标签:汉字 提交表单 显示 upgrade 求和 请求 重定向 传输协议 常用
时间:2016-11-8 17:27
1、安装HttpWatch
HttpWatch是专门为IE浏览器提供的,用来查看HTTP请求和响应内容的工具,而FireFox中需要安装FireBug软件,如果使用的是Chrome,则自带该工具。
HttpWatch和FireBug这些工具对浏览器而言不是必须的,但是对开发者而言是很有必要的。
2、HTTP协议概述
HTTP(Hypertext Transport Protocol),即超文本传输协议,这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式,其实我们要学习的就是这两个格式,客户端发送给服务器的格式叫请求协议,服务器发送给客户端的格式叫响应协议。
3、请求协议
GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94 Safari/537.36
Accept-Encoding: gzip, deflate, sdch
Accept-Language: zh-CN,zh;q=0.8
Cookie:BAIDUID=F378432AF02E4E9588BE281E70CE90FD:FG=1;PSTM=1463898874;BIDUPSID=B7FD726534FF48A1BEFBBBF020666FA8;BD_UPN=12314753;H_PS_645EC=f7884Bb21yMdzvGXzPzxr5ao0gSUCXQswXirG4%2F7c0UF5dPOETZqY09eMCsHfDODHsdQ6hvi
请求行
多个请求头信息(相当于键值对)
格式:头名称:头值
空行
正文(请求体,也就是request提交的数据)
get请求无请求体,但是必须有空行。get请求先解析URI,然后再解析后面的值。
POST请求是可以有请求体的,但是get请求不能有请求体。
post请求是直接解析请求体。
Accept:服务器可以支持哪些资源类型,告诉服务器可以返回哪些类型的资源。
Accept-Language:浏览器支持什么语言。
User-Agent:将客户端详细信息发送给服务器。
Accept-Encoding:支持编码格式。
gzip:支持的压缩格式
Host:本地主机,主机名+请求行中的资源路径,就构成了访问路径。
HTTP/1.1:协议
Connection:Keep-Alive,代表连接一小会儿。(HTTP1.1之后出现的技术)
Keep-Alive的意义是:访问一个页面的时候,可能会发送多个请求,这样保持连接会节约资源提高速度,可以使页面当中的多个请求使用一个连接发送完毕。
HTTP协议其实是无状态协议:
也就是只访问一次,访问一次后就失效,并不保存请求记录。协议的状态是指下一次传输可以“记住”这次传输信息的能力。HTTP是不会为了下一次连接而维护这次连接所传输的信息,为了保证服务器内存,因为HTTP所占用的链接资源是非常大的。比如客户获得一张网页之后关闭浏览器,然后再一次启动浏览器,再登陆该网站,但是服务器并不知道客户关闭了一次浏览器。所以HTTP协议是无状态协议。
DNS是有状态协议:
服务器知道多个请求都是同一个对象发送的。 由于Web服务器要面对很多浏览器的并发访问,为了提高Web服务器对并发访问的处理能力,在设计HTTP协议时规定Web服务器发送HTTP应答报文和文档时,不保存发出请求的Web浏览器进程的任何状态信息。这有可能出现一个浏览器在短短几秒之内两次访问同一对象时,服务器进程不会因为已经给它发过应答报文而不接受第二次服务请求。由于Web服务器不保存发送请求的Web浏览器进程的任何信息,因此HTTP协议属于无状态协议(Stateless Protocol)。
FTP协议也是有状态的协议。
==========================================================
