标签:客户 log idt list 表达 over mat miss 输入
Codecademy中Learn SQL, SQL: Table Transformaton和SQL: Analyzing Business Metrics三门课程的笔记,以及补充的附加笔记。
Codecademy的课程以SQLite编写,笔记中改成了MySQL语句。
I. Learn SQL
1. Manipulation - Create, edit, delete data
1.4 Create 创建数据库或数据库中的表
CREATE TABLE celebs
(
id INTEGER,
name TEXT,
age INTEGER
); # 第一列id,数据类型整数;第二列name,数据类型文本;第三列age,数据类型整数
1.5 Insert 向表中插入行
INSERT INTO celebs ( id, name, age)
VALUES ( 1, ‘Alan Mathison Turing‘, 42); # 在celebs表最下方插入数据:id列为1,name列为Alan Mathion Turing,age列为42
1.6 Select 选取数据
SELECT
*
FROM
celebs; # 显示celebs表所有数据
1.7 Update 修改数据
UPDATE celebs
SET
age = 22
WHERE
id = 1; # 将celebs表中id=1的行的age改为22
1.8 Alert 更改表结构或数据类型
ALERT TABLE celebs
ADD COLUMN twitter_handle TEXT; # 在celebs表增加twitter_handle列
ALERT TABLE ‘test‘.‘data‘
CHANGE COLUMN ‘Mobile‘ ‘Mobile‘ BLOB NULL DEFAULT NULL; # 将表test.data的Mobile列的数据类型改为BLOB,该列数据默认为NULL
1.9 DELETE 删除行
DELETE FROM celebs
WHERE
twitter_handle IS NULL; # 删除表celebs中twitter_handle为NULL的行
2. Queries - Retrieve data
2.3 Select Distinct 返回唯一不同的值
SELECT DISTINCT
genre
FROM
movies; # 查询movies表中genre列的所有不重复值
2.4 Where 规定选择的标准
SELECT
*
FROM
movies
WHERE
imdb_rating > 8; # 查询movies表中imdb_rating大于8的行
= equals
!= not equals
> greater than
< less than
>= greater than or equal to
<= less than or equal to
2.5 Like I 在 WHERE 子句中搜索列中的指定模式
SELECT
*
FROM
movies
WHERE
name LIKE ‘ Se_en‘;
2.6 Like II
SELECT
*
FROM
movies
WHERE
name LIKE ‘a%‘;
SELECT
*
FROM
movies
WHERE
name LIKE ‘%man%‘;
NB 通配符
‘_‘ substitutes any individual character
‘%‘ matches zero or more missing characters
‘[charlist]%‘ any individual character in string: WHERE city LIKE ‘[ALN]%‘ 以“A"或”L“或”N“开头的城市
‘[!charlist]%‘ any individual character not in string: WHERE city LIKE ‘[!ALN]%‘ 不以“A"或”L“或”N“开头的城市
2.7 Between 在 WHERE 子句中使用,选取介于两个值之间的数据范围
The BETWEEN operator is used to filter the result set within a certain range. The values can be numbers, text or dates.
SELECT
*
FROM
movies
WHERE
name BETWEEN ‘A‘ AND ‘J‘; # 查询movies中name以A至J开头的所有行
NB: names that begin with letter "A" up to but not including "J".
不同的数据库对 BETWEEN...AND 操作符的处理方式是有差异的,有开区间、闭区间,也有半开半闭区间。
SELECT
*
FROM
movies
WHERE
year BETWEEN 1990 AND 2000; # 查询movies中year在1990至2000年间的行
NB: years between 1990 up to and including 2000
2.8 And 且运算符
AND is an operator that combines two conditions. Both conditions must be true for the row to be included in the result set.
SELECT
*
FROM
movies
WHERE
year BETWEEN 1990 AND 2000
AND genre = ‘comedy‘; # 查询movies中year在1990至2000间,且genre为comedy的行
2.9 Or 或运算符
OR is used to combine more than one condition in WHERE clause. It evaluates each condition separately and if any of the conditions are true than the row is added to the result set. OR is an operator that filters the result set to only include rows where either condition is true.
