标签:不同 参数 状态 time ini ret strip print 如何
with open(‘james.txt‘) as jaf:
data = jaf.readLine()
james = data.strip().split(‘,‘) #先去掉空格而否有,号分隔, 这叫做方法串联.
这样会得到 james 是一个列表(数组)
在原有的列表中排序, 和新建一个列表排序两种
原有列表排序: james.sort()
新建列表排序: james2 = sorted(james)
调整数据格式函数
def sanitize(time_string):
if ‘-‘ in time_string:
splitter = ‘-‘
elif ‘:‘ in time_string:
splitter = ‘:‘
else:
return(time_string)
(mins, secs) = time_string.split(splitter)
return (mins + ‘.‘ + secs)
for each_tin in james:
clean_james.append(sanitize(each_t))
更简便的方法是: (列表推到)
clean_james = [sanitize(each_t) for each_t in james]
在列表中, 前边部分是for循环中每一部分的转换, 后边是一个for循环, 类似的还有:
secs = [m * 60 for m in mins]
upper = [s.upper() for s in lower]
注意, 不能使用 sorted(sanitize(t)), 应该记住, 一次只会对一个列表项完成转换, 而不是对整个列表. sorted()函数是对一列表序, 而不是针对单个的数据项.
如何删除重复项
除了列表, python还提供了集合数据结构, 它的表现类似于在数学课上学到的集合. python中集合最突出的特性是集合中的数据项是无序的. 而且不许重复, 如果试图向一个集合增加一个数据项, 而该集合中已经包含有这个数据项, python就会忽略.
distances = set() #空集合, set 是内置函数, 工厂函数, 工厂函数用于创建某种类型的新的数据项(对象)
也可以 distances = {10.6, 11, 8, "two", 7}
distances = set(james) # james 中所有的重复项, 都会被去除
列表, 我们知道正常的数组, a[0], a[1] 等等, 但是在python中可以使用 a[0:3] 这表示要 a[0], a[1], a[2]
字典, key : value 的关联关系. (也叫 "映射", "散列")
cal = {} #空字典
pel = dict() # 工厂函数, 创建了一个空字典
通过 key, value 关联
cal[‘Name‘] = ‘John cla‘
cal[‘Address‘] = [‘aa‘,‘bb‘,‘cc‘]
pel = {‘Name‘:‘haha‘, ‘Address‘:‘shen‘}
print(cal[‘Address‘][-1]) # ‘cc‘
与列表不同, python 字典不会维持插入的顺序, 关于字典, 重点是它会维护关联关系, 而不是顺序.
把代码与数据放在一起是对的, 毕竟, 函数只有在数据关联时才有意义. 不过怎么做到呢? 类
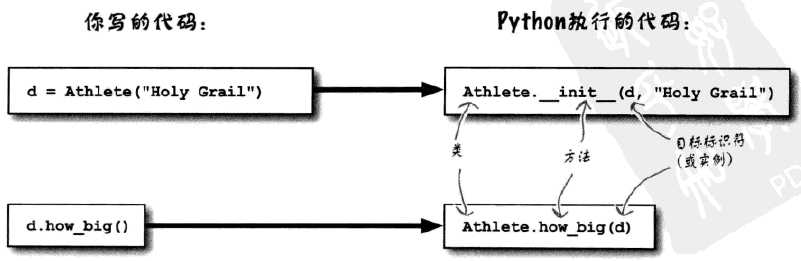
class 创建对象, 每个定义的类都有一个特殊的方法, 名为 __init__(), 可以通过这个方法控制初始化.
class Athlete:
def __init__(self):
# initialize
创建实例: a = Athlete() #工厂函数
与C++系列语言不同, python中没有定义构造函数"new"的概念, python会为你完成对象的构建, 然后你可以使用__init__()方法定制对象初始状态.
self 指向被创建的实例
python 要求每个方法的第一个参数为self. (这里指的是python执行的代码)
标签:不同 参数 状态 time ini ret strip print 如何
原文地址:http://www.cnblogs.com/moveofgod/p/6391697.html