.0 KB/sec) 56 Downloaded: http://repo.maven.apache.org/maven2/org/apache/maven/surefire/surefire-api/2.12.4/surefire-api-2.12.4.jar (115 KB at 55.1 KB/sec) 57 [INFO] No tests to run. 58 [INFO] 59 [INFO] --- maven-jar-plugin:2.4:jar (default-jar) @ spark --- 60 [INFO] Building jar: D:\bigdatacode\spark-wordcount\target\spark-1.0-SNAPSHOT.jar 61 [INFO] 62 [INFO] --- maven-shade-plugin:2.4.3:shade (default) @ spark --- 63 [INFO] Including org.scala-lang:scala-library:jar:2.10.6 in the shaded jar. 64 [INFO] Including org.apache.spark:spark-core_2.10:jar:1.6.2 in the shaded jar. 65 [INFO] Including org.apache.avro:avro-mapred:jar:hadoop2:1.7.7 in the shaded jar. 66 [INFO] Including org.apache.avro:avro-ipc:jar:1.7.7 in the shaded jar. 67 [INFO] Including org.apache.avro:avro-ipc:jar:tests:1.7.7 in the shaded jar. 68 [INFO] Including org.codehaus.jackson:jackson-core-asl:jar:1.9.13 in the shaded jar. 69 [INFO] Including org.codehaus.jackson:jackson-mapper-asl:jar:1.9.13 in the shaded jar. 70 [INFO] Including com.twitter:chill_2.10:jar:0.5.0 in the shaded jar. 71 [INFO] Including com.esotericsoftware.kryo:kryo:jar:2.21 in the shaded jar. 72 [INFO] Including com.esotericsoftware.reflectasm:reflectasm:jar:shaded:1.07 in the shaded jar. 73 [INFO] Including com.esotericsoftware.minlog:minlog:jar:1.2 in the shaded jar. 74 [INFO] Including org.objenesis:objenesis:jar:1.2 in the shaded jar. 75 [INFO] Including com.twitter:chill-java:jar:0.5.0 in the shaded jar. 76 [INFO] Including org.apache.xbean:xbean-asm5-shaded:jar:4.4 in the shaded jar. 77 [INFO] Including org.apache.spark:spark-launcher_2.10:jar:1.6.2 in the shaded jar. 78 [INFO] Including org.apache.spark:spark-network-common_2.10:jar:1.6.2 in the shaded jar. 79 [INFO] Including org.apache.spark:spark-network-shuffle_2.10:jar:1.6.2 in the shaded jar. 80 [INFO] Including org.fusesource.leveldbjni:leveldbjni-all:jar:1.8 in the shaded jar. 81 [INFO] Including com.fasterxml.jackson.core:jackson-annotations:jar:2.4.4 in the shaded jar. 82 [INFO] Including org.apache.spark:spark-unsafe_2.10:jar:1.6.2 in the shaded jar. 83 [INFO] Including net.java.dev.jets3t:jets3t:jar:0.7.1 in the shaded jar. 84 [INFO] Including commons-codec:commons-codec:jar:1.3 in the shaded jar. 85 [INFO] Including commons-httpclient:commons-httpclient:jar:3.1 in the shaded jar. 86 [INFO] Including org.apache.curator:curator-recipes:jar:2.4.0 in the shaded jar. 87 [INFO] Including org.apache.curator:curator-framework:jar:2.4.0 in the shaded jar. 88 [INFO] Including org.apache.zookeeper:zookeeper:jar:3.4.5 in the shaded jar. 89 [INFO] Including jline:jline:jar:0.9.94 in the shaded jar. 90 [INFO] Including com.google.guava:guava:jar:14.0.1 in the shaded jar. 91 [INFO] Including org.eclipse.jetty.orbit:javax.servlet:jar:3.0.0.v201112011016 in the shaded jar. 92 [INFO] Including org.apache.commons:commons-lang3:jar:3.3.2 in the shaded jar. 93 [INFO] Including org.apache.commons:commons-math3:jar:3.4.1 in the shaded jar. 94 [INFO] Including com.google.code.findbugs:jsr305:jar:1.3.9 in the shaded jar. 95 [INFO] Including org.slf4j:slf4j-api:jar:1.7.10 in the shaded jar. 96 [INFO] Including org.slf4j:jul-to-slf4j:jar:1.7.10 in the shaded jar. 97 [INFO] Including org.slf4j:jcl-over-slf4j:jar:1.7.10 in the shaded jar. 98 [INFO] Including log4j:log4j:jar:1.2.17 in the shaded jar. 99 [INFO] Including org.slf4j:slf4j-log4j12:jar:1.7.10 in the shaded jar. 100 [INFO] Including com.ning:compress-lzf:jar:1.0.3 in the shaded jar. 101 [INFO] Including org.xerial.snappy:snappy-java:jar:1.1.2.1 in the shaded jar. 102 [INFO] Including net.jpountz.lz4:lz4:jar:1.3.0 in the shaded jar. 103 [INFO] Including org.roaringbitmap:RoaringBitmap:jar:0.5.11 in the shaded jar. 104 [INFO] Including commons-net:commons-net:jar:2.2 in the shaded jar. 105 [INFO] Including com.typesafe.akka:akka-remote_2.10:jar:2.3.11 in the shaded jar. 106 [INFO] Including com.typesafe.akka:akka-actor_2.10:jar:2.3.11 in the shaded jar. 107 [INFO] Including com.typesafe:config:jar:1.2.1 in the shaded jar. 108 [INFO] Including io.netty:netty:jar:3.8.0.Final in the shaded jar. 109 [INFO] Including com.google.protobuf:protobuf-java:jar:2.5.0 in the shaded jar. 110 [INFO] Including org.uncommons.maths:uncommons-maths:jar:1.2.2a in the shaded jar. 111 [INFO] Including com.typesafe.akka:akka-slf4j_2.10:jar:2.3.11 in the shaded jar. 112 [INFO] Including org.json4s:json4s-jackson_2.10:jar:3.2.10 in the shaded jar. 113 [INFO] Including org.json4s:json4s-core_2.10:jar:3.2.10 in the shaded jar. 114 [INFO] Including org.json4s:json4s-ast_2.10:jar:3.2.10 in the shaded jar. 115 [INFO] Including org.scala-lang:scalap:jar:2.10.0 in the shaded jar. 116 [INFO] Including