标签:connect 监听 mode specified 截屏 讲解 保存 win chunk
demo截图:
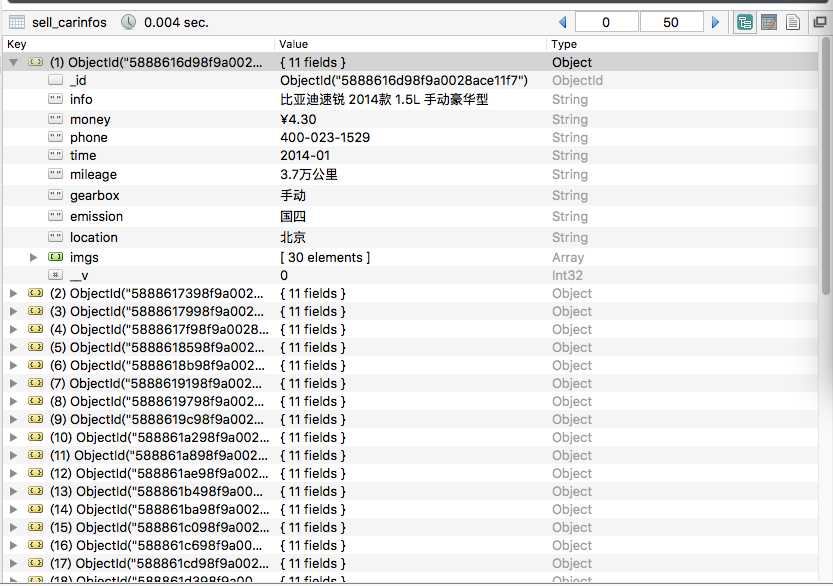
本demo爬瓜子二手车北京区的数据 (注:需要略懂 node.js / mongodb 不懂也没关系 因为我也不懂啊~~~)
之所以选择爬瓜子二手车网站有两点:
一、网站无需登录,少做模拟登录;
二、数据连接没有加密,直接可以用;
网上很多node.js爬虫的栗子
但大多是一个页面的栗子,很少跟数据库结合的 所以我这个栗子是糖炒的
我的基本思路是这样的
1、先在mongodb里存所有页的连接地址的集合
2、在根据这些链接地址 一个一个的把详细信息爬下来
第一步在搜索页找到翻页的规律
像搜索页北京区第一页就是
https://www.guazi.com/bj/buy/o1/
第二页
https://www.guazi.com/bj/buy/o2/
规律就是
https://www.guazi.com/bj/buy/o + number
然后第一页的时候你就可以知道最多50页
这样你就可以循环这些链接在把每个页面的车的详情连接存到mongodb的集合里
第二步读mongodb的集合找出所有的连接 循环连接爬详情页数据
项目目录:
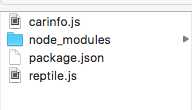
目录讲解:
reptile.js //爬所有连接的;
carinfo.js //爬车辆详情页;
package.json //配置文件
package.json:
1 { 2 "name": "sell-car", 3 "version": "1.0.0", 4 "description": "", 5 "main": "index.js", 6 "scripts": { 7 "test": "echo \"Error: no test specified\" && exit 1" 8 }, 9 "author": "", 10 "license": "ISC", 11 "devDependencies": { 12 "cheerio": "^0.22.0", 13 "mongoose": "^4.7.1" 14 } 15 }
reptile.js 存mongodb集合 在cmd执行的 node reptile.js
1 ‘use strict‘; 2 var http = require(‘https‘); //node https 模块; 3 var cheerio = require(‘cheerio‘); //解析html模块; 4 var mongoose = require(‘mongoose‘); //操作mongodb数据库模块; 5 mongoose.connect(‘mongodb://localhost/car‘); //连接数据库; 6 7 var num = 0; //当前第几页; 8 var maxNum = 0; //最大页数; 9 10 var url = ‘https://www.guazi.com/bj/buy/o‘; //瓜子二手车搜索页北京区; 11 12 var PersonSchema = new mongoose.Schema({ //json的结构; 13 address:String //定义一个属性name,类型为String 14 }); 15 16 var sellCar = mongoose.model(‘sell_car‘, PersonSchema ); //创建model 17 18 19 fetchPage(url+1); //主程序开始运行 20 21 function fetchPage(x) { //封装了一层函数 22 startRequest(x); 23 } 24 25 function startRequest(x) { 26 //采用http模块向服务器发起一次get请求 27 http.get(x, function (res) { 28 29 var html = ‘‘; //用来存储请求网页的整个html内容 30 var titles = []; 31 res.setEncoding(‘utf-8‘); //防止中文乱码 32 //监听data事件,每次取一块数据 33 res.on(‘data‘, function (chunk) { 34 35 html += chunk; 36 37 }); 38 39 //监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数 40 res.on(‘end‘, function () { 41 42 var $ = cheerio.load(html); //采用cheerio模块解析html 43 44 var $a_src = $(‘.imgtype‘); //读取出当前搜索页每辆车详情的地址; 45 46 $a_src.each(function(i,obj){ //循环每地址连接存入数据库; 47 48 var _src = $(obj).attr(‘href‘); 49 50 51 var carHref = new sellCar({ address: _src }); //存入mongodb; 52 carHref.save(function (err) { 53 if (err) { 54 console.log(err); 55 } 56 }); 57 58 }) 59 60 num++; //页码增加; 61 62 if( num == 1 ){ //判断是第一次,给最大页数赋值; 63 maxNum = $(‘.pageLink li‘).eq($(‘.pageLink li‘).length-2).find(‘span‘).text(); 64 } 65 66 if( num == maxNum ){ //页数等于最大页数等值程序; 67 return ; 68 } 69 70 fetchPage(url+num); 71 72 }); 73 74 }); 75 }
carinfo.js 车辆详情 在cmd执行 node carinfo.js
1 ‘use strict‘; 2 var http = require(‘https‘); //node https 模块; 3 var cheerio = require(‘cheerio‘); //解析html模块; 4 var mongoose = require(‘mongoose‘); //操作mongodb数据库模块; 5 mongoose.connect(‘mongodb://localhost/car‘); //连接数据库; 6 7 var readCarPer = new mongoose.Schema({ //json的结构; 8 address:String 9 }); 10 11 var PersonSchema = new mongoose.Schema({ //定义json类型; 12 info:String, //车; 13 money:String, //价钱; 14 phone:String, //电话号码; 15 time:String, //上牌时间; 16 mileage:String, //公里数; 17 gearbox:String, //变速箱; 18 emission:String, //排放标准; 19 location:String, //上牌地; 20 imgs:Array //图片; 21 }); 22 23 var num = 0; 24 var readCar = mongoose.model(‘sell_cars‘,readCarPer); 25 var sellCarInfo = mongoose.model(‘sell_carInfo‘, PersonSchema ); 26 27 var json = null; 28 var url = ‘https://www.guazi.com‘; //补连接前边的连接; 29 var time = null; //间隔时间; 30 var maxNum = 0; 31 32 33 readCar.find({},function(err, character){ //查找数据; 34 35 console.log(‘成功读取地址‘); 36 37 if(err){ 38 console.log(err); 39 }else{ 40 json = character; 41 maxNum = json.length; 42 43 calls(); 44 45 } 46 47 }) 48 49 50 function calls(){ 51 num++; 52 if( num > maxNum ){ //判断是否霸区成功; 53 console.log(‘数据爬去完成~~~‘); 54 return false; 55 } 56 57 clearTimeout(time); 58 var lu = json[num].address; 59 60 time = setTimeout(function(){ 61 62 fetchPage(url+lu); //主程序开始运行 63 64 },5000); 65 66 } 67 68 function fetchPage(x) { //封装了一层函数 69 startRequest(x); 70 } 71 72 function startRequest(x) { 