POST /day08_1/index.jsp HTTP/1.1
Host: localhost:8080
Connection: keep-alive
Content-Length: 27
Cache-Control: max-age=0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.94Safari/537.36
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.8
Cookie: JSESSIONID=C7F91F409FA744A79669A4E6E46647D6; ECS[visit_times]=3
username=2222&password=3333
Content-Length:请求体的长度
当使用表单提交数据的时候,如果method为post,则请求行会改为post,如果表单内有数据,则会同时发送请求体:
username=2222&password=3333
也就是说,表单内种的所有内容,最终会使用一行字符串发送给服务器。
Content-Type: application/x-www-form-urlencoded,表示表单中的数据会自动使用URL来进行编码,如果编码格式不正确,并且在提交表单的时候包含了不匹配的字符(例如不支持中文的编码但是提交了中文字符),会出现以下情况:
username=%CE%CA%CE%CA&password=aaa
也就是乱码。
在服务器相应客户端时,如果响应的是文本:text/html,则后面必须加上文本编码:charset=ISO-8859-1
每个字节的范围是-128~127
URL编码处理方式:
1)先通过字符编码变成字节
2)首先让字节数+128
3)将字节转换为16进制
4)给每个字符添加%前缀
防止丢失字节。
超链接中如果出现中文,则不会进行URL编码。
——URL编码
URL编码是一种浏览器用来打包表单输入的格式。浏览器从表单中获取所有的name和其中的值 ,将它们以name/value参数编码(移去那些不能传送的字符,将数据排行等等)作为URL的一部分或者分离地发给服务器。不管哪种情况,在服务器端的表单输入格式样子象这样:
theName=Ichabod+Crane&gender=male&status=missing& ;headless=yes
URL编码遵循下列规则: 每对name/value由&符分开;每对来自表单的name/value由=符分开。如果用户没有输入值给这个name,那么这个name还是出现,只是无值。任何特殊的字符(就是那些不是简单的七位ASCII,如汉字)将以百分符%用十六进制编码,当然也包括象 =,&;,和 % 这些特殊的字符。其实URL编码就是一个字符ascii码的十六进制。不过稍微有些变动,需要在前面加上“%”。比如“\”,它的ascii码是92,92的十六进制是5c,所以“\”的url编码就是%5c。那么汉字的url编码呢?很简单,看例子:“胡”的ascii码是-17670,十六进制是BAFA,url编码是“%BA%FA”。
URL编码平时是用不到的,因为IE会自动将输入到地址栏的非数字字母转换为url编码。曾有人提出数据库名字里带上“#”以防止被下载,因为IE遇到#就会忽略后面的字母。破解方法很简单——用url编码%23替换掉#。
编码问题是JAVA初学者在web开发过程中经常会遇到问题,其中之一是URL中使用中文等非ASCII的字符造成服务器后台程序解析出现乱码的问题。
常见出错部分
也就是容易出现中文字符的部分:
(1)Query String中的参数值
(2)servlet path
常见出错原因
(1)浏览器:我们的客户端(浏览器)本身并没有遵循URL编码的规范。
(2)Servlet服务器:Servlet服务器的没有正确配置。
(3)开发人员并不了解Servlet的规范和API的含义。