org.scala-lang:scala-compiler:jar:2.10.0 in the shaded jar. 117 [INFO] Including com.sun.jersey:jersey-server:jar:1.9 in the shaded jar. 118 [INFO] Including asm:asm:jar:3.1 in the shaded jar. 119 [INFO] Including com.sun.jersey:jersey-core:jar:1.9 in the shaded jar. 120 [INFO] Including org.apache.mesos:mesos:jar:shaded-protobuf:0.21.1 in the shaded jar. 121 [INFO] Including io.netty:netty-all:jar:4.0.29.Final in the shaded jar. 122 [INFO] Including com.clearspring.analytics:stream:jar:2.7.0 in the shaded jar. 123 [INFO] Including io.dropwizard.metrics:metrics-core:jar:3.1.2 in the shaded jar. 124 [INFO] Including io.dropwizard.metrics:metrics-jvm:jar:3.1.2 in the shaded jar. 125 [INFO] Including io.dropwizard.metrics:metrics-json:jar:3.1.2 in the shaded jar. 126 [INFO] Including io.dropwizard.metrics:metrics-graphite:jar:3.1.2 in the shaded jar. 127 [INFO] Including com.fasterxml.jackson.core:jackson-databind:jar:2.4.4 in the shaded jar. 128 [INFO] Including com.fasterxml.jackson.core:jackson-core:jar:2.4.4 in the shaded jar. 129 [INFO] Including com.fasterxml.jackson.module:jackson-module-scala_2.10:jar:2.4.4 in the shaded jar. 130 [INFO] Including org.scala-lang:scala-reflect:jar:2.10.4 in the shaded jar. 131 [INFO] Including com.thoughtworks.paranamer:paranamer:jar:2.6 in the shaded jar. 132 [INFO] Including org.apache.ivy:ivy:jar:2.4.0 in the shaded jar. 133 [INFO] Including oro:oro:jar:2.0.8 in the shaded jar. 134 [INFO] Including org.tachyonproject:tachyon-client:jar:0.8.2 in the shaded jar. 135 [INFO] Including commons-lang:commons-lang:jar:2.4 in the shaded jar. 136 [INFO] Including commons-io:commons-io:jar:2.4 in the shaded jar. 137 [INFO] Including org.tachyonproject:tachyon-underfs-hdfs:jar:0.8.2 in the shaded jar. 138 [INFO] Including org.tachyonproject:tachyon-underfs-s3:jar:0.8.2 in the shaded jar. 139 [INFO] Including org.tachyonproject:tachyon-underfs-local:jar:0.8.2 in the shaded jar. 140 [INFO] Including net.razorvine:pyrolite:jar:4.9 in the shaded jar. 141 [INFO] Including net.sf.py4j:py4j:jar:0.9 in the shaded jar. 142 [INFO] Including org.spark-project.spark:unused:jar:1.0.0 in the shaded jar. 143 [INFO] Including org.apache.hadoop:hadoop-client:jar:2.6.4 in the shaded jar. 144 [INFO] Including org.apache.hadoop:hadoop-common:jar:2.6.4 in the shaded jar. 145 [INFO] Including commons-cli:commons-cli:jar:1.2 in the shaded jar. 146 [INFO] Including xmlenc:xmlenc:jar:0.52 in the shaded jar. 147 [INFO] Including commons-collections:commons-collections:jar:3.2.2 in the shaded jar. 148 [INFO] Including commons-logging:commons-logging:jar:1.1.3 in the shaded jar. 149 [INFO] Including commons-configuration:commons-configuration:jar:1.6 in the shaded jar. 150 [INFO] Including commons-digester:commons-digester:jar:1.8 in the shaded jar. 151 [INFO] Including commons-beanutils:commons-beanutils:jar:1.7.0 in the shaded jar. 152 [INFO] Including commons-beanutils:commons-beanutils-core:jar:1.8.0 in the shaded jar. 153 [INFO] Including org.apache.avro:avro:jar:1.7.4 in the shaded jar. 154 [INFO] Including com.google.code.gson:gson:jar:2.2.4 in the shaded jar. 155 [INFO] Including org.apache.hadoop:hadoop-auth:jar:2.6.4 in the shaded jar. 156 [INFO] Including org.apache.httpcomponents:httpclient:jar:4.2.5 in the shaded jar. 157 [INFO] Including org.apache.httpcomponents:httpcore:jar:4.2.4 in the shaded jar. 158 [INFO] Including org.apache.directory.server:apacheds-kerberos-codec:jar:2.0.0-M15 in the shaded jar. 159 [INFO] Including org.apache.directory.server:apacheds-i18n:jar:2.0.0-M15 in the shaded jar. 160 [INFO] Including org.apache.directory.api:api-asn1-api:jar:1.0.0-M20 in the shaded jar. 161 [INFO] Including org.apache.directory.api:api-util:jar:1.0.0-M20 in the shaded jar. 162 [INFO] Including org.apache.curator:curator-client:jar:2.6.0 in the shaded jar. 163 [INFO] Including org.htrace:htrace-core:jar:3.0.4 in the shaded jar. 164 [INFO] Including org.apache.commons:commons-compress:jar:1.4.1 in the shaded jar. 165 [INFO] Including org.tukaani:xz:jar:1.0 in the shaded jar. 166 [INFO] Including org.apache.hadoop:hadoop-hdfs:jar:2.6.4 in the shaded jar. 167 [INFO] Including org.mortbay.jetty:jetty-util:jar:6.1.26 in the shaded jar. 168 [INFO] Including xerces:xercesImpl:jar:2.9.1 in the shaded jar. 169 [INFO] Including xml-apis:xml-apis:jar:1.3.04 in the shaded jar. 170 [INFO] Including org.apache.hadoop:hadoop-mapreduce-client-app:jar:2.6.4 in the shaded jar. 171 [INFO] Including org.apache.hadoop:hadoop-mapreduce-client-common:jar:2.6.4 in the shaded jar. 172 [INFO] Including org.apache.hadoop:hadoop-yarn-client:jar:2.6.4 in the shaded jar. 173 [INFO] Including org.apache.hadoop:hadoop-yarn-server-common:jar:2.6.4 