标签:stream puts 切换 运行环境 分享 字符 null text 最好
在计算机中存储信息的最小单元是1个字节(8bit),所以能表示的字符范围是0-255个。人类要表达的字符太多,无法用1个字节完全表示。要解决这个问题需要使用新的数据结构char,从char到byte必须编码。
ASCII码:共128个,用一个字节的低7位表示,0-31控制字符,32-126打印字符。
ISO-8859-1:拓展自ASCII码,覆盖大多数西欧语言字符,单字节编码,共能表示256个字节。
GB2312:双字节编码,包含6763个汉字。
GBK:拓展自GB2312,和GB2312兼容,能表示21003个汉字。
GB18030:可能单字节、双字节或四字节,应用不广泛。
UTF-16:具体定义了Unicode字符在计算机中的存取方法。定长,使用两个字节表示任何字符。Java以UTF-16作为内存的字符存储格式。
UTF-8:采用变长技术,每个编码区域有不同的字码长度。中文一般占三个字节。
InputStreamReader类是关联字节到字符的桥梁,负责在I/O过程中处理读取字节到字符的转换,其委托StreamDecoder实现字节到字符的节码实现,解码过程中必须由用户指定Charset编码格式,默认使用本地环境中的默认字符集(中文环境即为GBK)。
OutputStreamWriter负责转换字符到字节,编码格式和默认编码规则与解码一致。
建议不使用操作系统的默认编码,这样会使应用程序的编码格式和运行环境绑定起来,在跨环境会出现乱码问题。
@Test public void testCopyFile(){ try(BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("D:\\Test.txt"),"UTF-8")); BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("D:\\Test_.txt"),"UTF-8")); )
{ String str = null; int i = 0; while((str = reader.readLine()) != null){ if (i != 0) writer.write("\r\n"); i++; writer.write(str); } }catch (IOException e) { e.printStackTrace(); } }
String str = "中文字符串"; String newStr = new String(str.getBytes(),"UTF-8");
String string = "中文字符串"; Charset charset = Charset.forName("UTF-8"); ByteBuffer byteBuffer = charset.encode(string); CharBuffer charBuffer = charset.decode(byteBuffer);
补充:
UTF-16编码效率较高,从字符到字节的相互转换更加简单,适合本地磁盘和内存之间使用,可进行字符和字节的快速切换,但是不适合网络之间传输。其采用顺序编码,不能对单个字符的编码进行校验,如果中间的一个字符码值损坏,后面所有码值都受影响,相较而言UTF-8更适合网络传输。
UTF-8编码与GBK和GB2312不同,不用查码表,所以UTF-8的编码效率更高,所以在存储中文字符时采用UTF-8编码比较理想。UTF-8中单个字符损坏不会影响后面的其他字符,编码效率介于GBK和UTF-16之间,是理想的中文编码方式。
1.数据经过网络传输时都是以字节为单位,所有的数据都必须能够被序列化为字节。在Java中数据要被序列化,必须继承Serializable接口。
2.把整型数字1234567当作字符来存储,则采用UTF-8编码将会占用7个字节,采用UTF-16编码则会占用14个字节,但当作int类型的数字只需要4个字节。所以,只看字符本身的长度是没有意义的,即使一样的字符,采用不同的编码最终存储的大小也会不同,所以从字符到字节要看编码类型。
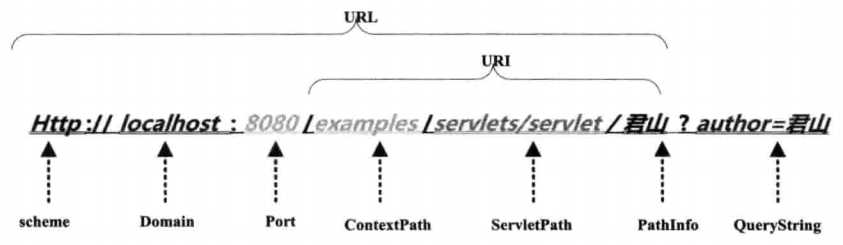
对URL的URI部分进行解码的字符集在<Connector URIEncoding="UTF-8"/>中定义,若没有定义则以默认编码ISO-8859-1解析。有中文URL时最好把URIEncoding设置为UTF-8编码。
对于QueryString的解析:QueryString的解码字符集要么是Header中ContentType定义的Charset,要么默认是ISO-8859-1要使用ContentType中定义的编码,就要设置useBodyEncodingForURI:<Connector URIEncoding="UTF-8" useBodyEncodingForURI="true"/>。这个配置项不是对整个URI都采用BodyEncoding编码,仅仅是对QueryString使用BodyEncoding解码。
客户端发起的HTTP请求除了URL外,还可能会在Header中传递其他参数(如Cookie)。对Header中的项进行解码默认使用ISO-8859-1,且不能设置Header其他的解码格式,若设置的Header中有非ASCII字符,解码中肯定会出现乱码。若一定要传递,则调用Tomcat中的URLEncoder编码,再添加到Header中。
POST表单的参数传递方式是通过HTTP的BODY传递到服务器的,当提交时先根据ContentType中的字符集进行解码,字符集编码可以由request.setCharacterEncoding(charset)来设置。
此外务必注意:对POST表单提交参数的解码是发生在getParameter时,所以在第一次调用request.getParameter方法之前就要先设置request.setCharacterEncoding(charset)方法。
关于上传的文件编码:也是使用ContentType定义的字符集编码,不过上传文件是以字节流的方式传输到服务器的本地临时目录,此过程尚不涉及字符编码,只有当文件内容添加到parameters时才进行编码。
编解码字符集通过response.setCharacterEncoding来设置,通过Header的Content-Type返回客户端。若Header中没有Content-Type,浏览器会根据<meta http-equiv="Content-Type" content="text/html; charset=utf-8">中的charset来解码,若依然没有该属性,浏览器则使用默认编码。
补充:使用JDBC来存取数据时要和数据的内置编码保持一致,可以设置JDBC URL来指定:jdbc:mysql://localhost:3306/db?useUnicode=true&characterEncoding=UTF-8
标签:stream puts 切换 运行环境 分享 字符 null text 最好
原文地址:http://www.cnblogs.com/weilanzz/p/6423586.html