标签:domain pos 架构 buffers else 基本 数据包 何事 可靠性
BIO:同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO:同步非阻塞式IO,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO(NIO.2):异步非阻塞式IO,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
同步阻塞式IO,相信每一个学习过操作系统网络编程或者任何语言的网络编程的人都很熟悉,在while循环中服务端会调用accept方法等待接收客户端的连接请求,一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成。
如果BIO要能够同时处理多个客户端请求,就必须使用多线程,即每次accept阻塞等待来自客户端请求,一旦受到连接请求就建立通信套接字同时开启一个新的线程来处理这个套接字的数据读写请求,然后立刻又继续accept等待其他客户端连接请求,即为每一个客户端连接请求都创建一个线程来单独处理,大概原理图就像这样:
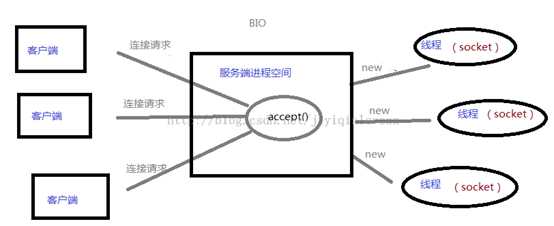
虽然此时服务器具备了高并发能力,即能够同时处理多个客户端请求了,但是却带来了一个问题,随着开启的线程数目增多,将会消耗过多的内存资源,导致服务器变慢甚至崩溃,NIO可以一定程度解决这个问题。
同步非阻塞式IO,关键是采用了事件驱动的思想来实现了一个多路转换器。
NIO与BIO最大的区别就是只需要开启一个线程就可以处理来自多个客户端的IO事件,这是怎么做到的呢?
就是多路复用器,可以监听来自多个客户端的IO事件:
A. 若服务端监听到客户端连接请求,便为其建立通信套接字(java中就是通道),然后返回继续监听,若同时有多个客户端连接请求到来也可以全部收到,依次为它们都建立通信套接字。
B. 若服务端监听到来自已经创建了通信套接字的客户端发送来的数据,就会调用对应接口处理接收到的数据,若同时有多个客户端发来数据也可以依次进行处理。
C. 监听多个客户端的连接请求和接收数据请求同时还能监听自己时候有数据要发送。
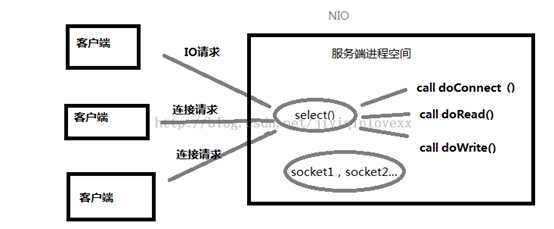
总之就是在一个线程中就可以调用多路复用接口(java中是select)阻塞同时监听来自多个客户端的IO请求,一旦有收到IO请求就调用对应函数处理。
异步IO:
异步 I/O 是一种没有阻塞地读写数据的方法。通常,在代码进行 read() 调用时,代码会阻塞直至有可供读取的数据。同样, write()调用将会阻塞直至数据能够写入。
异步 I/O 的一个优势在于,它允许您同时根据大量的输入和输出执行 I/O。同步程序常常要求助于轮询,或者创建许许多多的线程以处理大量的连接。使用异步 I/O,您可以监听任何数量的通道上的事件,不用轮询,也不用额外的线程。
Buffer和Channel是标准NIO中的核心对象,几乎每一个IO操作中都会用到它们。
Channel是对原IO中流的模拟,任何来源和目的数据都必须通过一个Channel对象。一个Buffer实质上是一个容器对象,发给Channel的所有对象都必须先放到Buffer中;同样的,从Channel中读取的任何数据都要读到Buffer中。
Buffer是一个对象,它包含一些要写入或读出的数据。在NIO中,数据是放入buffer对象的,而在IO中,数据是直接写入或者读到Stream对象的。应用程序不能直接对 Channel 进行读写操作,而必须通过 Buffer 来进行,即 Channel 是通过 Buffer 来读写数据的。
在NIO中,所有的数据都是用Buffer处理的,它是NIO读写数据的中转池。Buffer实质上是一个数组,通常是一个字节数据,但也可以是其他类型的数组。但一个缓冲区不仅仅是一个数组,重要的是它提供了对数据的结构化访问,而且还可以跟踪系统的读写进程。
使用 Buffer 读写数据一般遵循以下四个步骤:
当向 Buffer 写入数据时,Buffer 会记录下写了多少数据。一旦要读取数据,需要通过 flip() 方法将 Buffer 从写模式切换到读模式。在读模式下,可以读取之前写入到 Buffer 的所有数据。
当向 Buffer 写入数据时,Buffer 会记录下写了多少数据。一旦要读取数据,需要通过 flip() 方法将 Buffer 从写模式切换到读模式。在读模式下,可以读取之前写入到 Buffer 的所有数据。
Buffer主要几种:
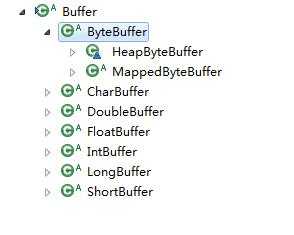
Channel是一个对象,可以通过它读取和写入数据。可以把它看做IO中的流。但是它和流相比还有一些不同:
正如上面提到的,所有数据都通过Buffer对象处理,所以,您永远不会将字节直接写入到Channel中,相反,您是将数据写入到Buffer中;同样,您也不会从Channel中读取字节,而是将数据从Channel读入Buffer,再从Buffer获取这个字节。
因为Channel是双向的,所以Channel可以比流更好地反映出底层操作系统的真实情况。特别是在Unix模型中,底层操作系统通常都是双向的。
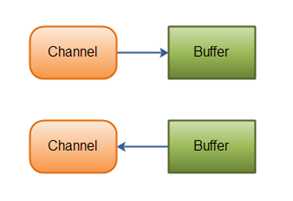
在Java NIO中Channel主要有如下几种类型:
IO中的读和写,对应的是数据和Stream,NIO中的读和写,则对应的就是通道和缓冲区。NIO中从通道中读取:创建一个缓冲区,然后让通道读取数据到缓冲区。NIO写入数据到通道:创建一个缓冲区,用数据填充它,然后让通道用这些数据来执行写入。
我们已经知道,在NIO系统中,任何时候执行一个读操作,您都是从Channel中读取,而您不是直接从Channel中读取数据,因为所有的数据都必须用Buffer来封装,所以您应该是从Channel读取数据到Buffer。
因此,如果从文件读取数据的话,需要如下三步:
下面我们看一下具体过程:
第一步:获取通道
FileInputStream fin = new FileInputStream( "readandshow.txt" );
FileChannel fc = fin.getChannel();
第二步:创建缓冲区
ByteBuffer buffer = ByteBuffer.allocate( 1024 );第三步:将数据从通道读到缓冲区
fc.read( buffer );第一步:获取一个通道
FileOutputStream fout = new FileOutputStream( "writesomebytes.txt" );FileChannel fc = fout.getChannel();第二步:创建缓冲区,将数据放入缓冲区
ByteBuffer buffer = ByteBuffer.allocate( 1024 );for (int i=0; i<message.length; ++i) { buffer.put( message[i] );}buffer.flip();第三步:把缓冲区数据写入通道中
fc.write( buffer );CopyFile是一个非常好的读写结合的例子,我们将通过CopyFile这个实力让大家体会NIO的操作过程。CopyFile执行三个基本的操作:创建一个Buffer,然后从源文件读取数据到缓冲区,然后再将缓冲区写入目标文件。
/**
* 用java NIO api拷贝文件
* @param src
* @param dst
* @throws IOException
*/
public static void copyFileUseNIO(String src,String dst) throws IOException{
//声明源文件和目标文件
FileInputStream fi=new FileInputStream(new File(src));
FileOutputStream fo=new FileOutputStream(new File(dst));
//获得传输通道channel
FileChannel inChannel=fi.getChannel();
FileChannel outChannel=fo.getChannel();
//获得容器buffer
ByteBuffer buffer=ByteBuffer.allocate(1024);
while(true){
//判断是否读完文件
int eof =inChannel.read(buffer);
if(eof==-1){
break;
}
//重设一下buffer的position=0,limit=position
buffer.flip();
//开始写
outChannel.write(buffer);
//写完要重置buffer,重设position=0,limit=capacity
buffer.clear();
}
inChannel.close();
outChannel.close();