in the shaded jar. 174 [INFO] Including org.apache.hadoop:hadoop-mapreduce-client-shuffle:jar:2.6.4 in the shaded jar. 175 [INFO] Including org.apache.hadoop:hadoop-yarn-api:jar:2.6.4 in the shaded jar. 176 [INFO] Including org.apache.hadoop:hadoop-mapreduce-client-core:jar:2.6.4 in the shaded jar. 177 [INFO] Including org.apache.hadoop:hadoop-yarn-common:jar:2.6.4 in the shaded jar. 178 [INFO] Including javax.xml.bind:jaxb-api:jar:2.2.2 in the shaded jar. 179 [INFO] Including javax.xml.stream:stax-api:jar:1.0-2 in the shaded jar. 180 [INFO] Including javax.activation:activation:jar:1.1 in the shaded jar. 181 [INFO] Including javax.servlet:servlet-api:jar:2.5 in the shaded jar. 182 [INFO] Including com.sun.jersey:jersey-client:jar:1.9 in the shaded jar. 183 [INFO] Including org.codehaus.jackson:jackson-jaxrs:jar:1.9.13 in the shaded jar. 184 [INFO] Including org.codehaus.jackson:jackson-xc:jar:1.9.13 in the shaded jar. 185 [INFO] Including org.apache.hadoop:hadoop-mapreduce-client-jobclient:jar:2.6.4 in the shaded jar. 186 [INFO] Including org.apache.hadoop:hadoop-annotations:jar:2.6.4 in the shaded jar. 187 [WARNING] commons-logging-1.1.3.jar, jcl-over-slf4j-1.7.10.jar define 6 overlapping classes: 188 [WARNING] - org.apache.commons.logging.impl.NoOpLog 189 [WARNING] - org.apache.commons.logging.impl.SimpleLog 190 [WARNING] - org.apache.commons.logging.LogFactory 191 [WARNING] - org.apache.commons.logging.LogConfigurationException 192 [WARNING] - org.apache.commons.logging.impl.SimpleLog$1 193 [WARNING] - org.apache.commons.logging.Log 194 [WARNING] commons-beanutils-core-1.8.0.jar, commons-beanutils-1.7.0.jar define 82 overlapping classes: 195 [WARNING] - org.apache.commons.beanutils.WrapDynaBean 196 [WARNING] - org.apache.commons.beanutils.Converter 197 [WARNING] - org.apache.commons.beanutils.converters.IntegerConverter 198 [WARNING] - org.apache.commons.beanutils.locale.LocaleBeanUtilsBean 199 [WARNING] - org.apache.commons.beanutils.locale.converters.DecimalLocaleConverter 200 [WARNING] - org.apache.commons.beanutils.locale.converters.DoubleLocaleConverter 201 [WARNING] - org.apache.commons.beanutils.converters.ShortConverter 202 [WARNING] - org.apache.commons.beanutils.converters.StringArrayConverter 203 [WARNING] - org.apache.commons.beanutils.locale.LocaleConvertUtilsBean 204 [WARNING] - org.apache.commons.beanutils.LazyDynaClass 205 [WARNING] - 72 more... 206 [WARNING] hadoop-yarn-common-2.6.4.jar, hadoop-yarn-api-2.6.4.jar define 3 overlapping classes: 207 [WARNING] - org.apache.hadoop.yarn.factories.package-info 208 [WARNING] - org.apache.hadoop.yarn.util.package-info 209 [WARNING] - org.apache.hadoop.yarn.factory.providers.package-info 210 [WARNING] commons-beanutils-core-1.8.0.jar, commons-collections-3.2.2.jar, commons-beanutils-1.7.0.jar define 10 overlapping classes: 211 [WARNING] - org.apache.commons.collections.FastHashMap$EntrySet 212 [WARNING] - org.apache.commons.collections.ArrayStack 213 [WARNING] - org.apache.commons.collections.FastHashMap$1 214 [WARNING] - org.apache.commons.collections.FastHashMap$KeySet 215 [WARNING] - org.apache.commons.collections.FastHashMap$CollectionView 216 [WARNING] - org.apache.commons.collections.BufferUnderflowException 217 [WARNING] - org.apache.commons.collections.Buffer 218 [WARNING] - org.apache.commons.collections.FastHashMap$CollectionView$CollectionViewIterator 219 [WARNING] - org.apache.commons.collections.FastHashMap$Values 220 [WARNING] - org.apache.commons.collections.FastHashMap 221 [WARNING] kryo-2.21.jar, objenesis-1.2.jar define 32 overlapping classes: 222 [WARNING] - org.objenesis.Objenesis 223 [WARNING] - org.objenesis.strategy.StdInstantiatorStrategy 224 [WARNING] - org.objenesis.instantiator.basic.ObjectStreamClassInstantiator 225 [WARNING] - org.objenesis.instantiator.sun.SunReflectionFactorySerializationInstantiator 226 [WARNING] - org.objenesis.instantiator.perc.PercSerializationInstantiator 227 [WARNING] - org.objenesis.instantiator.NullInstantiator 228 [WARNING] - org.objenesis.instantiator.jrockit.JRockitLegacyInstantiator 229 [WARNING] - org.objenesis.instantiator.gcj.GCJInstantiatorBase 230 [WARNING] - org.objenesis.ObjenesisException 231 [WARNING] - org.objenesis.instantiator.basic.ObjectInputStreamInstantiator$MockStream 232 [WARNING] - 22 more... 233 [WARNING] kryo-2.21.jar, reflectasm-1.07-shaded.jar define 23 overlapping classes: 234 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.Opcodes 235 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.Frame 236 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.Label 237 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.FieldWriter 238 