标签:字符集 之间 字符编码 跨语言 unicode chinese 中文字符集 包括 系统
计算机中的数据是以二进制方式进行存储的,即只有"0"和"1",二进制是属于数据类型的数据,它只可以和其他进制的数据类型进行转换,但是不能存储其他字符,例如:字母,特殊字符等,所以人们创建了一张表,这张表是一张10进制的数字和字符的对应表格,这个表格就叫做ASCII(American Standard Code for Information Interchange 美国信息交换标准代码)表,主要用于显示现代英语和其他西欧语言,如下:
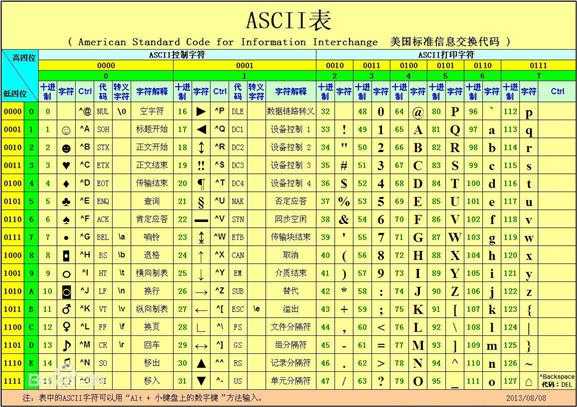
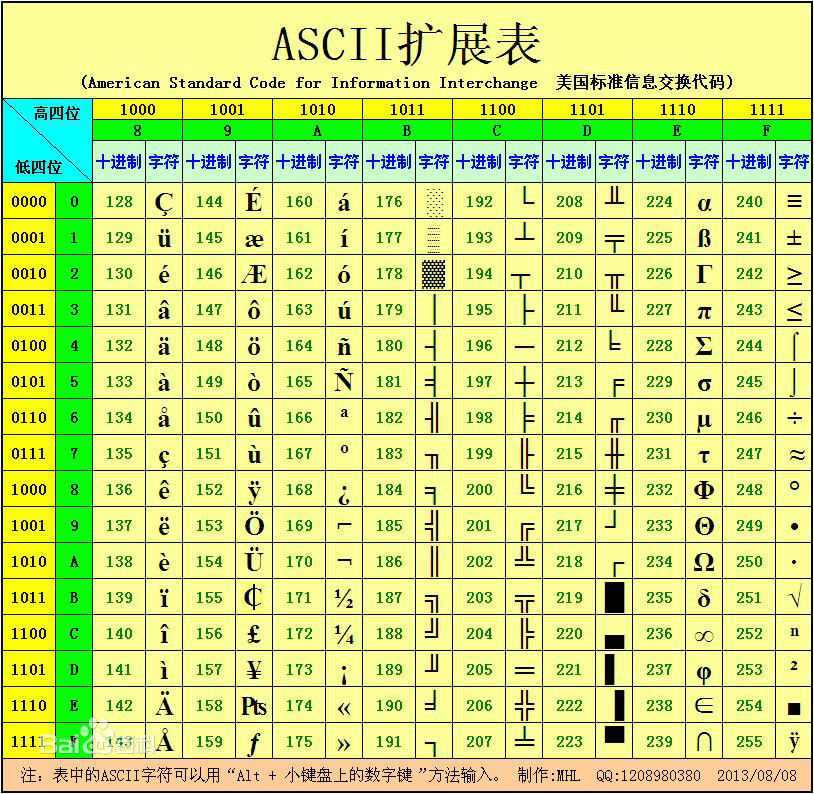
现在人们可以在计算机中存储数据了,但是只能存储英语和其他西欧的语言,其他语言的国家的数据无法存储,例如:中国,日本,韩国等地方的语言,因此人们又发明了新的字符编码表,对ASCII进行扩展,在ASCII表中建立索引指向新的编码表,中国地区使用的扩展字符编码表叫“GB2312(信息交换用汉字编码字符集)”,用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。共收入汉字6763个和非汉字图形字符682个。
因为GB2312存储的数据太少,所以又发布了新的扩展表,对现有的汉字表进行扩展,"GBK1.0(Chinese Internal Code Specification 汉字内码扩展规范)"。共收入 21886 个汉字和图形符号,其中汉字(包括部首和构件)21003 个,图形符号 883 个。到了2000年的时候,由信息产业部和国家质量技术监督局在2000年 3月17日联合发布的新的标准“gb18030(信息技术中文编码字符集)”,并且将作为一项国家标准在2001年的1月正式强制执行。是我国自主研制的以汉字为主并包含多种我国少数民族文字(如藏、蒙古、傣、彝、朝鲜、维吾尔文等)的超大型中文编码字符集强制性标准,其中收入汉字70000余个。
现在可以存储很多中文数据了,但是人们常用汉字字符不是太多,所以windows中会有一个默认缺省的中文内码表,即“GBK”。
但是现在要进行全世界的语言进行通信,显然ASCII不能实现,所以人们又发明了新的编码格式,即,Unicode(统一码、万国码、单一码)。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。1990年开始研发,1994年正式公布。Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
在python版本系列中,2.x默认是不支持中文字符集,所以需要在脚本头指定编码格式:
#!/usr/bin/env python #-*- coding:utf-8 -*-
但是在3.x中默认编码格式是utf-8,即,支持中文字符,不需要再指定字符编码格式!
标签:字符集 之间 字符编码 跨语言 unicode chinese 中文字符集 包括 系统
原文地址:http://www.cnblogs.com/topspeedking/p/6397159.html