fi.close();
fo.close();
}
Selector是一个对象,它可以注册到很多个Channel上,监听各个Channel上发生的事件,并且能够根据事件情况决定Channel读写。这样,通过一个线程管理多个Channel,就可以处理大量网络连接了。
有了Selector,我们就可以利用一个线程来处理所有的channel。线程之间的切换对操作系统来说代价是很高的,并且每个线程也会占用一定的系统资源。所以,对系统来说使用的线程越少越好。
但是,需要记住,现代的操作系统和CPU在多任务方面表现的越来越好,所以多线程的开销随着时间的推移,变得越来越小了。实际上,如果一个CPU有多个内核,不使用多任务可能是在浪费CPU能力。不管怎么说,关于那种设计的讨论应该放在另一篇不同的文章中。在这里,只要知道使用Selector能够处理多个通道就足够了。
下面这幅图展示了一个线程处理3个 Channel的情况:
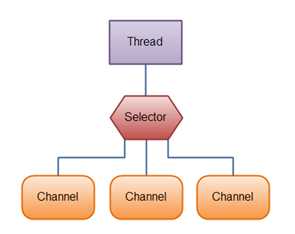
如何创建一个Selector:
异步 I/O 中的核心对象名为 Selector。Selector 就是您注册对各种 I/O 事件兴趣的地方,而且当那些事件发生时,就是这个对象告诉您所发生的事件。
Selector selector = Selector.open();然后,就需要注册Channel到Selector了
如何注册Channel到Selector:
为了能让Channel和Selector配合使用,我们需要把Channel注册到Selector上。通过调用 channel.register()方法来实现注册:
channel.configureBlocking(false);SelectionKey key =channel.register(selector,SelectionKey.OP_READ);注意,注册的Channel 必须设置成异步模式 才可以,,否则异步IO就无法工作,这就意味着我们不能把一个FileChannel注册到Selector,因为FileChannel没有异步模式,但是网络编程中的SocketChannel是可以的。
需要注意register()方法的第二个参数,它是一个“interest set”,意思是注册的Selector对Channel中的哪些时间感兴趣,事件类型有四种:
通道触发了一个事件意思是该事件已经 Ready(就绪)。所以,某个Channel成功连接到另一个服务器称为 Connect Ready。一个ServerSocketChannel准备好接收新连接称为 Accept Ready,一个有数据可读的通道可以说是 Read Ready,等待写数据的通道可以说是Write Ready。
上面这四个事件对应到SelectionKey中的四个常量:
1. SelectionKey.OP_CONNECT
2. SelectionKey.OP_ACCEPT
3. SelectionKey.OP_READ
4. SelectionKey.OP_WRITE
如果你对多个事件感兴趣,可以通过or操作符来连接这些常量:
int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
关于SelectionKey
请注意对register()的调用的返回值是一个SelectionKey。 SelectionKey 代表这个通道在此 Selector 上的这个注册。当某个 Selector 通知您某个传入事件时,它是通过提供对应于该事件的 SelectionKey 来进行的。SelectionKey 还可以用于取消通道的注册。SelectionKey中包含如下属性:
Interest Set
就像我们在前面讲到的把Channel注册到Selector来监听感兴趣的事件,interest set就是你要选择的感兴趣的事件的集合。你可以通过SelectionKey对象来读写interest set:
int interestSet = selectionKey.interestOps();
boolean isInterestedInAccept = interestSet & SelectionKey.OP_ACCEPT;
boolean isInterestedInConnect = interestSet & SelectionKey.OP_CONNECT;
boolean isInterestedInRead = interestSet & SelectionKey.OP_READ;
boolean isInterestedInWrite = interestSet & SelectionKey.OP_WRITE;
通过上面例子可以看到,我们可以通过用AND 和SelectionKey 中的常量做运算,从SelectionKey中找到我们感兴趣的事件。
Ready Set
ready set 是通道已经准备就绪的操作的集合。在一次选Selection之后,你应该会首先访问这个ready set。Selection将在下一小节进行解释。可以这样访问ready集合:
int readySet = selectionKey.readyOps();
可以用像检测interest集合那样的方法,来检测Channel中什么事件或操作已经就绪。但是,也可以使用以下四个方法,它们都会返回一个布尔类型:
selectionKey.isAcceptable();
selectionKey.isConnectable();
selectionKey.isReadable();
selectionKey.isWritable();
Channel 和Selector
我们可以通过SelectionKey获得Selector和注册的Channel:
Channel channel = selectionKey.channel();
Selector selector = selectionKey.selector();
Attach 一个对象
可以将一个对象或者更多信息attach 到SelectionKey上,这样就能方便的识别某个给定的通道。例如,可以附加 与通道一起使用的Buffer,或是包含聚集数据的某个对象。使用方法如下:
selectionKey.attach(theObject);
Object attachedObj = selectionKey.attachment();
Attach 一个对象
可以将一个对象或者更多信息attach 到SelectionKey上,这样就能方便的识别某个给定的通道。例如,可以附加 与通道一起使用的Buffer,或是包含聚集数据的某个对象。使用方法如下:
selectionKey.attach(theObject);
Object attachedObj = selectionKey.attachment();
还可以在用register()方法向Selector注册Channel的时候附加对象。如:
SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject);
通过Selector选择通道
一旦向Selector注册了一或多个通道,就可以调用几个重载的select()方法。这些方法返回你所感兴趣的事件(如连接、接受、读或写)已经准备就绪的那些通道。换句话说,如果你对“Read Ready”的通道感兴趣,select()方法会返回读事件已经就绪的那些通道:
select()方法返回的int值表示有多少通道已经就绪。亦即,自上次调用select()方法后有多少通道变成就绪状态。如果调用select()方法,因为有一个通道变成就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道处于就绪状态。
selectedKeys()
一旦调用了select()方法,它就会返回一个数值,表示一个或多个通道已经就绪,然后你就可以通过调用selector.selectedKeys()方法返回的SelectionKey集合来获得就绪的Channel。请看演示方法:
Set<SelectionKey> selectedKeys = selector.selectedKeys();
当你通过Selector注册一个Channel时,channel.register()方法会返回一个SelectionKey对象,这个对象就代表了你注册的Channel。这些对象可以通过selectedKeys()方法获得。你可以通过迭代这些selected key来获得就绪的Channel,下面是演示代码:
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while(keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if(key.isAcceptable()) {
// a connection was accepted by a ServerSocketChannel.
