标签:通过 调整 位置 rar 搜索 rom plain 其他 分析
转自:http://blog.csdn.net/caomiao2006/article/details/52140993
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作。当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算。所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引。
在MySQL 中,GROUP BY 的实现同样有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成 GROUP BY,另外一种为完全无法使用索引的场景下使用。下面我们分别针对这三种实现方式做一个分析。
1、使用松散(Loose)索引扫描实现 GROUP BY
何谓松散索引扫描实现 GROUP BY 呢?实际上就是当 MySQL 完全利用索引扫描来实现 GROUP BY 的时候,并不需要扫描所有满足条件的索引键即可完成操作得出结果。
下面我们通过一个示例来描述松散索引扫描实现 GROUP BY,在示例之前我们需要首先调整一下 group_message 表的索引,将 gmt_create 字段添加到 group_id 和 user_id 字段的索引中:
然后再看如下 Query 的执行计划:
sky@localhost: example 09:26:15> EXPLAIN -> SELECT user_id,max(gmt_create) -> FROM group_message -> WHERE group_id < 10 -> GROUP BY group_id,user_id\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: group_message type: range possible_keys: idx_gid_uid_gc key: idx_gid_uid_gc key_len: 8 ref: NULL rows: 4 Extra: Using where; Using index for group-by
我们看到在执行计划的 Extra 信息中有信息显示“Using index for group-by”,实际上这就是告诉我们,MySQL Query Optimizer 通过使用松散索引扫描来实现了我们所需要的 GROUP BY 操作。
下面这张图片描绘了扫描过程的大概实现:
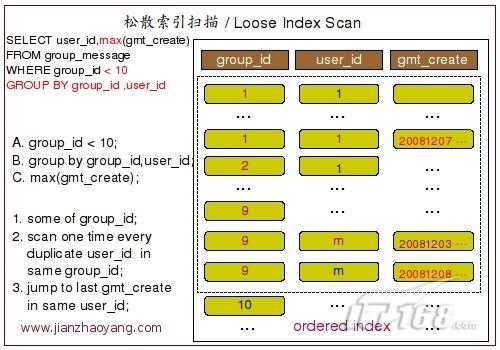
要利用到松散索引扫描实现 GROUP BY,需要至少满足以下几个条件:
◆GROUP BY 条件字段必须在同一个索引中最前面的连续位置;
◆在使用GROUP BY 的同时,只能使用 MAX 和 MIN 这两个聚合函数;
◆如果引用到了该索引中 GROUP BY 条件之外的字段条件的时候,必须以常量形式存在;
为什么松散索引扫描的效率会很高?
因为在没有WHERE子句,也就是必须经过全索引扫描的时候, 松散索引扫描需要读取的键值数量与分组的组数量一样多,也就是说比实际存在的键值数目要少很多。而在WHERE子句包含范围判断式或者等值表达式的时候, 松散索引扫描查找满足范围条件的每个组的第1个关键字,并且再次读取尽可能最少数量的关键字。
2.使用紧凑(Tight)索引扫描实现 GROUP BY
紧凑索引扫描实现 GROUP BY 和松散索引扫描的区别主要在于他需要在扫描索引的时候,读取所有满足条件的索引键,然后再根据读取恶的数据来完成 GROUP BY 操作得到相应结果。
sky@localhost : example 08:55:14> EXPLAIN -> SELECT max(gmt_create) -> FROM group_message -> WHERE group_id = 2 -> GROUP BY user_id\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: group_message type: ref possible_keys: idx_group_message_gid_uid,idx_gid_uid_gc key: idx_gid_uid_gc key_len: 4 ref: const rows: 4 Extra: Using where; Using index 1 row in set (0.01 sec)