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.AnnotationVisitor 239 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.FieldVisitor 240 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.Item 241 [WARNING] - com.esotericsoftware.reflectasm.AccessClassLoader 242 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.Edge 243 [WARNING] - com.esotericsoftware.reflectasm.shaded.org.objectweb.asm.ClassVisitor 244 [WARNING] - 13 more... 245 [WARNING] minlog-1.2.jar, kryo-2.21.jar define 2 overlapping classes: 246 [WARNING] - com.esotericsoftware.minlog.Log$Logger 247 [WARNING] - com.esotericsoftware.minlog.Log 248 [WARNING] servlet-api-2.5.jar, javax.servlet-3.0.0.v201112011016.jar define 42 overlapping classes: 249 [WARNING] - javax.servlet.ServletRequestWrapper 250 [WARNING] - javax.servlet.FilterChain 251 [WARNING] - javax.servlet.SingleThreadModel 252 [WARNING] - javax.servlet.http.HttpServletResponse 253 [WARNING] - javax.servlet.http.HttpUtils 254 [WARNING] - javax.servlet.ServletContextAttributeEvent 255 [WARNING] - javax.servlet.ServletContextAttributeListener 256 [WARNING] - javax.servlet.http.HttpServlet 257 [WARNING] - javax.servlet.http.HttpSessionAttributeListener 258 [WARNING] - javax.servlet.http.HttpServletRequest 259 [WARNING] - 32 more... 260 [WARNING] guava-14.0.1.jar, spark-network-common_2.10-1.6.2.jar define 7 overlapping classes: 261 [WARNING] - com.google.common.base.Optional$1$1 262 [WARNING] - com.google.common.base.Supplier 263 [WARNING] - com.google.common.base.Function 264 [WARNING] - com.google.common.base.Optional 265 [WARNING] - com.google.common.base.Optional$1 266 [WARNING] - com.google.common.base.Absent 267 [WARNING] - com.google.common.base.Present 268 [WARNING] hadoop-yarn-common-2.6.4.jar, hadoop-yarn-client-2.6.4.jar define 2 overlapping classes: 269 [WARNING] - org.apache.hadoop.yarn.client.api.impl.package-info 270 [WARNING] - org.apache.hadoop.yarn.client.api.package-info 271 [WARNING] unused-1.0.0.jar, spark-core_2.10-1.6.2.jar, spark-network-shuffle_2.10-1.6.2.jar, spark-launcher_2.10-1.6.2.jar, spark-unsafe_2.10-1.6.2.jar, spark-network-common_2.10-1.6.2.jar define 1 overlapping classes: 272 [WARNING] - org.apache.spark.unused.UnusedStubClass 273 [WARNING] maven-shade-plugin has detected that some class files are 274 [WARNING] present in two or more JARs. When this happens, only one 275 [WARNING] single version of the class is copied to the uber jar. 276 [WARNING] Usually this is not harmful and you can skip these warnings, 277 [WARNING] otherwise try to manually exclude artifacts based on 278 [WARNING] mvn dependency:tree -Ddetail=true and the above output. 279 [WARNING] See http://maven.apache.org/plugins/maven-shade-plugin/ 280 [INFO] Replacing original artifact with shaded artifact. 281 [INFO] Replacing D:\bigdatacode\spark-wordcount\target\spark-1.0-SNAPSHOT.jar with D:\bigdatacode\spark-wordcount\target\spark-1.0-SNAPSHOT-shaded.jar 282 [INFO] Dependency-reduced POM written at: D:\bigdatacode\spark-wordcount\dependency-reduced-pom.xml 283 [INFO] ------------------------------------------------------------------------ 284 [INFO] BUILD SUCCESS 285 [INFO] ------------------------------------------------------------------------ 286 [INFO] Total time: 01:02 min 287 [INFO] Finished at: 2017-01-23T12:44:03+08:00 288 [INFO] Final Memory: 18M/115M 289 [INFO] ------------------------------------------------------------------------ 290 291 Process finished with exit code 0
附2:程序执行过程日志
1 Using Spark‘s default log4j profile: org/apache/spark/log4j-defaults.properties 2 17/01/23 19:35:52 INFO SparkContext: Running Spark version 1.6.2 3 17/01/23 19:35:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 4 17/01/23 19:35:57 INFO SecurityManager: Changing view acls to: root 5 17/01/23 19:35:57 INFO SecurityManager: Changing modify acls to: root 6 17/01/23 19:35:57 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root) 7 17/01/23 19:36:00 INFO Utils: Successfully started service ‘sparkDriver‘ on port 38885. 8 17/01/23 19:36:04 INFO Slf4jLogger: Slf4jLogger started 9 17/01/23 19:36:04 INFO Remoting: Starting remoting 10 17/01/23 19:36:06 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.71.11:50102] 11 17/01/23 19:36:06 INFO Utils: Successfully started service ‘sparkDriverActorSystem‘ on port 50102. 12 17/01/23 19:36:07 INFO SparkEnv: Registering MapOutputTracker 13 17/01/23 19:36:07 INFO SparkEnv: Registering BlockManagerMaster 14 17/01/23 19:36:08 INFO DiskBlockManager: Created local directory at /tmp/blockmgr-677f9442-f73a-4925-b629-297dc3409fa8 15 17/01/23 19:36:08 INFO MemoryStore: MemoryStore started with capacity 517.4 MB 16 17/01/23 19:36:08 INFO SparkEnv: Registering OutputCommitCoordinator 17 17/01/23 19:36:15 INFO Utils: Successfully started service ‘SparkUI‘ on port 4040. 