} else if (key.isConnectable()) {
// a connection was established with a remote server.
} else if (key.isReadable()) {
// a channel is ready for reading
} else if (key.isWritable()) {
// a channel is ready for writing
}
keyIterator.remove();
}
这个循环遍历selected key的集合中的每个key,并对每个key做测试来判断哪个Channel已经就绪。
请注意循环中最后的keyIterator.remove()方法。Selector对象并不会从自己的selected key集合中自动移除SelectionKey实例。我们需要在处理完一个Channel的时候自己去移除。当下一次Channel就绪的时候,Selector会再次把它添加到selected key集合中。
SelectionKey.channel()方法返回的Channel需要转换成你具体要处理的类型,比如是ServerSocketChannel或者SocketChannel等等。
一个完整的例子:
public class MultiPortEcho {
private int ports[];
private ByteBuffer echoBuffer = ByteBuffer.allocate(1024);
public MultiPortEcho(int ports[]) throws IOException {
this.ports = ports;
go();
}
private void go() throws IOException {
// 1. 创建一个selector,select是NIO中的核心对象
// 它用来监听各种感兴趣的IO事件
Selector selector = Selector.open();
// 为每个端口打开一个监听, 并把这些监听注册到selector中
for (int i = 0; i < ports.length; ++i) {
//2. 打开一个ServerSocketChannel
//其实我们没监听一个端口就需要一个channel
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);//设置为非阻塞
ServerSocket ss = ssc.socket();
InetSocketAddress address = new InetSocketAddress(ports[i]);
ss.bind(address);//监听一个端口
//3. 注册到selector
//register的第一个参数永远都是selector
//第二个参数是我们要监听的事件
//OP_ACCEPT是新建立连接的事件
//也是适用于ServerSocketChannel的唯一事件类型
SelectionKey key = ssc.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("Going to listen on " + ports[i]);
}
//4. 开始循环,我们已经注册了一些IO兴趣事件
while (true) {
//这个方法会阻塞,直到至少有一个已注册的事件发生。当一个或者更多的事件发生时
// select() 方法将返回所发生的事件的数量。
int num = selector.select();
//返回发生了事件的 SelectionKey 对象的一个 集合
Set selectedKeys = selector.selectedKeys();
//我们通过迭代 SelectionKeys 并依次处理每个 SelectionKey 来处理事件
//对于每一个 SelectionKey,您必须确定发生的是什么 I/O 事件,以及这个事件影响哪些 I/O 对象。
Iterator it = selectedKeys.iterator();
while (it.hasNext()) {
SelectionKey key = (SelectionKey) it.next();
//5. 监听新连接。程序执行到这里,我们仅注册了 ServerSocketChannel
//并且仅注册它们“接收”事件。为确认这一点
//我们对 SelectionKey 调用 readyOps() 方法,并检查发生了什么类型的事件
if ((key.readyOps() & SelectionKey.OP_ACCEPT) == SelectionKey.OP_ACCEPT) {
//6. 接收了一个新连接。因为我们知道这个服务器套接字上有一个传入连接在等待
//所以可以安全地接受它;也就是说,不用担心 accept() 操作会阻塞
ServerSocketChannel ssc = (ServerSocketChannel) key.channel();
SocketChannel sc = ssc.accept();
sc.configureBlocking(false);
// 7. 讲新连接注册到selector。将新连接的 SocketChannel 配置为非阻塞的
//而且由于接受这个连接的目的是为了读取来自套接字的数据,所以我们还必须将 SocketChannel 注册到 Selector上
SelectionKey newKey = sc.register(selector,SelectionKey.OP_READ);
it.remove();
System.out.println("Got connection from " + sc);
} else if ((key.readyOps() & SelectionKey.OP_READ) == SelectionKey.OP_READ) {
// Read the data
SocketChannel sc = (SocketChannel) key.channel();
// Echo data
int bytesEchoed = 0;
while (true) {
echoBuffer.clear();
int r = sc.read(echoBuffer);
if (r <= 0) {
break;
}
echoBuffer.flip();
sc.write(echoBuffer);
bytesEchoed += r;
}
System.out.println("Echoed " + bytesEchoed + " from " + sc);