SELECT
*
FROM
movies
WHERE
genre = ‘comedy‘ OR year < 1980; # 查询movies中genre为comedy,或year小于1980的行
2.10 Order By 对结果集进行排序
SELECT
*
FROM
movies
ORDER BY imdb_rating DESC; # 查询movies中的行,结果以imdb_rating降序排列
DESC sorts the result by a particular column in descending order (high to low or Z - A).
ASC ascending order (low to high or A - Z).
2.11 Limit 规定返回的记录的数目
LIMIT is a clause that lets you specify the maximum number of rows the result set will have.
SELECT
*
FROM
movies
ORDER BY imdb_rating ASC
LIMIT 3; # 查询movies中的行,结果以imdb_rating升序排列,仅返回前3行
MS SQL Server中使用SELECT TOP 3,Oracle中使用WHERE ROWNUM <= 5(?)
3. Aggregate Function
3.2 Count 返回匹配指定条件的行数
COUNT( ) is a function that takes the name of a column as an argument and counts the number of rows where the column is not NULL.
SELECT
COUNT(*)
FROM
fake_apps
WHERE
price = 0; # 返回fake_apps中price=0的行数
3.3 Group By 合计函数
SELECT
price, COUNT(*)
FROM
fake_apps
WHERE
downloads > 2000
GROUP BY price; # 查询fake_apps表中downloads大于2000的行,将结果集根据price分组,返回price和行数
Here, our aggregate function is COUNT( ) and we are passing price as an argument(参数) to GROUP BY. SQL will count the total number of apps for each price in the table.
It is usually helpful to SELECT the column you pass as an argument to GROUP BY. Here we SELECT price and COUNT(*).
3.4 Sum 返回数值列的总数(总额)
SUM is a function that takes the name of a column as an argument and returns the sum of all the values in that column.
SELECT
category, SUM(downloads)
FROM
fake_apps
GROUP BY category;
3.5 Max 返回一列中的最大值(NULL 值不包括在计算中)
MAX( ) is a function that takes the name of a column as an argument and returns the largest value in that column.
SELECT
name, category, MAX(downloads)
FROM
fake_apps
GROUP BY category;
3.6 Min 返回一列中的最小值(NULL 值不包括在计算中)
MIN( ) is a function that takes the name of a column as an argument and returns the smallest value in that column.
SELECT
name, category, MIN(downloads)
FROM
fake_apps
GROUP BY category;
3.7 Average 返回数值列的平均值(NULL 值不包括在计算中)
SELECT
price, AVG(downloads)
FROM
fake_apps
GROUP BY price;
3.8 Round 把数值字段舍入为指定的小数位数
ROUND( ) is a function that takes a column name and an integer as an argument. It rounds the values in the column to the number of decimal places specified by the integer.
SELECT
price, ROUND(AVG(downloads), 2)
FROM
fake_apps
GROUP BY price;
4. Multiple Tables
4.2 Primary Key 主键
A primary key serves as a unique identifier for each row or record in a given table. The primary key is literally an "id" value for a record. We could use this value to connect the table to other tables.
CREATE TABLE artists
(
id INTEGER PRIMARY KET,
name TEXT
);
NB
By specifying that the "id" column is the "PRIMARY KEY", SQL make sure that:
1. None of the values in this column are "NULL";
2. Each value in this column is unique.
A table can not have more than one "PRIMARY KEY" column.
4.3 Foreign Key 外键
SELECT
*
FROM
albums
WHERE
artist_id = 3;
A foreign key is a column that contains the primary key of another table in the database. We use foreign keys and primary keys to connect rows in two different tables. One table‘s foreign key holds the value of another table‘s primary key. Unlike primary keys, foreign keys do not need to be unique and can be NULL. Here, artist_id is a foreign key in the "albums" table.
The relationship between the "artists" table and the "albums" table is the "id" value of the artists.
4.4 Cross Join 用于生成两张表的笛卡尔集
SELECT
albums.name, albums.year, artists.name
FROM
albums,
artists;
One way to query multiple tables is to write a SELECT statement with multiple table names seperated by a comma. This is also known as a "cross join".
When querying more than one table, column names need to be specified by table_name.column_name.