18 17/01/23 19:36:15 INFO SparkUI: Started SparkUI at http://192.168.71.11:4040 19 17/01/23 19:36:15 INFO HttpFileServer: HTTP File server directory is /tmp/spark-1be891d5-88d1-4e02-970b-023ff1e8c618/httpd-b73f26ff-5d13-4abd-953b-164a3f2d18e7 20 17/01/23 19:36:15 INFO HttpServer: Starting HTTP Server 21 17/01/23 19:36:15 INFO Utils: Successfully started service ‘HTTP file server‘ on port 38719. 22 17/01/23 19:36:22 INFO SparkContext: Added JAR file:/root/spark-1.0-SNAPSHOT.jar at http://192.168.71.11:38719/jars/spark-1.0-SNAPSHOT.jar with timestamp 1485228982685 23 17/01/23 19:36:23 INFO AppClient$ClientEndpoint: Connecting to master spark://hadoop01:7077... 24 17/01/23 19:36:23 INFO AppClient$ClientEndpoint: Connecting to master spark://hadoop02:7077... 25 17/01/23 19:36:26 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20170123193626-0000 26 17/01/23 19:36:26 INFO Utils: Successfully started service ‘org.apache.spark.network.netty.NettyBlockTransferService‘ on port 59402. 27 17/01/23 19:36:26 INFO NettyBlockTransferService: Server created on 59402 28 17/01/23 19:36:26 INFO BlockManagerMaster: Trying to register BlockManager 29 17/01/23 19:36:26 INFO BlockManagerMasterEndpoint: Registering block manager 192.168.71.11:59402 with 517.4 MB RAM, BlockManagerId(driver, 192.168.71.11, 59402) 30 17/01/23 19:36:27 INFO BlockManagerMaster: Registered BlockManager 31 17/01/23 19:36:27 INFO AppClient$ClientEndpoint: Executor added: app-20170123193626-0000/0 on worker-20170123192703-192.168.71.12-41229 (192.168.71.12:41229) with 1 cores 32 17/01/23 19:36:27 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170123193626-0000/0 on hostPort 192.168.71.12:41229 with 1 cores, 512.0 MB RAM 33 17/01/23 19:36:27 INFO AppClient$ClientEndpoint: Executor added: app-20170123193626-0000/1 on worker-20170123192703-192.168.71.13-49628 (192.168.71.13:49628) with 1 cores 34 17/01/23 19:36:27 INFO SparkDeploySchedulerBackend: Granted executor ID app-20170123193626-0000/1 on hostPort 192.168.71.13:49628 with 1 cores, 512.0 MB RAM 35 17/01/23 19:36:28 INFO AppClient$ClientEndpoint: Executor updated: app-20170123193626-0000/1 is now RUNNING 36 17/01/23 19:36:28 INFO AppClient$ClientEndpoint: Executor updated: app-20170123193626-0000/0 is now RUNNING 37 17/01/23 19:36:30 INFO SparkDeploySchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0 38 17/01/23 19:36:33 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 153.6 KB, free 153.6 KB) 39 17/01/23 19:36:33 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 167.5 KB) 40 17/01/23 19:36:33 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.71.11:59402 (size: 13.9 KB, free: 517.4 MB) 41 17/01/23 19:36:33 INFO SparkContext: Created broadcast 0 from textFile at WordCount.scala:16 42 17/01/23 19:36:45 INFO FileInputFormat: Total input paths to process : 1 43 17/01/23 19:36:45 INFO SparkContext: Starting job: sortBy at WordCount.scala:24 44 17/01/23 19:36:46 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:20) 45 17/01/23 19:36:46 INFO DAGScheduler: Got job 0 (sortBy at WordCount.scala:24) with 2 output partitions 46 17/01/23 19:36:46 INFO DAGScheduler: Final stage: ResultStage 1 (sortBy at WordCount.scala:24) 47 17/01/23 19:36:46 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0) 48 17/01/23 19:36:46 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0) 49 17/01/23 19:36:46 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:20), which has no missing parents 50 17/01/23 19:36:46 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 171.6 KB) 51 17/01/23 19:36:46 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 173.9 KB) 52 17/01/23 19:36:46 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.71.11:59402 (size: 2.3 KB, free: 517.4 MB) 53 17/01/23 19:36:46 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006 54 17/01/23 19:36:46 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:20) 55 17/01/23 19:36:46 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks 56 17/01/23 19:36:53 INFO SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (hadoop02:59859) with ID 0 57 17/01/23 19:36:53 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, hadoop02, partition 0,NODE_LOCAL, 2201 bytes) 58 17/01/23 19:36:54 INFO BlockManagerMasterEndpoint: Registering block manager hadoop02:37066 with 146.2 MB RAM, BlockManagerId(0, hadoop02, 37066) 59 17/01/23 19:37:09 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop02:37066 (size: 2.3 KB, free: 146.2 MB) 60 17/01/23 19:37:10 INFO SparkDeploySchedulerBackend: Registered executor NettyRpcEndpointRef(null) (hadoop03:43916) with