it.remove();
}
}
// System.out.println( "going to clear" );
// selectedKeys.clear();
// System.out.println( "cleared" );
}
}
static public void main(String args2[]) throws Exception {
String args[]={"9001","9002","9003"};
if (args.length <= 0) {
System.err.println("Usage: java MultiPortEcho port [port port ...]");
System.exit(1);
}
int ports[] = new int[args.length];
for (int i = 0; i < args.length; ++i) {
ports[i] = Integer.parseInt(args[i]);
}
new MultiPortEcho(ports);
}
}
一个完整的业务可能会被TCP拆分成多个包进行发送,也有可能把多个小的包封装成一个大的数据包发送,这个就是TCP的拆包和封包问题。
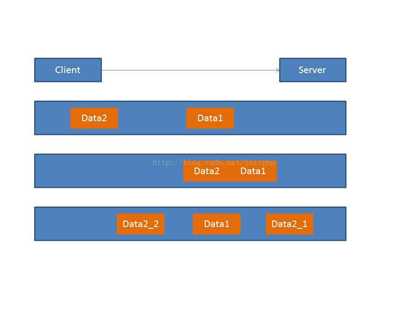
1. 第一种情况,Data1和Data2都分开发送到了Server端,没有产生粘包和拆包的情况。
2. 第二种情况,Data1和Data2数据粘在了一起,打成了一个大的包发送到Server端,这个情况就是粘包。
3. 第三种情况,Data2被分离成Data2_1和Data2_2,并且Data2_1在Data1之前到达了服务端,这种情况就产生了拆包。
由于网络的复杂性,可能数据会被分离成N多个复杂的拆包/粘包的情况,所以在做TCP服务器的时候就需要首先解决拆包/粘包的问题。
1. 应用程序写入数据的字节大小大于套接字发送缓冲区的大小
2. 进行MSS大小的TCP分段。MSS是最大报文段长度的缩写。MSS是TCP报文段中的数据字段的最大长度。数据字段加上TCP首部才等于整个的TCP报文段。所以MSS并不是TCP报文段的最大长度,而是:MSS=TCP报文段长度-TCP首部长度
3. 以太网的payload大于MTU进行IP分片。MTU指:一种通信协议的某一层上面所能通过的最大数据包大小。如果IP层有一个数据包要传,而且数据的长度比链路层的MTU大,那么IP层就会进行分片,把数据包分成若干片,让每一片都不超过MTU。注意,IP分片可以发生在原始发送端主机上,也可以发生在中间路由器上。
1. 消息定长。例如100字节。
2. 在包尾部增加回车或者空格符等特殊字符进行分割,典型的如FTP协议
3. 将消息分为消息头和消息尾。
4. 其它复杂的协议,如RTMP协议等。
Netty是由JBOSS提供的一个java开源框架。Netty提供异步的、事件驱动的网络应用程序框架和工具,用以快速开发高性能、高可靠性的网络服务器和客户端程序。
也就是说,Netty 是一个基于NIO的客户、服务器端编程框架,使用Netty 可以确保你快速和简单的开发出一个网络应用,例如实现了某种协议的客户,服务端应用。Netty相当简化和流线化了网络应用的编程开发过程,例如,TCP和UDP的socket服务开发。
“快速”和“简单”并不用产生维护性或性能上的问题。Netty 是一个吸收了多种协议的实现经验,这些协议包括FTP,SMTP,HTTP,各种二进制,文本协议,并经过相当精心设计的项目,最终,Netty 成功的找到了一种方式,在保证易于开发的同时还保证了其应用的性能,稳定性和伸缩性。
为了更好的理解和进一步深入Netty,我们先总体认识一下Netty用到的组件及它们在整个Netty架构中是怎么协调工作的。Netty的10个核心类:
· Bootstrap or ServerBootstrap
· EventLoop
· EventLoopGroup
· ChannelPipeline
· Channel
· Future or ChannelFuture
· ChannelInitializer
· ChannelHandler
一个Netty程序开始于Bootstrap类,Bootstrap类是Netty提供的一个可以通过简单配置来设置或"引导"程序的一个很重要的类。Netty中设计了Handlers来处理特定的"event"和设置Netty中的事件,从而来处理多个协议和数据。事件可以描述成一个非常通用的方法,因为你可以自定义一个handler,用来将Object转成byte[]或将byte[]转成Object;也可以定义个handler处理抛出的异常。
你会经常编写一个实现ChannelInboundHandler的类,ChannelInboundHandler是用来接收消息,当有消息过来时,你可以决定如何处理。当程序需要返回消息时可以在ChannelInboundHandler里write/flush数据。可以认为应用程序的业务逻辑都是在ChannelInboundHandler中来处理的,业务罗的生命周期在ChannelInboundHandler中。
Netty连接客户端端或绑定服务器需要知道如何发送或接收消息,这是通过不同类型的handlers来做的,多个Handlers是怎么配置的?Netty提供了ChannelInitializer类用来配置Handlers。ChannelInitializer是通过ChannelPipeline来添加ChannelHandler的,如发送和接收消息,这些Handlers将确定发的是什么消息。ChannelInitializer自身也是一个ChannelHandler,在添加完其他的handlers之后会自动从ChannelPipeline中删除自己。
所有的Netty程序都是基于ChannelPipeline。ChannelPipeline和EventLoop和EventLoopGroup密切相关,因为它们三个都和事件处理相关,所以这就是为什么它们处理IO的工作由EventLoop管理的原因。
Netty中所有的IO操作都是异步执行的,例如你连接一个主机默认是异步完成的;写入/发送消息也是同样是异步。也就是说操作不会直接执行,而是会等一会执行,因为你不知道返回的操作结果是成功还是失败,但是需要有检查是否成功的方法或者是注册监听来通知;Netty使用Futures和ChannelFutures来达到这种目的。Future注册一个监听,当操作成功或失败时会通知。ChannelFuture封装的是一个操作的相关信息,操作被执行时会立刻返回ChannelFuture。