Unfortunately, the result of this cross join is not very useful. It combines every row of the "artists" table with every row of the "albums" table. It would be more useful to only combine the rows where the album was created by the artist.
4.5 Inner Join 内连接:在表中存在至少一个匹配时,INNER JOIN 关键字返回行
SELECT
*
FROM
albums
JOIN
artists ON albums.artist_id = artists.id; # INNER JOIN等价于JOIN,写JOIN默认为INNER JOIN
In SQL, joins are used to combine rows from two or more tables. The most common type of join in SQL is an inner join.
An inner join will combine rows from different tables if the join condition is true.
1. SELECT *: specifies the columns our result set will have. Here * refers to every column in both tables;
2. FROM albums: specifies first table we are querying;
3. JOIN artists ON: specifies the type of join as well as the second table;
4. albums.artist_id = artists.id: is the join condition that describes how the two tables are related to each other. Here, SQL uses the foreign key column "artist_id" in the "albums" table to match it with exactly one row in the "artists" table with the same value in the "id" column. It will only match one row in the "artists" table because "id" is the PRIMARY KEY of "artists".
4.6 Left Outer Join 左外连接:即使右表中没有匹配,也从左表返回所有的行
SELECT
*
FROM
albums
LEFT JOIN
artists ON albums.artist_id = artists.id;
Outer joins also combine rows from two or more tables, but unlike inner joins, they do not require the join condition to be met. Instead, every row in the left table is returned in the result set, and if the join condition is not met, the NULL values are used to fill in the columns from the right table.
RIGHT JOIN 右外链接:即使左表中没有匹配,也从右表返回所有的行
FULL JOIN 全链接:只要其中一个表中存在匹配,就返回行
4.7 Aliases 为列名称和表名称指定别名
AS is a keyword in SQL that allows you to rename a column or table using an alias. The new name can be anything you want as long as you put it inside of single quotes.
SELECT
albums.name AS ‘Album‘,
albums.year,
artists.name AS ‘Artist‘
FROM
albums
JOIN
artists ON albums.artist_id = artists.id
WHERE
albums.year > 1980;
NB
The columns have not been renamed in either table. The aliases only appear in the result set.
II. SQL: Table Transformation
1. Subqueries 子查询
1.2 Non-Correlated Subqueries I 不相关子查询
SELECT
*
FROM
flights
WHERE
origin IN (SELECT
code
FROM
airports
WHERE
elevation > 2000);
1.4 Non-Correlated Subqueries III
SELECT
a.dep_month,
a.dep_day_of_week,
AVG(a.flight_count) AS average_flights
FROM
(SELECT
dep_month,
dep_day_of_week,
dep_date,
COUNT(*) AS flight_count
FROM
flights
GROUP BY 1 , 2 , 3) a
WHERE
a.dep_day_of_week = ‘Friday‘
GROUP BY 1 , 2
ORDER BY 1 , 2; # 返回每个月中,每个星期五的平均航班数量
结构
[outer query]
FROM
[inner query] a
WHERE
GROUP BY
ORDER BY
NB
"a": With the inner query, we create a virtual table. In the outer query, we can refer to the inner query as "a".
"1,2,3" in inner query: refer to the first, second and third columns selected
for display DBMS
SELECT dep_month, (1)
dep_day_of_week, (2)
dep_date, (3)
COUNT(*) AS flight_count (4)
FROM flights
SELECT
a.dep_month,
a.dep_day_of_week,
AVG(a.flight_distance) AS average_distance
FROM
(SELECT
dep_month,
dep_day_of_week,
dep_date,
SUM(distance) AS flight_distance
FROM
flights
GROUP BY 1 , 2 , 3) a
GROUP BY 1 , 2
ORDER BY 1 , 2; # 返回每个月中,每个周一、周二……至周日的平均飞行距离
1.5 Correlated Subqueries I 相关子查询
NB
In a correlated subquery, the subquery can not be run independently of the outer query. The order of operations is important in a correlated subquery:
1. A row is processed in the outer query;
2. Then, for that particular row in the outer query, the subquery is executed.
This means that for each row processed by the outer query, the subquery will also be processed for that row.