这时候的执行计划的 Extra 信息中已经没有“Using index for group-by”了,但并不是说 MySQL 的 GROUP BY 操作并不是通过索引完成的,只不过是需要访问 WHERE 条件所限定的所有索引键信息之后才能得出结果。这就是通过紧凑索引扫描来实现 GROUP BY 的执行计划输出信息。
下面这张图片展示了大概的整个执行过程:
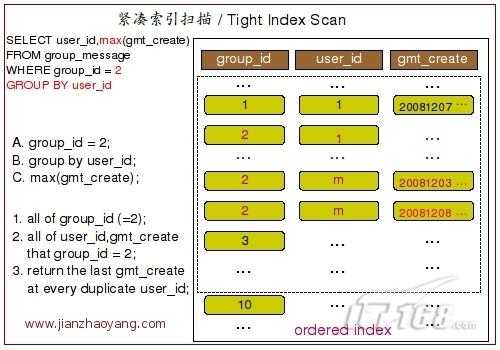
在 MySQL 中,MySQL Query Optimizer 首先会选择尝试通过松散索引扫描来实现 GROUP BY 操作,当发现某些情况无法满足松散索引扫描实现 GROUP BY 的要求之后,才会尝试通过紧凑索引扫描来实现。
当 GROUP BY 条件字段并不连续或者不是索引前缀部分的时候,MySQL Query Optimizer 无法使用松散索引扫描,设置无法直接通过索引完成 GROUP BY 操作,因为缺失的索引键信息无法得到。但是,如果 Query 语句中存在一个常量值来引用缺失的索引键,则可以使用紧凑索引扫描完成 GROUP BY 操作,因为常量填充了搜索关键字中的“差距”,可以形成完整的索引前缀。这些索引前缀可以用于索引查找。而如果需要排序GROUP BY结果,并且能够形成索引前缀的搜索关键字,MySQL还可以避免额外的排序操作,因为使用有顺序的索引的前缀进行搜索已经按顺序检索到了所有关键字。
3.使用临时表实现 GROUP BY
MySQL 在进行 GROUP BY 操作的时候要想利用所有,必须满足 GROUP BY 的字段必须同时存放于同一个索引中,且该索引是一个有序索引(如 Hash 索引就不能满足要求)。而且,并不只是如此,是否能够利用索引来实现 GROUP BY 还与使用的聚合函数也有关系。
前面两种 GROUP BY 的实现方式都是在有可以利用的索引的时候使用的,当 MySQL Query Optimizer 无法找到合适的索引可以利用的时候,就不得不先读取需要的数据,然后通过临时表来完成 GROUP BY 操作。
sky@localhost : example 09:02:40> EXPLAIN -> SELECT max(gmt_create) -> FROM group_message -> WHERE group_id > 1 and group_id < 10 -> GROUP BY user_id\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: group_message type: range possible_keys: idx_group_message_gid_uid,idx_gid_uid_gc key: idx_gid_uid_gc key_len: 4 ref: NULL rows: 32 Extra: Using where; Using index; Using temporary; Using filesort
这次的执行计划非常明显的告诉我们 MySQL 通过索引找到了我们需要的数据,然后创建了临时表,又进行了排序操作,才得到我们需要的 GROUP BY 结果。整个执行过程大概如下图所展示:
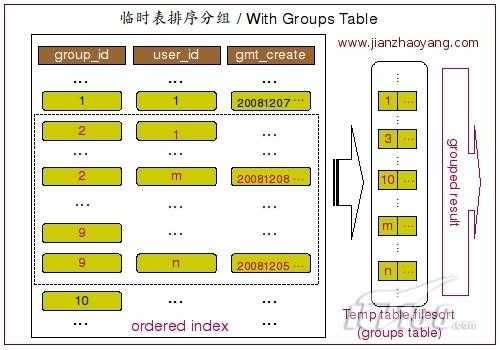
当 MySQL Query Optimizer 发现仅仅通过索引扫描并不能直接得到 GROUP BY 的结果之后,他就不得不选择通过使用临时表然后再排序的方式来实现 GROUP BY了。
在这样示例中即是这样的情况。 group_id 并不是一个常量条件,而是一个范围,而且 GROUP BY 字段为 user_id。所以 MySQL 无法根据索引的顺序来帮助 GROUP BY 的实现,只能先通过索引范围扫描得到需要的数据,然后将数据存入临时表,然后再进行排序和分组操作来完成 GROUP BY。
SQL group by底层原理——本质是排序,可以利用索引事先排好序
标签:通过 调整 位置 rar 搜索 rom plain 其他 分析
原文地址:http://www.cnblogs.com/bonelee/p/6359250.html