下图显示一个EventLoopGroup和一个Channel关联一个单一的EventLoop,Netty中的EventLoopGroup包含一个或多个EventLoop,而EventLoop就是一个Channel执行实际工作的线程。EventLoop总是绑定一个单一的线程,在其生命周期内不会改变。
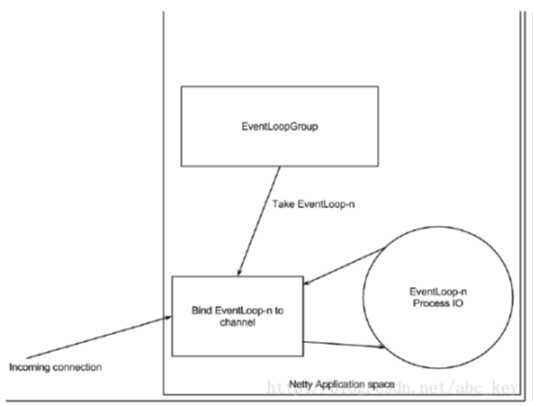
当注册一个Channel后,Netty将这个Channel绑定到一个EventLoop,在Channel的生命周期内总是被绑定到一个EventLoop。在Netty IO操作中,你的程序不需要同步,因为一个指定通道的所有IO始终由同一个线程来执行。
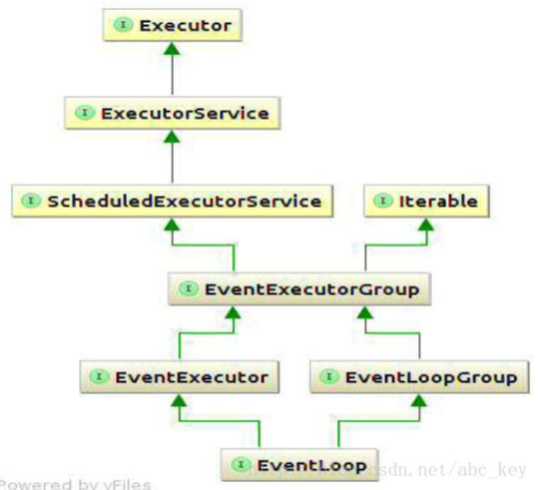
EventLoop和EventLoopGroup的关联不是直观的,因为我们说过EventLoopGroup包含一个或多个EventLoop,但是上面的图显示EventLoop是一个EventLoopGroup,这意味着你可以只使用一个特定的EventLoop。
“引导”是Netty中配置程序的过程,当你需要连接客户端或服务器绑定指定端口时需要使用bootstrap。如前面所述,“引导”有两种类型,一种是用于客户端的Bootstrap(也适用于DatagramChannel),一种是用于服务端的ServerBootstrap。
两种bootstraps之间有一些相似之处,其实他们有很多相似之处,也有一些不同。Bootstrap和ServerBootstrap之间的差异:
· Bootstrap用来连接远程主机,有1个EventLoopGroup
· ServerBootstrap用来绑定本地端口,有2个EventLoopGroup
第一个差异
“ServerBootstrap”监听在服务器监听一个端口轮询客户端的“Bootstrap”或DatagramChannel是否连接服务器。通常需要调用“Bootstrap”类的connect()方法,但是也可以先调用bind()再调用connect()进行连接,之后使用的Channel包含在bind()返回的ChannelFuture中。
第二个差异
客户端bootstraps/applications使用一个单例EventLoopGroup,而ServerBootstrap使用2个EventLoopGroup(实际上使用的是相同的实例),它可能不是显而易见的,但是它是个好的方案。一个ServerBootstrap可以认为有2个channels组,第一组包含一个单例ServerChannel,代表持有一个绑定了本地端口的socket;第二组包含所有的Channel,代表服务器已接受了的连接。例如下图这个情况:
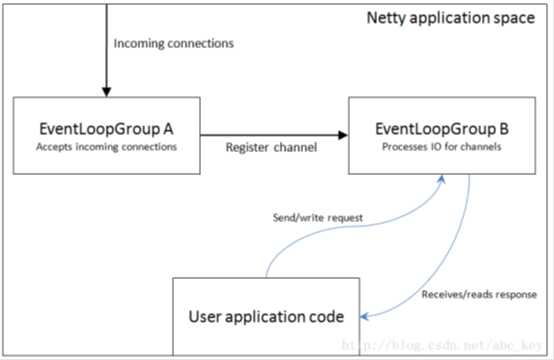
上图中,EventLoopGroup A唯一的目的就是接受连接然后交给EventLoopGroup B。Netty可以使用两个不同的Group,因为服务器程序需要接受很多客户端连接的情况下,一个EventLoopGroup将是程序性能的瓶颈,因为事件循环忙于处理连接请求,没有多余的资源和空闲来处理业务逻辑,最后的结果会是很多连接请求超时。若有两EventLoops, 即使在高负载下,所有的连接也都会被接受,因为EventLoops接受连接不会和哪些已经连接了的处理共享资源。
EventLoopGroup和EventLoop是什么关系?EventLoopGroup可以包含很多个EventLoop,每个Channel绑定一个EventLoop不会被改变,因为EventLoopGroup包含少量的EventLoop的Channels,很多Channel会共享同一个EventLoop。这意味着在一个Channel保持EventLoop繁忙会禁止其他Channel绑定到相同的EventLoop。我们可以理解为EventLoop是一个事件循环线程,而EventLoopGroup是一个事件循环集合。
要明白Netty程序wirte或read时发生了什么,首先要对Handler是什么有
一定的了解。Handlers自身依赖于ChannelPipeline来决定它们执行的顺序,因此不可能通过ChannelPipeline定义处理程序的某些方面,反过来不可能定义也不可能通过ChannelHandler定义ChannelPipeline的某些方面。没必要说我们必须定义一个自己和其他的规定。本节将介绍ChannelHandler和ChannelPipeline在某种程度上细微的依赖。
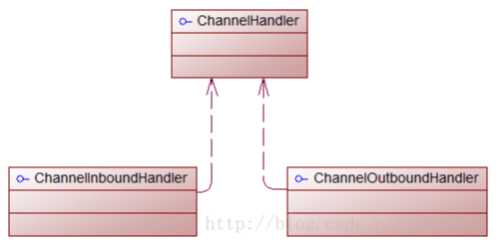
在很多地方,Netty的ChannelHandler是你的应用程序中处理最多的。即使你没有意思到这一点,若果你使用Netty应用将至少有一个ChannelHandler参与,换句话说,ChannelHandler对很多事情是关键的。我们可以理解为ChannelHandler是一段执行业务逻辑处理数据的代码,它们来来往往的通过ChannelPipeline。实际上,ChannelHandler是定义一个handler的父接口,ChannelInboundHandler和ChannelOutboundHandler都实现ChannelHandler接口,如下图:
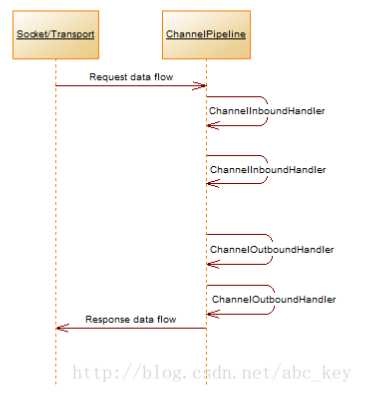
为了使数据从一端到达另一端,一个或多个ChannelHandler将以某种方式操作数据。这些ChannelHandler会在程序的“引导”阶段被添加ChannelPipeline中,并且被添加的顺序将决定处理数据的顺序。ChannelPipeline的作用我们可以理解为用来管理ChannelHandler的一个容器,每个ChannelHandler处理各自的数据(例如入站数据只能由ChannelInboundHandler处理),处理完成后将转换的数据放到ChannelPipeline中交给下一个ChannelHandler继续处理,直到最后一个ChannelHandler处理完成。
如前面所说,有很多不同类型的handlers,每个handler的依赖于它们的基类。Netty提供了一系列的“Adapter”类,这让事情变的很简单。每个handler负责转发时间到ChannelPipeline的下一个handler。在*Adapter类(和子类)中是自动完成的,因此我们只需要在感兴趣的*Adapter中重写方法。这些功能可以帮助我们非常简单的编码/解码消息。有几个适配器(adapter)允许自定义ChannelHandler,一般自定义ChannelHandler需要继承编码/解码适配器类中的一个。Netty有一下适配器: ?