SELECT
id
FROM
flights AS f
WHERE
distance > (SELECT
AVG(distance)
FROM
flights
WHERE
carrier = f.carrier); # the list of all flights whose distance is above average for their carrier
1.6 Correlated Subqueries II
In the above query, the inner query has to be reexecuted for each flight. Correlated subqueries may appear elsewhere besides the WHERE clause, they can also appear in the SELECT.
SELECT
carrier,
id,
(SELECT
COUNT(*)
FROM
flights f
WHERE
f.id < flights.id
AND f.carrier = flights.carrier) + 1 AS flight_sequence_number
FROM
flights; # 结果集为航空公司,航班id以及序号。相同航空公司的航班,id越大则序号越大
相关子查询中,对于外查询执行的每一行,子查询都会为这一行执行一次。在这段代码中,每当外查询提取一行数据中的carrier和id,子查询就会COUNT表中有多少行的carrier与外查询中的行的carrier相同,且id小于外查询中的行,并在COUNT结果上+1,这一结果列别名为flight_sequence_number。于是,id越大的航班,序号就越大。
如果将"<"改为">",则id越大的航班,序号越小。
2. Set Operation
2.2 Union 并集 (only distinct values)
Sometimes, we need to merge two tables together and then query the merged result.
There are two ways of doing this:
1) Merge the rows, called a join.
2) Merge the columns, called a union.
SELECT
item_name
FROM
legacy_products
UNION SELECT
item_name
FROM
new_products;
Each SELECT statement within the UNION must have the same number of columns with similar data types. The columns in each SELECT statement must be in the same order. By default, the UNION operator selects only distinct values.
2.3 Union All 并集 (allows duplicate values)
SELECT
AVG(sale_price)
FROM
(SELECT
id, sale_price
FROM
order_items UNION ALL SELECT
id, sale_price
FROM
order_items_historic) AS a;
2.4 Intersect 交集
Microsoft SQL Server‘s INTERSECT returns any distinct values that are returned by both the query on the left and right sides of the INTERSECT operand.
SELECT category FROM new_products
INTERSECT
SELECT category FROM legacy_products;
NB
MySQL不滋瓷INTERSECT,但可以用INNER JOIN+DISTINCT或WHERE...IN+DISTINCT或WHERE EXISTS实现:
SELECT DISTINCT
category
FROM
new_products
INNER JOIN
legacy_products USING (category);
或
SELECT DISTINCT
category
FROM
new_products
WHERE
category IN (SELECT
category
FROM
legacy_products);
网上很多通过UNION ALL 实现的办法(如下)是错误的,可能会返回仅在一个表中出现且COUNT(*) > 1的值:
SELECT
category, COUNT(*)
FROM
(SELECT
category
FROM
new_products UNION ALL SELECT
category
FROM
legacy_products) a
GROUP BY category
HAVING COUNT(*) > 1;
2.5 Except (MS SQL Server) / Minus (Oracle) 差集
SELECT category FROM legacy_products
EXCEPT # 在Oracle中为MINUS
SELECT category FROM new_products;
NB
MySQL不滋瓷差集,但可以用WHERE...IS NULL+DISTINCT或WHERE...NOT IN+DISTINCT或WHERE EXISTS实现:
SELECT DISTINCT
category
FROM
legacy_products
LEFT JOIN
new_products USING (category)
WHERE
new_products.category IS NULL;
或
SELECT DISTINCT
category
FROM
legacy_products
WHERE
category NOT IN (SELECT
category
FROM
new_products);
3. Conditional Aggregates
3.2 NULL
use IS NULL or IS NOT NULL in the WHERE clause to test whether a value is or is not null.
SELECT
COUNT(*)
FROM
flights
WHERE
arr_time IS NOT NULL
AND destination = ‘ATL‘;
3.3 CASE WHEN "if, then, else"
SELECT
CASE
WHEN elevation < 250 THEN ‘Low‘
WHEN elevation BETWEEN 250 AND 1749 THEN ‘Medium‘
WHEN elevation >= 1750 THEN ‘High‘
ELSE ‘Unknown‘
END AS elevation_tier
, COUNT(*)
FROM airports
GROUP BY 1;
END is required to terminate the statement, but ELSE is optional. If ELSE is not included, the result will be NULL.
