标签:开始 规律 char 例子 分享 function 批量下载 index 使用
上一篇博客讲解了使用nodejs爬取博客园的博文,这次带给大家的是下载网络上的图片。
需要用到的第三方模块有:
superagent
superagent-charset (手动改指定编码,解决GBK中文乱码)
cheerio
express
async (并发控制)
完整的代码,可以在我的github中可以下载。主要的逻辑逻辑在 netbian.js 中。
以彼岸桌面(http://www.netbian.com/)栏目下的风景壁纸(http://www.netbian.com/fengjing/index.htm)为例进行讲解。

不难发现:
首页: 栏目/index.htm
分页: 栏目/index_具体页码.htm
知道这个规律,就可以批量下载壁纸了。
使用chrome的开发者工具,可以发现,缩略图列表在 class="list"的div里,a标签的href属性的值就是单张壁纸所在的页面。
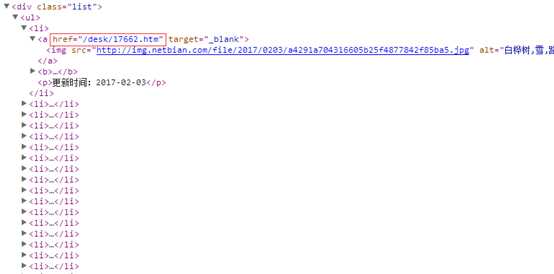
部分代码:
1 request 2 .get(url) 3 .end(function(err, sres){ 4 5 var $ = cheerio.load(sres.text); 6 var pic_url = []; // 中等图片链接数组 7 $(‘.list ul‘, 0).find(‘li‘).each(function(index, ele){ 8 var ele = $(ele); 9 var href = ele.find(‘a‘).eq(0).attr(‘href‘); // 中等图片链接 10 if(href != undefined){ 11 pic_url.push(url_model.resolve(domain, href)); 12 } 13 }); 14 });
打开这个页面,发现此页面显示的壁纸,依旧不是最高的分辨率。
点击“下载壁纸”按钮里的链接,打开新的页面。
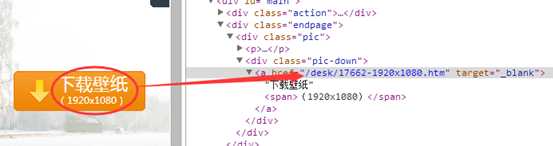
打开这个页面,我们最终要下载的壁纸,放在一个table里面。如下图,http://img.netbian.com/file/2017/0203/bb109369a1f2eb2e30e04a435f2be466.jpg
才是我们最终要下载的图片的URL(幕后BOSS终于现身了(@ ̄ー ̄@))。

下载图片的代码:
request .get(wallpaper_down_url) .end(function(err, img_res){ if(img_res.status == 200){ // 保存图片内容 fs.writeFile(dir + ‘/‘ + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, ‘binary‘, function(err){ if(err) console.log(err); }); } });
打开浏览器,访问 http://localhost:1314/fengjing
选择栏目和页面,点击“开始”按钮:

并发请求服务器,下载图片。
完成~

图片的存放目录按照 栏目+页码 的形式保存。
附上完整的图片下载的代码:
1 /** 2 * 下载图片 3 * @param {[type]} url [图片URL] 4 * @param {[type]} dir [存储目录] 5 * @param {[type]} res [description] 6 * @return {[type]} [description] 7 */ 8 var down_pic = function(url, dir, res){ 9 10 var domain = ‘http://www.netbian.com‘; // 域名 11 12 request 13 .get(url) 14 .end(function(err, sres){ 15 16 var $ = cheerio.load(sres.text); 17 var pic_url = []; // 中等图片链接数组 18 $(‘.list ul‘, 0).find(‘li‘).each(function(index, ele){ 19 var ele = $(ele); 20 var href = ele.find(‘a‘).eq(0).attr(‘href‘); // 中等图片链接 21 if(href != undefined){ 22 pic_url.push(url_model.resolve(domain, href)); 23 } 24 }); 25 26 var count = 0; // 并发计数器 27 var wallpaper = []; // 壁纸数组 28 var fetchPic = function(_pic_url, callback){ 29 30 count++; // 并发加1 31 32 var delay = parseInt((Math.random() * 10000000) % 2000); 33 console.log(‘现在的并发数是:‘ + count + ‘, 正在抓取的图片的URL是:‘ + _pic_url + ‘ 时间是:‘ + delay + ‘毫秒‘); 34 setTimeout(function(){ 35 // 获取大图链接 36 request 37 .get(_pic_url) 38 .end(function(err, ares){ 39 var $$ = cheerio.load(ares.text); 40 var pic_down = url_model.resolve(domain, $$(‘.pic-down‘).find(‘a‘).attr(‘href‘)); // 大图链接 41 42 count--; // 并发减1 43 44 // 请求大图链接 45 request 46 .get(pic_down) 47 .charset(‘gbk‘) // 设置编码, 网页以GBK的方式获取 48 .end(function(err, pic_res){ 49 50 var $$$ = cheerio.load(pic_res.text); 51 var wallpaper_down_url = $$$(‘#endimg‘).find(‘img‘).attr(‘src‘); // URL 52 var wallpaper_down_title = $$$(‘#endimg‘).find(‘img‘).attr(‘alt‘); // title 53 54 // 下载大图 55 request 56 .get(wallpaper_down_url) 57 .end(function(err, img_res){ 58 if(img_res.status == 200){ 59 // 保存图片内容 60 fs.writeFile(dir + ‘/‘ + wallpaper_down_title + path.extname(path.basename(wallpaper_down_url)), img_res.body, ‘binary‘, function(err){ 61 if(err) console.log(err); 62 }); 63 } 64 }); 65 66 wallpaper.push(wallpaper_down_title + ‘下载完毕<br />‘); 67 }); 68 callback(null, wallpaper); // 返回数据 69 }); 70 }, delay); 71 }; 72 73 // 并发为2,下载壁纸 74 async.mapLimit(pic_url, 2, function(_pic_url, callback){ 75 fetchPic(_pic_url, callback); 76 }, function (err, result){ 77 console.log(‘success‘); 78 res.send(result[0]); // 取下标为0的元素 79 }); 80 }); 81 };
1. “彼岸桌面”网页的编码是“GBK”的。而nodejs本身只支持“UTF-8”编码。这里我们引入“superagent-charset”模块,用于处理“GBK”的编码。
附上github里的一个例子
https://github.com/magicdawn/superagent-charset

2. nodejs是异步的,同一时间发送大量的请求,有可能被服务器认为是恶意请求而拒绝。 因此这里引入“async”模块,用于并发的处理,使用的方法是:mapLimit。
mapLimit(arr, limit, iterator, callback)
这个方法有4个参数:
第1个参数是数组。
第2个参数是并发请求的数量。
第3个参数是迭代器,通常是一个函数。
第4个参数是并发执行后的回调。
这个方法的作用是将arr中的每个元素同时并发limit次拿给iterator去执行,执行结果传给最后的callback。
至此,便完成了图片的下载。
完整的代码,已经放在github上,欢迎star (☆▽☆)。
文笔有限,才学疏浅,若有不正确的地方,欢迎广大博友指正。
标签:开始 规律 char 例子 分享 function 批量下载 index 使用
原文地址:http://www.cnblogs.com/slion/p/6366213.html