ChannelHandlerAdapter ?
ChannelInboundHandlerAdapter ?
ChannelOutboundHandlerAdapter
三个ChannelHandler涨,我们重点看看ecoders,decoders和SimpleChannelInboundHandler<I>,SimpleChannelInboundHandler<I>继承ChannelInboundHandlerAdapter。
因为我们在网络传输时只能传输字节流,因此,才发送数据之前,我们必须把我们的message型转换为bytes,与之对应,我们在接收数据后,必须把接收到的bytes再转换成message。我们把bytes to message这个过程称作Decode(解码成我们可以理解的),把message to bytes这个过程成为Encode。
Netty中提供了很多现成的编码/解码器,我们一般从他们的名字中便可知道他们的用途,如ByteToMessageDecoder、MessageToByteEncoder,如专门用来处理Google Protobuf协议的ProtobufEncoder、 ProtobufDecoder。
我们前面说过,具体是哪种Handler就要看它们继承的是InboundAdapter还是OutboundAdapter,对于Decoders,很容易便可以知道它是继承自ChannelInboundHandlerAdapter或 ChannelInboundHandler,因为解码的意思是把ChannelPipeline传入的bytes解码成我们可以理解的message(即Java Object),而ChannelInboundHandler正是处理Inbound Event,而Inbound Event中传入的正是字节流。Decoder会覆盖其中的“ChannelRead()”方法,在这个方法中来调用具体的decode方法解码传递过来的字节流,然后通过调用ChannelHandlerContext.fireChannelRead(decodedMessage)方法把编码好的Message传递给下一个Handler。与之类似,Encoder就不必多少了。
Handler,为了支持各种协议和处理数据的方式,便诞生了Handler组件。Handler主要用来处理各种事件,这里的事件很广泛,比如可以是连接、数据接收、异常、数据转换等。
ChannelInboundHandler,一个最常用的Handler。这个Handler的作用就是处理接收到数据时的事件,也就是说,我们的业务逻辑一般就是写在这个Handler里面的,ChannelInboundHandler就是用来处理我们的核心业务逻辑。
ChannelInitializer,当一个链接建立时,我们需要知道怎么来接收或者发送数据,当然,我们有各种各样的Handler实现来处理它,那么ChannelInitializer便是用来配置这些Handler,它会提供一个ChannelPipeline,并把Handler加入到ChannelPipeline。
ChannelPipeline,一个Netty应用基于ChannelPipeline机制,这种机制需要依赖于EventLoop和EventLoopGroup,因为它们三个都和事件或者事件处理相关。
EventLoops的目的是为Channel处理IO操作,一个EventLoop可以为多个Channel服务。
EventLoopGroup会包含多个EventLoop。
Channel代表了一个Socket链接,或者其它和IO操作相关的组件,它和EventLoop一起用来参与IO处理。
Future,在Netty中所有的IO操作都是异步的,因此,你不能立刻得知消息是否被正确处理,但是我们可以过一会等它执行完成或者直接注册一个监听,具体的实现就是通过Future和ChannelFutures,他们可以注册一个监听,当操作执行成功或失败时监听会自动触发。总之,所有的操作都会返回一个ChannelFuture。
也许最常见的是应用程序处理接收到消息后进行解码,然后供相关业务逻辑模块使用。所以应用程序只需要扩展SimpleChannelInboundHandler<I>,也就是我们自定义一个继承SimpleChannelInboundHandler<I>的handler类,其中<I>是handler可以处理的消息类型。通过重写父类的方法可以获得一个ChannelHandlerContext的引用,它们接受一个ChannelHandlerContext的参数,你可以在class中当一个属性存储。
处理程序关注的主要方法是“channelRead0(ChannelHandlerContext ctx, I msg)”,每当Netty调用这个方法,对象“I”是消息,这里使用了Java的泛型设计,程序就能处理I。如何处理消息完全取决于程序的需要。在处理消息时有一点需要注意的,在Netty中事件处理IO一般有很多线程,程序中尽量不要阻塞IO线程,因为阻塞会降低程序的性能。
必须不阻塞IO线程意味着在ChannelHandler中使用阻塞操作会有问题。幸运的是Netty提供了解决方案,我们可以在添加ChannelHandler到ChannelPipeline中时指定一个EventExecutorGroup,EventExecutorGroup会获得一个EventExecutor,EventExecutor将执行ChannelHandler的所有方法。EventExecutor将使用不同的线程来执行和释放EventLoop。
Netty自带了一些传输协议的实现,虽然没有支持所有的传输协议,但是其自带的已足够我们来使用。Netty应用程序的传输协议依赖于底层协议,本节我们将学习Netty中的传输协议。
Netty中的传输方式有如下几种:
? NIO,io.netty.channel.socket.nio,基于java.nio.channels的工具包,使用选择器作为基础的方法。
? OIO,io.netty.channel.socket.oio,基于java.net的工具包,使用阻塞流。
? Local,io.netty.channel.local,用来在虚拟机之间本地通信。
Embedded,io.netty.channel.embedded,嵌入传输,它允许在没有真正网络的运输中使用ChannelHandler,可以非常有用的来测试ChannelHandler的实现。
NIO传输是目前最常用的方式,它通过使用选择器提供了完全异步的方式操作所有的I/O,NIO从Java 1.4才被提供。NIO中,我们可以注册一个通道或获得某个通道的改变的状态,通道状态有下面几种改变:
? 一个新的Channel被接受并已准备好
? Channel连接完成
? Channel中有数据并已准备好读取
? Channel发送数据出去
处理完改变的状态后需重新设置他们的状态,用一个线程来检查是否有已准备好的Channel,如果有则执行相关事件。在这里可能只同时一个注册的事件而忽略其他的。选择器所支持的操作在SelectionKey中定义,具体如下:
OP_ACCEPT,有新连接时得到通知
? OP_CONNECT,连接完成后得到通知
? OP_READ,准备好读取数据时得到通知
? OP_WRITE,写入数据到通道时得到通知
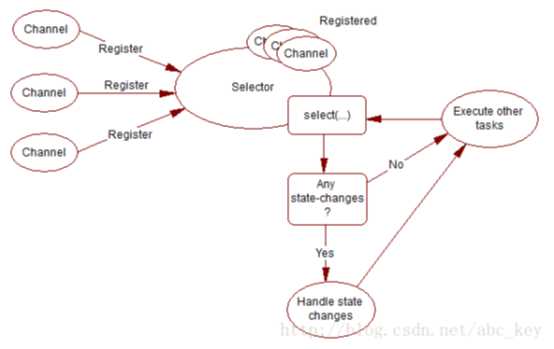
Netty中的NIO传输就是基于这样的模型来接收和发送数据,通过封装将自己的接口提供给用户使用,这完全隐藏了内部实现。如前面所说,Netty隐藏内部的实现细节,将抽象出来的API暴露出来供使用,下面是处理流程图:
Netty包含了本地传输,这个传输实现使用相同的API用于虚拟机之间的通信,传输是完全异步的。每个Channel使用唯一的SocketAddress,客户端通过使用SocketAddress进行连接,在服务器会被注册为长期运行,一旦通道关闭,它会自动注销,客户端无法再使用它。
连接到本地传输服务器的行为与其他的传输实现几乎是相同的,需要注意的一个重点是只能在本地的服务器和客户端上使用它们。Local未绑定任何Socket,值提供JVM进程之间的通信。
ByteBuf
ByteBufHolder
ByteBufAllocator
使用这些接口分配缓冲和执行操作
Netty的缓冲API有两个接口: ?