3.4 COUNT(CASE WHEN)
count the number of low elevation airports by state where low elevation is defined as less than 1000 ft.
SELECT
state,
COUNT(CASE
WHEN elevation < 1000 THEN 1
ELSE NULL
END) AS count_low_elevaton_airports
FROM
airports
GROUP BY state;
3.5 SUM(CASE WHEN)
sum the total flight distance and compare that to the sum of flight distance from a particular airline (in this case, Delta) by origin airport.
SELECT
origin,
SUM(distance) AS total_flight_distance,
SUM(CASE
WHEN carrier = ‘DL‘ THEN distance
ELSE 0
END) AS total_delta_flight_distance
FROM
flights
GROUP BY origin;
3.6 Combining aggregates
find out the percentage of flight distance that is from Delta by origin airport.
SELECT
origin,
100.0 * (SUM(CASE
WHEN carrier = ‘DL‘ THEN distance
ELSE 0
END) / SUM(distance)) AS percentage_flight_distance_from_delta
FROM
flights
GROUP BY origin;
3.7 Combining aggregates II
Find the percentage of high elevation airports (elevation >= 2000) by state from the airports table.
SELECT
state,
100.0 * COUNT(CASE
WHEN elevation >= 2000 THEN 1
ELSE NULL
END) / COUNT(elevation) AS percentage_high_elevation_airports
FROM
airports
GROUP BY 1;
或
SELECT
state,
100.0 * SUM(CASE
WHEN elevation >= 2000 THEN 1
ELSE 0
END) / COUNT(elevation) AS percentage_high_elevation_airports
FROM
airports
GROUP BY 1;
4. Date, Number and String Functions
MySQL Date 函数:
NOW() 返回当前的日期和时间
CURDATE() 返回当前的日期
CURTIME() 返回当前的时间
DATE() 提取日期或日期/时间表达式的日期部分
EXTRACT() 返回日期/时间的单独部分,比如年、月、日、小时、分钟等等
DATE_ADD() 给日期添加指定的时间间隔
DATE_SUB() 从日期减去指定的时间间隔
DATEDIFF() 返回两个日期之间的天数
DATE_FORMAT() 用不同的格式显示日期/时间
例1:
SELECT NOW(), CURDATE(), CURTIME();
结果:
NOW() CURDATE() CURTIME()
2008-12-29 16:25:46 2008-12-29 16:25:46
例2:
CREATE TABLE Orders (
OrderId INT NOT NULL,
ProductName VARCHAR(50) NOT NULL,
OrderDate DATETIME NOT NULL DEFAULT NOW (),
PRIMARY KEY (OrderId)
);
OrderDate 列规定 NOW() 作为默认值。作为结果,当您向表中插入行时,当前日期和时间自动插入列中。
例3:
EXTRACT (unit FROM date): date参数是合法的日期表达式,unit参数可以是下列值:
DATE_ADD(date,INTERVAL expr type): date参数是合法的日期表达式,expr是希望添加的时间间隔,type参数可以是下列值:
DATE_SUB(date,INTERVAL expr type): date参数是合法的日期表达式,expr是希望添加的时间间隔,type参数可以是下列值:
MICROSECOND
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
SECOND_MICROSECOND
MINUTE_MICROSECOND
MINUTE_SECOND
HOUR_MICROSECOND
HOUR_SECOND
HOUR_MINUTE
DAY_MICROSECOND
DAY_SECOND
DAY_MINUTE
DAY_HOUR
例4:
DATEDIFF(date1,date2): date1 和 date2 参数是合法的日期或日期/时间表达式。只有值的日期部分参与计算。
例5:
DATE_FORMAT(date,format): date 参数是合法的日期。format 规定日期/时间的输出格式。
SELECT
id,
carrier,
origin,
destination,
DATE_FORMAT(NOW(), ‘%Y-%c-%d %T‘) AS datetime
FROM
flights;
4.2 Dates
select the date and time of all deliveries in the baked_goods table using the column delivery_time.
SELECT
DATE(delivery_time), TIME(delivery_time)
FROM
baked_goods;
4.4 Dates III
Each of the baked goods is packaged five hours, twenty minutes, and two days after the delivery. Create a query returning all the packaging times for the goods in the baked_goods table.