ID 1 61 17/01/23 19:37:10 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, hadoop03, partition 1,NODE_LOCAL, 2201 bytes) 62 17/01/23 19:37:10 INFO BlockManagerMasterEndpoint: Registering block manager hadoop03:52009 with 146.2 MB RAM, BlockManagerId(1, hadoop03, 52009) 63 17/01/23 19:37:11 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop02:37066 (size: 13.9 KB, free: 146.2 MB) 64 17/01/23 19:37:19 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 25906 ms on hadoop02 (1/2) 65 17/01/23 19:37:43 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop03:52009 (size: 2.3 KB, free: 146.2 MB) 66 17/01/23 19:37:46 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on hadoop03:52009 (size: 13.9 KB, free: 146.2 MB) 67 17/01/23 19:37:55 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 45040 ms on hadoop03 (2/2) 68 17/01/23 19:37:55 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:20) finished in 68.357 s 69 17/01/23 19:37:55 INFO DAGScheduler: looking for newly runnable stages 70 17/01/23 19:37:55 INFO DAGScheduler: running: Set() 71 17/01/23 19:37:55 INFO DAGScheduler: waiting: Set(ResultStage 1) 72 17/01/23 19:37:55 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 73 17/01/23 19:37:55 INFO DAGScheduler: failed: Set() 74 17/01/23 19:37:55 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[7] at sortBy at WordCount.scala:24), which has no missing parents 75 17/01/23 19:37:55 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 3.6 KB, free 177.5 KB) 76 17/01/23 19:37:55 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 2.0 KB, free 179.5 KB) 77 17/01/23 19:37:55 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.71.11:59402 (size: 2.0 KB, free: 517.4 MB) 78 17/01/23 19:37:55 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006 79 17/01/23 19:37:55 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (MapPartitionsRDD[7] at sortBy at WordCount.scala:24) 80 17/01/23 19:37:55 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks 81 17/01/23 19:37:55 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, hadoop03, partition 0,NODE_LOCAL, 1958 bytes) 82 17/01/23 19:37:55 INFO TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, hadoop02, partition 1,NODE_LOCAL, 1958 bytes) 83 17/01/23 19:37:55 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on hadoop03:52009 (size: 2.0 KB, free: 146.2 MB) 84 17/01/23 19:37:56 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to hadoop03:43916 85 17/01/23 19:37:56 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 157 bytes 86 17/01/23 19:37:56 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on hadoop02:37066 (size: 2.0 KB, free: 146.2 MB) 87 17/01/23 19:37:56 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 1152 ms on hadoop03 (1/2) 88 17/01/23 19:37:57 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to hadoop02:59859 89 17/01/23 19:37:57 INFO DAGScheduler: ResultStage 1 (sortBy at WordCount.scala:24) finished in 1.615 s 90 17/01/23 19:37:57 INFO TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 1605 ms on hadoop02 (2/2) 91 17/01/23 19:37:57 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 92 17/01/23 19:37:57 INFO DAGScheduler: Job 0 finished: sortBy at WordCount.scala:24, took 71.451062 s 93 17/01/23 19:37:57 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id 94 17/01/23 19:37:57 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id 95 17/01/23 19:37:57 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap 96 17/01/23 19:37:57 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition 97 17/01/23 19:37:57 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id 98 17/01/23 19:37:58 INFO SparkContext: Starting job: saveAsTextFile at WordCount.scala:26 99 17/01/23 19:37:58 INFO DAGScheduler: Registering RDD 5 (sortBy at WordCount.scala:24) 100 17/01/23 19:37:58 INFO DAGScheduler: Got job 1 (saveAsTextFile at WordCount.scala:26) with 2 output partitions 101 17/01/23 19:37:58 INFO DAGScheduler: Final stage: ResultStage 4 (saveAsTextFile at WordCount.scala:26) 102 17/01/23 19:37:58 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 3) 103 17/01/23 19:37:58 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 3) 104 17/01/23 19:37:58 INFO DAGScheduler: Submitting ShuffleMapStage 3 (MapPartitionsRDD[5] at sortBy at WordCount.scala:24), which has no missing parents 105 17/01/23 19:37:58 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 3.5 KB, free 183.1 KB) 106 17/01/23 19:37:59 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 2.0 KB, free 185.1 KB) 107 17/01/23 19:37:59 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.71.11:59402 (size: 2.0 KB, free: 517.4 MB) 108 17/01/23 