ByteBuf ?
ByteBufHolder
Netty使用reference-counting(引用计数)的时候知道安全释放Buf和其他资源,虽然知道Netty有效的使用引用计数,这都是自动完成的。这允许Netty使用池和其他技巧来加快速
度和保持内存利用率在正常水平,你不需要做任何事情来实现这一点,但是在开发Netty应用程序时,你应该处理数据尽快释放池资源。
Netty缓冲API提供了几个优势:
可以自定义缓冲类型
通过一个内置的复合缓冲类型实现零拷贝
扩展性好,比如StringBuffer
不需要调用flip()来切换读/写模式
读取和写入索引分开
方法链
引用计数
Pooling(池)
当需要与远程进行交互时,需要以字节码发送/接收数据。由于各种原因,一个高效、方便、易用的数据接口是必须的,而Netty的ByteBuf满足这些需求,ByteBuf是一个很好的经过优化的数据容器,我们可以将字节数据有效的添加到ByteBuf中或从ByteBuf中获取数据。ByteBuf有2部分:一个用于读,一个用于写。我们可以按顺序的读取数据,并且可以跳到开始重新读一遍。所有的数据操作,我们只需要做的是调整读取数据索引和再次开始读操作。
最常用的类型是ByteBuf将数据存储在JVM的堆空间,这是通过将数据存储在数组的实现。堆缓冲区可以快速分配,当不使用时也可以快速释放。它还提供了直接访问数组的方法,通过ByteBuf.array()来获取byte[]数据。
访问非堆缓冲区ByteBuf的数组会导致UnsupportedOperationException,可以使用ByteBuf.hasArray()来检查是否支持访问数组。
直接缓冲区,在堆之外直接分配内存。直接缓冲区不会占用堆空间容量,使用时应该考虑到应用程序要使用的最大内存容量以及如何限制它。直接缓冲区在使用Socket传递数据时性能很好,因为若使用间接缓冲区,JVM会先将数据复制到直接缓冲区再进行传递;但是直接缓冲区的缺点是在分配内存空间和释放内存时比堆缓冲区更复杂,而Netty使用内存池来解决这样的问题,这也是Netty使用内存池的原因之一。直接缓冲区不支持数组访问数据,但是我们可以间接的访问数据数组,如下面代码:
1. ByteBuf directBuf = Unpooled.directBuffer(16);
2. if(!directBuf.hasArray()){
3. int len = directBuf.readableBytes();
4. byte[] arr = new byte[len];
5. directBuf.getBytes(0, arr);
6. }
访问直接缓冲区的数据数组需要更多的编码和更复杂的操作,建议若需要在数组访问数据使用堆缓冲区会更好。
复合缓冲区,我们可以创建多个不同的ByteBuf,然后提供一个这些ByteBuf组合的视图。复合缓冲区就像一个列表,我们可以动态的添加和删除其中的ByteBuf,JDK的
ByteBuffer没有这样的功能。Netty提供了CompositeByteBuf类来处理复合缓冲区,CompositeByteBuf只是一个视图,CompositeByteBuf.hasArray()总是返回false,因为它可能包含一些直接或间接的不同类型的ByteBuf。
例如,一条消息由header和body两部分组成,将header和body组装成一条消息发送出去,可能body相同,只是header不同,使用CompositeByteBuf就不用每次都重新分配一个新的缓冲区。下图显示CompositeByteBuf组成header和body:

一个Channel会对应一个EventLoop,而一个EventLoop会对应着一个线程,也就是说,仅有一个线程在负责一个Channel的IO操作。所以不需要想如果同步代码。
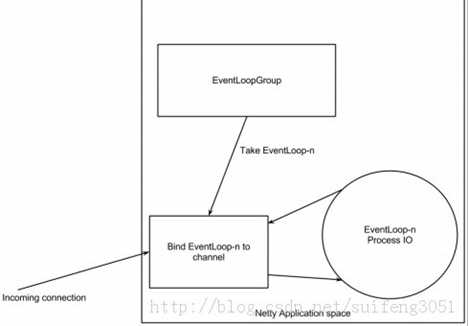
如图所示:当一个连接到达,Netty会注册一个channel,然后EventLoopGroup会分配一个EventLoop绑定到这个channel,在这个channel的整个生命周期过程中,都会由绑定的这个EventLoop来为它服务,而这个EventLoop就是一个线程。
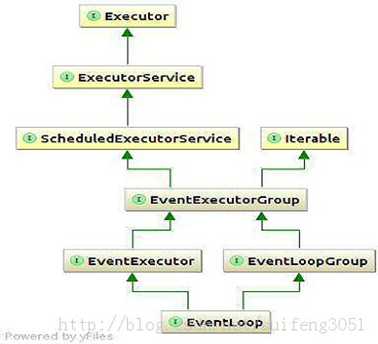
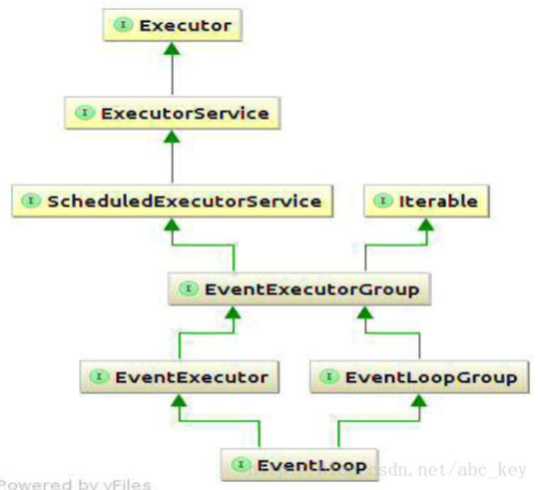
说到这里,那么EventLoops和EventLoopGroup关系是如何的呢?我们前面说过一个EventLoopGroup包含多个Eventloop,但是我们看一下这幅图,这幅图是一个继承树,从这幅图中我们可以看出,EventLoop其实继承自EventloopGroup,也就是说,在某些情况下,我们可以把一个EventLoopGroup当做一个EventLoop来用。
我们利用BootsStrapping来配置netty 应用,它有两种类型,一种用于Client端:BootsStrap,另一种用于Server端:ServerBootstrap,要想区别如何使用它们,你仅需要记住一个用在Client端,一个用在Server端。下面我们来详细介绍一下这两种类型的区别:
1.第一个最明显的区别是,ServerBootstrap用于Server端,通过调用bind()方法来绑定到一个端口监听连接;Bootstrap用于Client端,需要调用connect()方法来连接服务器端,但我们也可以通过调用bind()方法返回的ChannelFuture中获取Channel去connect服务器端。
2.客户端的Bootstrap一般用一个EventLoopGroup,而服务器端的ServerBootstrap会用到两个(这两个也可以是同一个实例)。为何服务器端要用到两个EventLoopGroup呢?这么设计有明显的好处,如果一个ServerBootstrap有两个EventLoopGroup,那么就可以把第一个EventLoopGroup用来专门负责绑定到端口监听连接事件,而把第二个EventLoopGroup用来处理每个接收到的连接,下面我们用一幅图来展现一下这种模式:
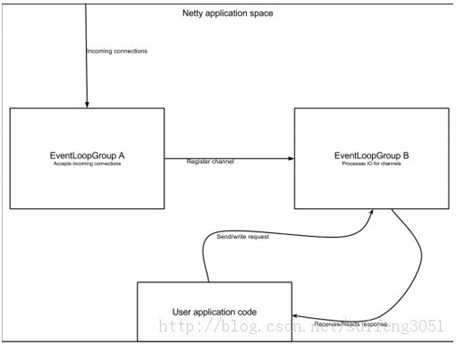
如果仅由一个EventLoopGroup处理所有请求和连接的话,在并发量很大的情况下,这个EventLoopGroup有可能会忙于处理已经接收到的连接而不能及时处理新的连接请求,用两个的话,会有专门的线程来处理连接请求,不会导致请求超时的情况,大大提高了并发处理能力。
我们的应用程序中用到的最多的应该就是ChannelHandler,我们可以这么想象,数据在一个ChannelPipeline中流动,而ChannelHandler便是其中的一个个的小阀门,这些数据都会经过每一个ChannelHandler并且被它处理。这里有一个公共接口ChannelHandler:
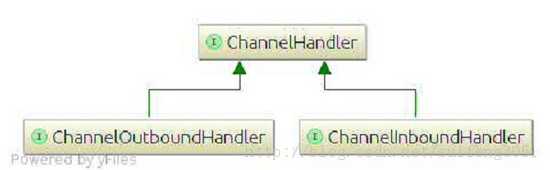
从上图中我们可以看到,ChannelHandler有两个子类ChannelInboundHandler和ChannelOutboundHandler,这两个类对应了两个数据流向,如果数据是从外部流入我们的应用程序,我们就看做是inbound,相反便是outbound。其实ChannelHandler和Servlet有些类似,一个ChannelHandler处理完接收到的数据会传给下一个Handler,或者什么不处理,直接传递给下一个。下面我们看一下ChannelPipeline是如何安排ChannelHandler的:
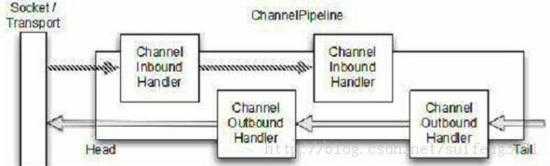
从上图中我们可以看到,一个ChannelPipeline可以把两种Handler(ChannelInboundHandler和ChannelOutboundHandler)混合在一起,当一个数据流进入ChannelPipeline时,它会从ChannelPipeline头部开始传给第一个ChannelInboundHandler,当第一个处理完后再传给下一个,一直传递到管道的尾部。与之相对应的是,当数据被写出时,它会从管道的尾部开始,先经过管道尾部的“最后”一个ChannelOutboundHandler,当它处理完成后会传递给前一个ChannelOutboundHandler。
当一个ChannelHandler被加入到ChannelPipeline中时,它便会获得一个ChannelHandlerContext的引用,而ChannelHandlerContext可以用来读写Netty中的数据流。因此,现在可以有两种方式来发送数据,一种是把数据直接写入Channel,一种是把数据写入ChannelHandlerContext,它们的区别是写入Channel的话,数据流会从Channel的头开始传递,而如果写入ChannelHandlerContext的话,数据流会流入管道中的下一个Handler。
Netty中会有很多Handler,具体是哪种Handler还要看它们继承的是InboundAdapter还是OutboundAdapter。当然,Netty中还提供了一些列的Adapter来帮助我们简化开发,我们知道在Channelpipeline中每一个Handler都负责把Event传递给下一个Handler,如果有了这些辅助Adapter,这些额外的工作都可自动完成,我们只需覆盖实现我们真正关心的部分即可。
Domain Logic
其实我们最最关心的事情就是如何处理接收到的解码后的数据,我们真正的业务逻辑便是处理接收到的数据。Netty提供了一个最常用的基类SimpleChannelInboundHandler<T>,其中T就是这个Handler处理的数据的类型(上一个Handler已经替我们解码好了),消息到达这个Handler时,Netty会自动调用这个Handler中的channelRead0(ChannelHandlerContext,T)方法,T是传递过来的数据对象,在这个方法中我们便可以任意写我们的业务逻辑了。
EventLoopGroup类的创建
EventLoopGroup bossGroup= new NioEventLoopGroup();
主要方法:
ServerBootstrap类的创建
ServerBootstrap b=new ServerBootstrap();
主要方法:
group()
标签:domain pos 架构 buffers else 基本 数据包 何事 可靠性
原文地址:http://www.cnblogs.com/maofa/p/6407119.html