SELECT
DATE_ADD(delivery_time,
INTERVAL ‘2 5:20:00‘ DAY_SECOND) AS package_time
FROM
baked_goods;
DATE:
4.6 Numbers II
GREATEST(n1,n2,n3,...): returns the greatest value in the set of the input numeric expressions;
LEAST(n1,n2,n3,...): returns the least value in the set of the input numeric expressions;
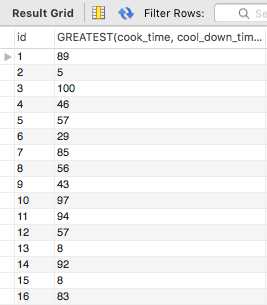
Find the greatest time value for each item.
SELECT
id, GREATEST(cook_time, cool_down_time)
FROM
baked_goods;
NB:不同数据类型的比较规则
上述命令的结果集为:
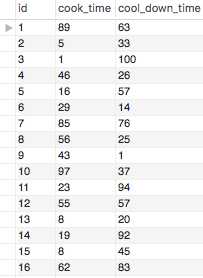
而baked_goods中的cook_time和cool_down_time实际为:
显然row 2,13和15中的33>5,20>8,45>8,但GREATEST返回的是较小的值
这是因为cook_time和cool_down_time这两列的数据类型是TEXT:
在GREATEST和LEAST命令中,
当数据类型为TEXT等文本类时,比较的是字符串的大小,即从字符串的首个字符开始比较。‘5‘比>3‘,所以‘5‘>‘33‘。‘T‘>‘R‘,所以‘TORRES‘>‘RENE‘;
当数据类型为INT、BIGINT等数字类时,比较的才是数值的大小。
4.7 Strings
CONCAT(concatenate):
Combine the first_name and last_name columns from the bakeries table as the full_name.
SELECT
CONCAT(first_name, ‘ ‘, last_name) AS full_name
FROM
bakeries;
GROUP_CONCAT:
Combine the cities of the three states in city column from bakeries table as cities.
SELECT
state, GROUP_CONCAT(DISTINCT (city)) AS cities
FROM
bakeries
WHERE
state IN (‘California‘ , ‘New York‘, ‘Texas‘)
GROUP BY state;
NB
CONCAT返回结果为连接参数产生的字符串。
如有任何一个参数为NULL ,则返回值为 NULL;
如果所有参数均为非二进制字符串,则结果为非二进制字符串;
如果自变量中含有任一二进制字符串,则结果为一个二进制字符串;
一个数字参数被转化为与之相等的二进制字符串格式;可使用显示类型CAST避免这种情况,例如:
SELECT CONCAT(CAST(int_col AS CHAR), char_col)
CAST:
例1:
SELECT CAST(12 AS DECIMAL) / 3;
Returns the result as a DECIMAL by casting one of the values as a decimal rather than an integer.
例2:
SELECT
CONCAT(CAST(distance AS CHAR), ‘ ‘, city)
FROM
bakeries;
4.8 Strings II
REPLACE(string,from_string,to_string);
The function returns the string ‘string‘ with all occurrences of the string ‘from_string‘ replaced by the string ‘to_string‘.
Replace ‘enriched_flour‘ in the ingredients list to just ‘flour‘.
SELECT
id,
REPLACE(ingredients,
‘enriched_flour‘,
‘flour‘)
FROM
baked_goods;
III. SQL: Analyzing Business Metrics
1. Advanced Aggregates
1.4 Daily Revenue
how much we‘re making per day for kale-smoothies.
SELECT
DATE(ordered_at), ROUND(SUM(amount_paid), 2)
FROM
orders
JOIN
order_items ON orders.id = order_items.order_id
WHERE
name = ‘kale-smoothie‘
GROUP BY 1
ORDER BY 1;
1.6 Meal Sums
total revenue of each item.
SELECT
name, ROUND(SUM(amount_paid), 2)
FROM
order_items
GROUP BY name
ORDER BY 2 DESC;
1.7 Product Sum 2
percent of revenue each product represents.