19:37:59 INFO SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:1006 109 17/01/23 19:37:59 INFO DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 3 (MapPartitionsRDD[5] at sortBy at WordCount.scala:24) 110 17/01/23 19:37:59 INFO TaskSchedulerImpl: Adding task set 3.0 with 2 tasks 111 17/01/23 19:37:59 INFO TaskSetManager: Starting task 0.0 in stage 3.0 (TID 4, hadoop02, partition 0,NODE_LOCAL, 1947 bytes) 112 17/01/23 19:37:59 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on hadoop02:37066 (size: 2.0 KB, free: 146.2 MB) 113 17/01/23 19:37:59 INFO TaskSetManager: Starting task 1.0 in stage 3.0 (TID 5, hadoop02, partition 1,NODE_LOCAL, 1947 bytes) 114 17/01/23 19:37:59 INFO TaskSetManager: Finished task 0.0 in stage 3.0 (TID 4) in 531 ms on hadoop02 (1/2) 115 17/01/23 19:37:59 INFO DAGScheduler: ShuffleMapStage 3 (sortBy at WordCount.scala:24) finished in 0.643 s 116 17/01/23 19:37:59 INFO DAGScheduler: looking for newly runnable stages 117 17/01/23 19:37:59 INFO DAGScheduler: running: Set() 118 17/01/23 19:37:59 INFO DAGScheduler: waiting: Set(ResultStage 4) 119 17/01/23 19:37:59 INFO DAGScheduler: failed: Set() 120 17/01/23 19:37:59 INFO DAGScheduler: Submitting ResultStage 4 (MapPartitionsRDD[10] at saveAsTextFile at WordCount.scala:26), which has no missing parents 121 17/01/23 19:37:59 INFO TaskSetManager: Finished task 1.0 in stage 3.0 (TID 5) in 132 ms on hadoop02 (2/2) 122 17/01/23 19:37:59 INFO TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool 123 17/01/23 19:38:00 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 64.9 KB, free 250.0 KB) 124 17/01/23 19:38:00 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 22.5 KB, free 272.5 KB) 125 17/01/23 19:38:00 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.71.11:59402 (size: 22.5 KB, free: 517.4 MB) 126 17/01/23 19:38:00 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1006 127 17/01/23 19:38:00 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 4 (MapPartitionsRDD[10] at saveAsTextFile at WordCount.scala:26) 128 17/01/23 19:38:00 INFO TaskSchedulerImpl: Adding task set 4.0 with 2 tasks 129 17/01/23 19:38:00 INFO TaskSetManager: Starting task 0.0 in stage 4.0 (TID 6, hadoop02, partition 0,NODE_LOCAL, 1958 bytes) 130 17/01/23 19:38:00 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop02:37066 (size: 22.5 KB, free: 146.2 MB) 131 17/01/23 19:38:00 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to hadoop02:59859 132 17/01/23 19:38:00 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 1 is 149 bytes 133 17/01/23 19:38:04 INFO TaskSetManager: Starting task 1.0 in stage 4.0 (TID 7, hadoop03, partition 1,ANY, 1958 bytes) 134 17/01/23 19:38:04 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on hadoop03:52009 (size: 22.5 KB, free: 146.2 MB) 135 17/01/23 19:38:04 INFO TaskSetManager: Finished task 0.0 in stage 4.0 (TID 6) in 4444 ms on hadoop02 (1/2) 136 17/01/23 19:38:04 INFO MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to hadoop03:43916 137 17/01/23 19:38:06 INFO DAGScheduler: ResultStage 4 (saveAsTextFile at WordCount.scala:26) finished in 5.782 s 138 17/01/23 19:38:06 INFO TaskSetManager: Finished task 1.0 in stage 4.0 (TID 7) in 1827 ms on hadoop03 (2/2) 139 17/01/23 19:38:06 INFO TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool 140 17/01/23 19:38:06 INFO DAGScheduler: Job 1 finished: saveAsTextFile at WordCount.scala:26, took 7.582931 s 141 17/01/23 19:38:06 INFO SparkUI: Stopped Spark web UI at http://192.168.71.11:4040 142 17/01/23 19:38:06 INFO SparkDeploySchedulerBackend: Shutting down all executors 143 17/01/23 19:38:06 INFO SparkDeploySchedulerBackend: Asking each executor to shut down 144 17/01/23 19:38:06 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 145 17/01/23 19:38:08 INFO MemoryStore: MemoryStore cleared 146 17/01/23 19:38:08 INFO BlockManager: BlockManager stopped 147 17/01/23 19:38:08 INFO BlockManagerMaster: BlockManagerMaster stopped 148 17/01/23 19:38:08 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped! 149 17/01/23 19:38:08 INFO SparkContext: Successfully stopped SparkContext 150 17/01/23 19:38:08 INFO ShutdownHookManager: Shutdown hook called 151 17/01/23 19:38:08 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon. 152 17/01/23 19:38:08 INFO ShutdownHookManager: Deleting directory /tmp/spark-1be891d5-88d1-4e02-970b-023ff1e8c618/httpd-b73f26ff-5d13-4abd-953b-164a3f2d18e7 153 17/01/23 19:38:08 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports. 154 17/01/23 19:38:08 INFO ShutdownHookManager: Deleting directory /tmp/spark-1be891d5-88d1-4e02-970b-023ff1e8c618 155 17/01/23 19:38:08 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.