servlet规范
(1)HttpServletRequest.setCharacterEncoding()
方法仅仅只适用于设置post提交的requestboda的编码而不是设置get方法提交的queryString的编码。该方法告诉应用服务器应该采用什么编码解析post传过来的内容。
(2)HttpServletRequest.getPathInfo()
返回的结果是由Servlet服务器解码(decode)过的。
(3)HttpServletRequest.getRequestURI()
返回的字符串没有被Servlet服务器decoded过。
(4)POST提交的数据是作为request body的一部分。
(5) 网页的Http头中ContentType("text/html; charset=GBK")的作用:
(a) 告诉浏览器网页中数据是什么编码;
(b) 表单提交时,通常浏览器会根据ContentType指定的charset对表单中的数据编码,然后发送给服务器的。
注意:这里所说的ContentType是指http头的ContentType,而不是在网页中meta中的ContentType。
——Referer请求头
Referer:说明请求来自哪个页面,例如在百度上点击链接到了该网页,那么就是:Referer:
http://www.baidu.com,如果是在浏览器的地址栏中直接输入地址进行访问,那么就没有Referer这个请求头了。常用于判定是否是指定链接发出的请求。
Referer请求头是比较有用的一个请求头,他可以用来做统计工作,也可以用来做防盗链。
统计工作:
我公司网站在百度上做了广告,但不知道在百度上做广告对我们网站的访问量是否有影响,那么可以对每个请求中的Referer进行分析,如果Referer链接百度居多,那么说明用户都是通过百度找到我们公司网站的。
防盗链:
我公司网站有一个下载链接,而其他网站盗链了这个地址,例如在我公司网站内download.html页面中有一个下载链接,点击即可下载JDK,但是有某人在微博中盗链了这个资源,它也有一个链接指向我们公司网站的下载地址,也就是说登录他的微博点击链接就可以下载我公司网站的资源,这导致我们网站的广告没有被访问,但是下载的却是我公司网站的资源,这时可以使用Referer进行防盗链操作,在资源被下载之前,我们对Referer进行判断,如果请求来自本网站,那么允许下载,否则先跳转到广告页,再下载。
=======================================================================================
4、响应协议
HTTP/1.1 200 OK
Content-Length: 8120
Content-Encoding: gzip
Date: Sun, 22 May 2016 14:53:38 GMT
Server: BWS/1.1
Content-Type: text/html; charset=utf-8
Connection: Keep-Alive
响应行(协议/版本 状态码 状态码的解析)
状态码以2开头全都代表响应成功。
以3开头代表全部需要转接。
以4开头全都代表客户端出错。
404代表客户端错误,表示访问了一个不存在的页面。
以5开头全都代表服务器的错误。
500代表服务器错误,也就是说代码出Exception了。
响应头(Key/Value格式)
空行
响应正文(响应体)
响应正文就是由服务器发送给浏览器的内容,浏览器会根据相应内容来显示。
Server:服务器名称。
Content-Type:相应内容的MIME类型。
Context-Type: text/html;charset=utf-8
表示该文件是文本类型,并且是格式为HTML的文本类型,编码格式是utf-8。(文本格式必须有编码)
Content-Length:该文本有多少字节。
