标签:ffffff row 配置 mat print white data zip mod
| opencc-1.0.1-win64.7z |
space = b‘ ‘ #原来是space = ‘ ‘- ...
s=space.join(text)
s=s.decode(‘utf8‘) + "\n"
output.write(s)
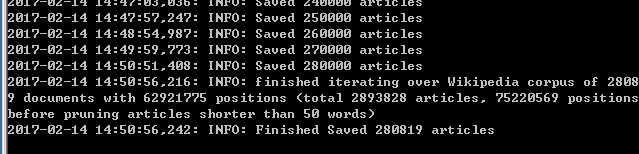
#!/usr/bin/env python# -*- coding: utf-8 -*-# 修改后的代码如下:import loggingimport os.pathimport sysfrom gensim.corpora import WikiCorpusif __name__ == ‘__main__‘:program = os.path.basename(sys.argv[0])logger = logging.getLogger(program)logging.basicConfig(format=‘%(asctime)s: %(levelname)s: %(message)s‘)logging.root.setLevel(level=logging.INFO)logger.info("running %s" % ‘ ‘.join(sys.argv))# check and process input argumentsif len(sys.argv) < 3:print (globals()[‘__doc__‘] % locals())sys.exit(1)inp, outp = sys.argv[1:3]space = b‘ ‘i = 0output = open(outp, ‘w‘,encoding=‘utf-8‘)wiki = WikiCorpus(inp, lemmatize=False, dictionary={})for text in wiki.get_texts():s=space.join(text)s=s.decode(‘utf8‘) + "\n"output.write(s)i = i + 1if (i % 10000 == 0):logger.info("Saved " + str(i) + " articles")output.close()logger.info("Finished Saved " + str(i) + " articles")
import codecs,sysimport openccf=codecs.open(‘zh.wiki.txt‘,‘r‘,encoding="utf8")line=f.readline()print(line)
import jiebaimport jieba.analyseimport jieba.posseg as psegimport codecs,sysdef cut_words(sentence):#print sentencereturn " ".join(jieba.cut(sentence)).encode(‘utf-8‘)f=codecs.open(‘zh.jian.wiki.txt‘,‘r‘,encoding="utf8")target = codecs.open("zh.jian.wiki.seg.txt", ‘w‘,encoding="utf8")print (‘open files‘)line_num=1line = f.readline()while line:print(‘---- processing ‘, line_num, ‘ article----------------‘)line_seg = " ".join(jieba.cut(line))target.writelines(line_seg)line_num = line_num + 1line = f.readline()f.close()target.close()exit()while line:curr = []for oneline in line:#print(oneline)curr.append(oneline)after_cut = map(cut_words, curr)target.writelines(after_cut)print (‘saved ‘,line_num,‘ articles‘)exit()line = f.readline1()f.close()target.close()
python train_word2vec_model.py zh.jian.wiki.seg.txt wiki.zh.text.model wiki.zh.text.vector
import loggingimport os.pathimport sysimport multiprocessingfrom gensim.corpora import WikiCorpusfrom gensim.models import Word2Vecfrom gensim.models.word2vec import LineSentenceif __name__ == ‘__main__‘:program = os.path.basename(sys.argv[0])logger = logging.getLogger(program)logging.basicConfig(format=‘%(asctime)s: %(levelname)s: %(message)s‘)logging.root.setLevel(level=logging.INFO)logger.info("running %s" % ‘ ‘.join(sys.argv))# check and process input argumentsif len(sys.argv) < 4:print (globals()[‘__doc__‘] % locals())sys.exit(1)inp, outp1, outp2 = sys.argv[1:4]model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count())model.save(outp1)model.save_word2vec_format(outp2, binary=False)

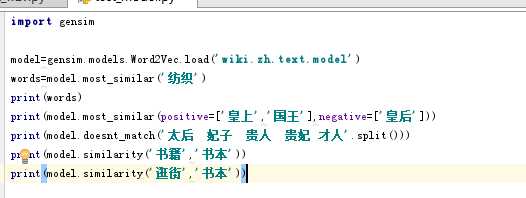


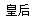 难道这个模型宫斗剧看多了,发现皇上和太后是一家人,低阶的后宫女人是一团,只有皇后是个另类?
难道这个模型宫斗剧看多了,发现皇上和太后是一家人,低阶的后宫女人是一团,只有皇后是个另类?wiki中文语料+word2vec (python3.5 windows win7)
标签:ffffff row 配置 mat print white data zip mod
原文地址:http://www.cnblogs.com/combfish/p/6413553.html