13. 使用Java语言编写Spark的WordCount程序
上面我们使用Scala语言编写了一个Spark的WordCount程序,并成功提交了到Spark集群上进行了运行。现在我们在同一个工程中使用Java语言也编写一个Spark的WordCount单词计数程序。
1) 修改pom文件内容
原来的pom文件中只有一个编译scala程序的Maven插件,现在我们要编译java程序,就需要引入java的Maven编译插件。
完整的pom.xml文件内容如下(替换原来的pom文件内容,对原来scala版的WordCount程序不会有影响):
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.xuebusi</groupId> <artifactId>spark</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.10.6</scala.version> <spark.version>1.6.2</spark.version> <hadoop.version>2.6.4</hadoop.version> </properties> <dependencies> <!-- 如果我们仅使用java来编写spark程序,可以不导此包 --> <!-- scala的语言核心包 --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <!-- Hadoop的客户端 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <!-- spark的核心包 --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> </dependency> </dependencies> <build> <pluginManagement> <plugins> <!-- scala-maven-plugin:编译scala程序的Maven插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </plugin> <!-- maven-compiler-plugin:编译java程序的Maven插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> </plugin> </plugins> </pluginManagement> <plugins> <!-- 编译scala程序的Maven插件的一些配置参数 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <executions> <execution> <id>scala-compile-first</id> <phase>process-resources</phase> <goals> <goal>add-source</goal> <goal>compile</goal> </goals> </execution> <execution> <id>scala-test-compile</id> <phase>process-test-resources</phase> <goals> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <!-- 编译java程序的Maven插件的一些配置参数 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <executions> <execution> <phase>compile</phase> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <!-- maven-shade-plugin:打jar包用的Mavne插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
2) 刷新依赖
pom文件准备好以后,需要点击右侧的Maven Project中的刷新按钮,才会真正导入Maven依赖。如果本地的Maven仓库中缺少相关的依赖,Maven会自动到中央仓库中下载依赖的jar包,所以要求电脑必须能够联网。
3) 创建JavaWordCount类
在src/main/java目录下面创建JavaWordCount类:
完整的JavaWordCount类代码如下:
package com.xuebusi.spark; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; import java.util.Arrays; /** * 这里我们仅使用Java的API编写一个简单的Spark应用程序, * 对数据做简单的处理,业务比较简单, * 在实际项目中可能要结合较为复杂的业务逻辑, * 比如操作数据库,操作HDFS/Kafka/Hbase等, * 或者和其他的第三方的组件进行整合等等; * 如果你对Scala语言不熟悉,你可以使用Java, * 没有倾向说哪一种语言更好, * 但是只要java能够完成的功能,scala也可以; * * Created by SYJ on 2017/1/23. */ public class JavaWordCount { /** * main方法的快捷键:psvm * 自动补全变量名的快捷键:Ctrl+Alt+V * * 由于JDK1.7版本还不支持函数式编程, * 所以你会看到给很多方法传递参数时, * 大量使用到了匿名类; * * 其实使用Java来编写Spark程序并不难, * 很多代码都不用我们自己写, * 因为IDEA开发工具提供了很好的代码提示和代码自动 * 补全功能--根据提示使用Tab键可以快速补全代码; * @param args */ public static void main(String[] args) { //创建SparkConf,并指定应用程序名称 SparkConf conf = new SparkConf().setAppName("JavaWordCount"); //创建JavaSparkContext JavaSparkContext sc = new JavaSparkContext(conf); //从文件系统读取数据 //注意在Java的数组取下标使用中括号args[0],而scala使用小括号args(0) //其实JavaRDD继承了Spark的RDD,对其做了扩展 JavaRDD<String> lines = sc.textFile(args[0]); /** * 切分单词 * * FlatMapFunction是匿名类, * 它的两个参数中,第一个参数是输入的数据类型, * 第二个参数是输出的数据类型; * 这里输入一行数据line,返回一个迭代器, * 迭代器中装的一行文本被按照空格切分后的单词; */ JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String line) throws Exception { return Arrays.asList(line.split(" ")); } }); /** * 每个单词每出现一次就计数为1 * 在scala中调用的是map方法,而在java中调用的则是mapToPair方法, * mapToPair方法表示将一个map变成一个元组; * * 匿名函数PairFunction的泛型有3个: * (1)第一个参数表示输入,这里输入的是单词; * (2)第二个和第三个参数是返回的元组中的两个元素的数据类型,这里返回的是单词和数字1; * * 在java中没有Tuple类型的数据结构,所以它就搞了一个Tuple2类来模拟Scala中的Tuple; */ JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String word) throws Exception { return new Tuple2<String, Integer>(word, 1); } }); /** * 分组聚合 * * 我们可以调用GroupByKey方法,但是它的效率比较低, * 我们可以调用ReduceByKey方法,它会先在局部聚合, * 然后再全局聚合,相当于有一个Combine的功能; * * reducebyKey需要一个Function2类型的匿名类, * 这个Function2有3个泛型,前两个类型表示要对输入的两个数字进行叠加, * 最后一个类型表示返回两个数字叠加后的和; * reducebyKey只对value进行聚合,而key不用管; */ JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer i1, Integer i2) throws Exception { return i1 + i2; } }); /** * 反转,反转是为了后面的排序 */ JavaPairRDD<Integer, String> swapedPair = counts.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() { @Override public Tuple2<Integer, String> call(Tuple2<String, Integer> tp) throws Exception { //将元组中数据交换位置的第一种方式(下面还有第二种方式) return new Tuple2<Integer, String>(tp._2, tp._1); } }); /** * 排序 * * java只提供了sortByKey,它只能按照key进行排序, * 而我们要按照value来排序,所以需要先将元组中的两个 * 元素进行反转,在根据key进行排序,最后再反转回来; */ JavaPairRDD<Integer, String> sortedPair = swapedPair.sortByKey(false); JavaPairRDD<String, Integer> finalResult = sortedPair.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Integer, String> tp) throws Exception { //将元组中的数据交换位置的第二种方式(swap就是交换的意思) return tp.swap(); } }); //将结果存储到文件系统 finalResult.saveAsTextFile(args[1]); //释放资源 sc.stop(); } }
4) 运行程序
将编写好的JavaWordCount程序打成jar包并上传到Spark集群服务器。
在运行程序之前,检查一下hdfs上是否已经存在“/wordcount/output”目录,若存在则删除。
在集群环境都正常运行的前提下,使用如下命令来运行我们的JavaWordCount程序,注意要使用“—class”来指定要运行的类为“com.xuebusi.spark.JavaWordCount”:
/root/apps/spark/bin/spark-submit --master spark://hadoop01:7077,hadoop02:7077 \ --executor-memory 512m --total-executor-cores 7 --class com.xuebusi.spark.JavaWordCount /root/spark-1.0-SNAPSHOT.jar hdfs://hadoop01:9000/wordcount/input \ hdfs://hadoop01:9000/wordcount/output
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
标签:传递 instance let profile jar 参数 track ant pre
原文地址:http://www.cnblogs.com/jun1019/p/6346870.html