Date:响应时间,可能会有八个小时的时区差。
其他响应头:
告诉浏览器不要缓存的响应头:
Exprires:-1(过期时间,-1代表马上过期)
Cache-Control:no-cache
Pragma:no-cache
(Cache-Control和Pragma兼容HTTP1.0和HTTP1.1两个版本)
自动刷新响应头,浏览器会在三秒之后请求http://www.baidu.com
Refresh:3;url=http://www.baidu.com
HTML中指定响应头:
在HTML页面中可以使用<meta http-equlv="" content="">来指定响应头,例如在index.html页面中给出<meta http-equlv="Refresh" content="3;url=http://www.baidu.com">,表示浏览器将会在显示index.html页面3秒之后自动跳转到http://www.baidu.com
其中<meta>标签可以指定响应头,http-equiv代表名(键),content代表值(值)。
<meta http-equiv="cache-control" content="no-cache" >
等价于:
cache-control:no-cache
响应码:
200:请求成功,浏览器会把响应体内容(通常是HTML)显示在浏览器中。
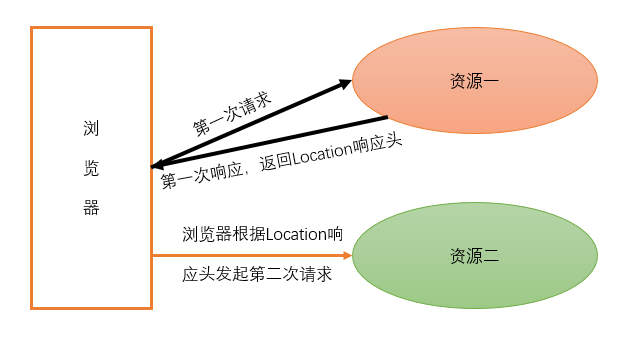
302:重定向,当响应码为302时,表示服务器要求浏览器重新再发送一个请求,服务器会发送一个响应头Location,它
指定了新请求的URL地址,此时浏览器接收响应体之后,会再次请求Location所指定的路径。
404:请求的资源没有找到,说明客户端请求了不存在的资源,通常是资源路径不对。
405:服务器不支持该请求。
500:请求资源找到了,但服务器内部出现了错误,通常是代码抛异常了。
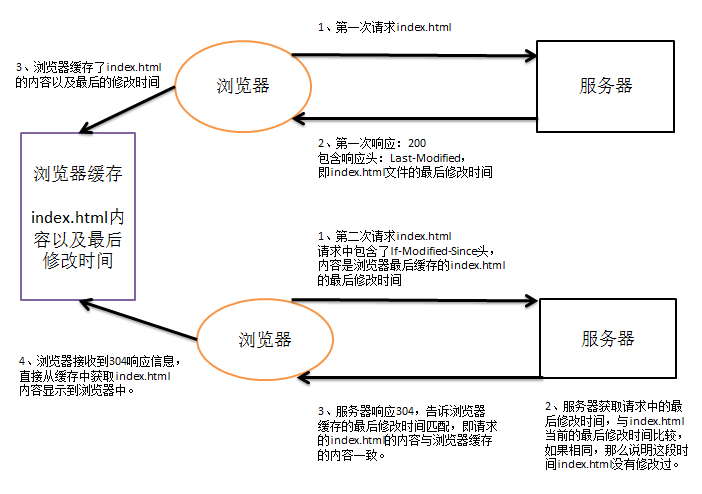
304:当用户第一次请求index.html时,服务器会添加一个名为Last-Modified的响应头,这个头说明了index.html的最后修改时间,浏览器会吧index.html的内容以及最后响应时间缓存下来,当用户第二次请求index.html时,在请求中会包含一个名为If-Modified-Since的请求头,它的值就是第一次请求时服务器通过Last-Modified响应头发送给浏览器的值,即index.html最后的修改时间,If-Modified-Since请求头就是在告诉服务器,我这里浏览器缓存的index.html最后修改时间是这个,你看看现在的index.html最后修改时间是不是这个,如果是,那么就不需要在响应新的index.html内容了,我会把缓存的内容直接显示出来。而服务器端会获取If-Modified-Since的值,与index.html的当前最后修改时间做对比,如果相同,服务器会发送响应码304,表示index.html与浏览器上次缓存的相同,无需再次发送相应内容,浏览器可以显示自己的缓存页面;如果对比不同,那么说明index.html已经做了修改,服务器会响应200。通常情况下只有静态页面才会有304,动态页面一般不做缓存。
Last-Modified:最后的修改时间。
If-Modified-Since:把上次请求的index.html的最后修改时间返还给服务器。
当Last-Modified与If-Modified-Since一致时,服务器会响应304,而不会响应正文。
重定向:
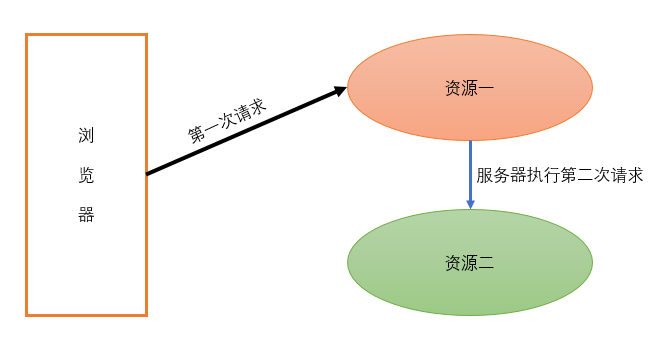
请求转发:
HTTP协议
标签:汉字 提交表单 显示 upgrade 求和 请求 重定向 传输协议 常用
原文地址:http://www.cnblogs.com/wwwwyc/p/6375255.html