73 console.log(x); 74 //采用http模块向服务器发起一次get请求 75 http.get(x, function (res) { 76 77 var html = ‘‘; //用来存储请求网页的整个html内容 78 var titles = []; 79 res.setEncoding(‘utf-8‘); //防止中文乱码 80 //监听data事件,每次取一块数据 81 res.on(‘data‘, function (chunk) { 82 83 html += chunk; 84 85 }); 86 87 //监听end事件,如果整个网页内容的html都获取完毕,就执行回调函数 88 res.on(‘end‘, function () { 89 90 var $ = cheerio.load(html); //采用cheerio模块解析html 91 92 var info = $(‘.dt-titletype‘).text() //车名; 93 var money = $(‘.numtype‘).text(); //钱; 94 var phone = $(‘.teltype‘).eq(0).text(); //电话 95 var time = $(‘.assort li‘).eq(0).find(‘b‘).text(); //上牌时间 96 var mileage = $(‘.assort li‘).eq(1).find(‘b‘).text(); //里程数 97 var gearbox = $(‘.assort li‘).eq(2).find(‘b‘).text(); //变速箱 98 var emission = $(‘.assort li‘).eq(3).find(‘b‘).text(); //排放标准 99 var location = $(‘.assort li‘).eq(4).find(‘b‘).text(); //上牌地 100 101 var $imgs = $(‘.dt-pictype img‘); 102 var imgs = []; 103 104 $imgs.each(function(i,obj){ //图片循环赋值; 105 var img_src = $(obj).attr(‘data-original‘); 106 imgs.push(img_src); 107 }); 108 109 var carInfos = new sellCarInfo({ //保存数据; 110 info:info, 111 money:money, 112 phone:phone, 113 time:time, 114 mileage:mileage, 115 gearbox:gearbox, 116 emission:emission, 117 location:location, 118 imgs:imgs 119 }); 120 121 carInfos.save(function (err) { 122 if (err) { 123 console.log(err); 124 } else { 125 console.log(‘成功数据!~~~‘); 126 calls(); 127 } 128 }); 129 130 }); 131 132 }); 133 }
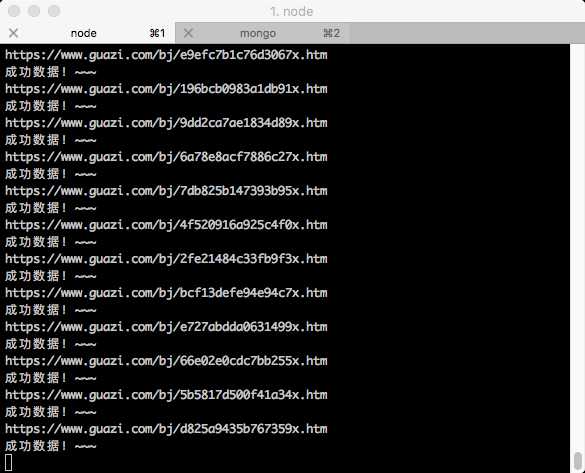
当时爬数据的截屏:
后记:
这里我没说 mongodb 安装、启动、设置存储地址 是因为 mongodb本身在window和mac其实是不一样的所以需要你自己在找找别的文章看看怎么配置(注:window跑真的挺蛋疼的。。。。欢迎去感受一下)
这个栗子的第一个条件就是你要现在cmd里跑起来mongodb 要不剩下的都是白瞎
简单的mongodb的增删改查看看 菜鸟教程 就行 实在不行用Robomongo图形界面也行
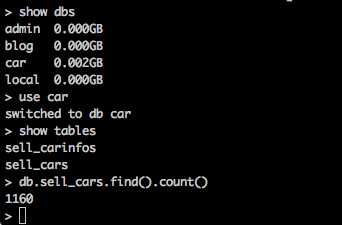
说一个小问题
就是我在爬搜索的车辆连接的时候 因为下一页设置的间隔时间比较短 原本2000条的数据最后只爬下来1160,所以爬车辆详情的时候把间隔调成了5秒 需要注意一下;
如图:
参考资料:
小小石头的那些事儿 : http://blog.csdn.net/yezhenxu1992/article/details/50820629
菜鸟教程 : http://www.runoob.com/mongodb/mongodb-tutorial.html
标签:connect 监听 mode specified 截屏 讲解 保存 win chunk
原文地址:http://www.cnblogs.com/auok/p/6349842.html