标签:指定 用法 目录 特殊字符 找不到 笔记 format 制表符 file
定义:元素以引号包围的、元素可以是任意类型的有序的不可修改的序列;
定义字符串:
str() 如:a = str(1234)
‘‘ 如:a = ‘nihao‘
"" 如:a = "nihao"
‘‘‘ ‘‘‘, """ """ 如:a = ‘‘‘nihao‘‘‘, a = """nihao"""
注意:
当需要用到缩写如I‘m时,就不能用单引号来定义字符串,而需要用双引号,如:
a = "I‘m lizihao, hello world!!!"
当字符串内容很大,需要分几行书写时,需要用三引号,单引号跟双引号都不支持回车换行,如:
>>> a = ‘‘‘I‘m lizihao,
hello world!!
hello beijing!!‘‘‘
注意区分三引号用于定义多行字符串跟注释多行的区别,将三引号定义的字符串赋值给某个变量的时候,三引号起到的就是定义字符串的功能;如果没有赋值给变量,只是单独的三引号包括住多行文字,则起到的是注释多行的功能;
特殊字符:
\n 换行符
\t table符、水平制表符
\v 垂直制表符
字符的转义:
在任何语言里都存在转义符这样的概念,转义符是让有特殊意义的字符失去特殊意义,以普通的形式打印出来;python中有两种转义符:\和%
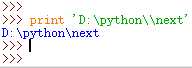
1、\ 执行print ‘D:\python\next‘

比如上面的代码中,路径里面有个尴尬的目录‘\next‘,之所以会得到这样的结果,是因为python将这个目录中的\n看成了特殊字符换行符,所以打印的时候分行了;
遇到这种情况就需要对\n进行转义,\\n将这两个字符变成普通的没有特殊意义的字符,执行:print ‘D:\python\\next‘
2、% 百分号的转义作用,主要体现在字符串格式化时,执行:
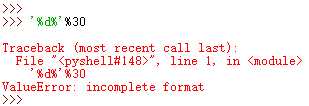
字符串的格式化后面会专门来讲,这句话的意思是想说让%d来代替后面的30,想要输出‘30%‘,但是在字符串的格式化式中,百分号有了特殊的意义,不在单纯指代百分号,所以%d后面的%拿来作为普通的百分号使用就会报错,这时候需要用到%自身的转义功能,且其转义功能只能用来转义其本身,也就是说在字符串格式化中用两个百分号‘%%‘来表示普通的百分号,将%的特殊意义去除,执行:

字符串的格式化:
占位符:%s、%d、%f
1、%s
用来指代字符串,体会一把:

在前面一句中%s类似于一个变量且变量要求是字符串类型,在字符串后面的%表示格式化符号,格式化符号后面表示%s应该取得值,这里是‘xiaoming‘,这样做为什么就能做到格式化呢,因为变量的值可以是任意的值,也就是格式化符%后面的字符串可以是任意的,在下面一句就是变成了‘xiaohong‘;
到后面学到更多的比如随机数,那么格式化符%后面的值可以更加的多样化;
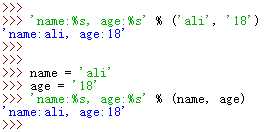
一个格式化的字符串中,可以有多个占位符,在后面取值时,需要用括号括起来;
>>>
>>> ‘%s‘ % ‘x‘
‘x‘
>>> ‘%10s‘ % ‘y‘
‘ y‘
%ns可用来指定字符串为n位,正值表示从左边数扩充n位;
>>> ‘%-8s‘ % ‘z‘
‘z ‘
%-ns可用来指定字符串为n位,负值表示从右侧开始扩充n位;
>>>
2、%d
用来指代整型
>>>
>>> ‘%d$‘ % 30
‘30$‘
>>> ‘%d$‘ % 30.8
‘30$‘
只能给整形数占位,浮点数通过%d占位,会自动转换成整形;后面的$只是随意给的单位,表示30美元;
3、%f
可通过%f占位浮点数,默认转换成6为小数,可通过%0.nf来限定保留n为小数,0可省略;
>>> ‘%f$‘ % 30.8
‘30.800000$‘
>>> ‘%0.1f$‘ % 30.8
‘30.8$‘
>>> ‘%.3f$‘ % 30.8
‘30.800$‘
>>>
format格式化字符串:
>>>
>>> name = ‘lizihao‘
>>> age = 26
>>> ‘name:{0}, age:{1}‘.format(name, age)
‘name:lizihao, age:26‘
>>>
>>> name = ‘lizihao‘
>>> age = 26
>>> ‘name:{1}, age:{3}‘.format(0, name, ‘haha‘, age)
‘name:lizihao, age:26‘
>>>
注意,{}里面的数字表示的时候后面取值的索引位,表示取括号中第几位的值,索引为是从0开始,0位表示括号中的第1个元素;
字符串的索引与分片:
>>> s = ‘abcdefghijklmn‘
>>> s[0]
‘a‘
>>> s[13]
‘n‘
>>> s[-1]
‘n‘
>>> s[-3]
‘l‘
索引值为负数时,表示从右向左取;
>>> s[25]
Traceback (most recent call last):
File "<pyshell#86>", line 1, in <module>
s[25]
IndexError: string index out of range
当索引数超过元素的个数,报错索引错误;
>>> s[0:4]
‘abcd‘
分片只包含左边,不包含右边,即能取到第0位的元素,取不到第4位的元素,取截取的一个片段;
>>> s[3:8]
‘defgh‘
截取从第3位到第7位的片段;
>>> s[:4]
‘abcd‘
>>> s[5:]
‘fghijklmn‘
>>> s[2:8:3]
‘cf‘
从第2位到第8位,步进为3
>>> s[:]
‘abcdefghijklmn‘
复制一个字符串;
>>> s[::]
‘abcdefghijklmn‘
开始、结束、步进都没给定,也复制该字符串;
>>> s[::2]
‘acegikm‘
步进2的字符串;
>>> s[::-1]
‘nmlkjihgfedcba‘
步进为-1则获得倒序的字符串
>>> s[::-2]
‘nljhfdb‘
获得倒序的步进为2的字符串;
>>> s[0:8:-2]
‘‘
只能当不给定开始跟结束的范围时才能用负值的步进,即只能[::-n],否则获得空字符串;
字符串函数的用法:
字符串填充
字符串删减
字符串变形
字符串切分
字符串连接
字符串判定
字符串查找
字符串替换
字符串编码
1.字符串的切分: split、rsplit、splitlines
>>> s = ‘hello world welcome‘
>>> s.split()
[‘hello‘, ‘world‘, ‘welcome‘]
当没有给定参数时,默认以字符串中的空格切分,切分后的结果以列表形式返回;
>>> s.split(‘o‘)
[‘hell‘, ‘ w‘, ‘rld welc‘, ‘me‘]
给定一个字符串中存在的元素为参数,则以该元素切分;给定不存在的元素,返回原字符串本身;
>>> s.split(‘o‘, 2)
[‘hell‘, ‘ w‘, ‘rld welcome‘]
给定存在的元素并给定一个值,则按元素切分且只切分给定的值的次数;
split默认从左边开始搜索进行切分,rsplit是从右边开始搜索进行切分;
>>> s.rsplit(‘o‘, 2)
[‘hello w‘, ‘rld welc‘, ‘me‘]
splitlines([keepends]) 按照行(‘\r‘, ‘\r\n‘, \n‘)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
>>> str1 = ‘ab c\n\nde fg\rkl\r\n‘
>>> str2 = ‘ab c\n\nde fg\rkl\r\n‘
>>>
>>> str1.splitlines()
[‘ab c‘, ‘‘, ‘de fg‘, ‘kl‘]
>>> str2.splitlines(True)
[‘ab c\n‘, ‘\n‘, ‘de fg\r‘, ‘kl\r\n‘]
2.字符串的删减: strip、rstrip、lstrip
>>> s = ‘ hello ‘
>>> s.strip()
‘hello‘
>>> s.rstrip()
‘ hello‘
>>> s.lstrip()
‘hello ‘
不给定参数时,默认删除空格,strip删两边,rstrip删右侧,lstrip删左边;
>>> s = ‘dddhelloddd‘
>>> s.strip(‘d‘)
‘hello‘
>>> s.rstrip(‘d‘)
‘dddhello‘
>>> s.lstrip(‘d‘)
‘helloddd‘
当给定参数时,删除参数给定的字符,有几个删几个;
3.字符串的填充: center、ljust、rjust、zfill、expandtabs
>>> s = ‘hello‘
>>> s.center(20)
‘ hello ‘
>>> s.ljust(20)
‘hello ‘
>>> s.rjust(20)
‘ hello‘
只给定数值,则字符串扩充为给定的数值位数,原字符串center居中,ljust左对齐,rjust右对齐;
>>> s = ‘hello‘
>>> s.center(20, ‘*‘)
‘*******hello********‘
>>> s.ljust(20, ‘*‘)
‘hello***************‘
>>> s.rjust(20, ‘*‘)
‘***************hello‘
当给定了数值且给定了字符,则以给定的字符扩充至给定的数值位数,对齐方式同上;
>>> s.zfill(20)
‘000000000000000hello‘
zfill给定是以’0’进行填充,且固定是右侧对齐,效果等同于s.rjust(20, ‘0’);
zfill主要是用在(1, 2, 23, 85, 120)转换成(001, 002, 023, 085, 120)
expandtabs是在字符串中有tab空格时,修改tab键的长度,默认一个tab键是8个空白格;
>>> s = ‘a\tb‘
>>> print(s)
a b
>>> s.expandtabs(10)
‘a b‘
4.字符串的查找:find、index、count
>>> s = ‘hello world welcome‘
>>> s.find(‘x‘)
-1
用find查找,找不到元素时,返回-1
>>> s.find(‘o‘)
4
默认从左侧开始查找,返回第一个对应元素的索引位
>>> s.find(‘o‘, 5)
7
给定第一个数值,表示从第5位开始,查找最近的元素返回索引位;
>>> s.find(‘o‘, 8, 10)
-1
find跟index在能查找到元素时的用法是一样的,不同的是当参数中给定的元素不再字符串中时,find返回-1,而index返回报错,报参数异常;
>>> s.index(‘o‘, 8, 10)
Traceback (most recent call last):
File "<pyshell#163>", line 1, in <module>
s.index(‘o‘, 8, 10)
ValueError: substring not found
>>>
>>> s.count(‘o‘)
3
>>> s.count(‘o‘, 8)
1
>>> s.count(‘o‘, 2, 8)
2
>>> s.count(‘x‘)
0
用count查找实际上是查找给定的元素在字符串中的个数,给定第一个数值,表示从该数值位开始查找,第二个数值表示结束范围,当给定的参数元素在字符串中找不到时,返回0,即字符串中有0个该元素;
标签:指定 用法 目录 特殊字符 找不到 笔记 format 制表符 file
原文地址:http://www.cnblogs.com/zanjiahaoge666/p/6395034.html