SELECT
name,
ROUND(SUM(amount_paid) / (SELECT
SUM(amount_paid)
FROM
order_items) * 100.0,
2) AS PCT
FROM
order_items
GROUP BY 1
ORDER BY 2 DESC;
Subqueries can be used to perform complicated calculations and create filtered or aggregate tables on the fly.
1.9 Grouping with Case Statements
group the order items by what type of food they are.
SELECT
*,
CASE name
WHEN ‘kale-smoothie‘ THEN ‘smoothie‘
WHEN ‘banana-smoothie‘ THEN ‘smoothie‘
WHEN ‘orange-juice‘ THEN ‘drink‘
WHEN ‘soda‘ THEN ‘drink‘
WHEN ‘blt‘ THEN ‘sandwich‘
WHEN ‘grilled-cheese‘ THEN ‘sandwich‘
WHEN ‘tikka-masala‘ THEN ‘dinner‘
WHEN ‘chicken-parm‘ THEN ‘dinner‘
ELSE ‘other‘
END AS category
FROM
order_items
ORDER BY id;
look at percents of purchase by category:
SELECT
CASE name
WHEN ‘kale-smoothie‘ THEN ‘smoothie‘
WHEN ‘banana-smoothie‘ THEN ‘smoothie‘
WHEN ‘orange-juice‘ THEN ‘drink‘
WHEN ‘soda‘ THEN ‘drink‘
WHEN ‘blt‘ THEN ‘sandwich‘
WHEN ‘grilled-cheese‘ THEN ‘sandwich‘
WHEN ‘tikka-masala‘ THEN ‘dinner‘
WHEN ‘chicken-parm‘ THEN ‘dinner‘
ELSE ‘other‘
END AS category,
ROUND(1.0 * SUM(amount_paid) / (SELECT
SUM(amount_paid)
FROM
order_items) * 100,
2) AS PCT
FROM
order_items
GROUP BY 1
ORDER BY 2 DESC;
NB
Here 1.0 * is a shortcut to ensure the database represents the percent as a decimal.
1.11 Recorder Rates
We‘ll define reorder rate as the ratio of the total number of orders to the number of people making those orders. A lower ratio means most of the orders are reorders. A higher ratio means more of the orders are first purchases.
SELECT
name,
ROUND(1.0 * COUNT(DISTINCT order_id) / COUNT(DISTINCT delivered_to),
2) AS reorder_rate
FROM
order_items
JOIN
orders ON orders.id = order_items.order_id
GROUP BY 1
ORDER BY 2 DESC;
2. Common Metrics
2.2 Daily Revenue
SELECT
DATE(created_at), ROUND(SUM(price), 2)
FROM
purchases
GROUP BY 1
ORDER BY 1;
2.3 Daily Revenue 2
Update our daily revenue query to exclude refunds.
SELECT
DATE(created_at), ROUND(SUM(price), 2) AS daily_rev
FROM
purchases
WHERE
refunded_at IS NULL
GROUP BY 1
ORDER BY 1;
这里Codecademy的Instructions和代码识别都要求“WHERE refunded_at IS NOT NULL”,应该是写错了。
2.4 Daily Active Users
Calculate DAU
SELECT
DATE(created_at), COUNT(DISTINCT user_id) AS DAU
FROM
gameplays
GROUP BY 1
ORDER BY 1;
2.5 Daily Active Users 2
Calculate DAU per-platform
SELECT
DATE(created_at), platform, COUNT(DISTINCT user_id) AS DAU
FROM
gameplays
GROUP BY 1 , 2
ORDER BY 1 , 2;
2.6 Daily Average Revenue Per Paying User(ARPPU)
Calculate Daily ARPPU
SELECT
DATE(created_at),
ROUND(SUM(price) / COUNT(DISTINCT user_id), 2) AS ARPPU
FROM
purchases
WHERE
refunded_at IS NULL
GROUP BY 1
ORDER BY 1;
2.8 ARPU 2
One way to create and organize temporary results in a query is with CTEs, Common Table Expressions, aka WITH ... AS clauses. The WITH ... AS clauses make it easy to define and use results in a more organized way than subqueries.
NB
MySQL不滋瓷CTE。可能可以用临时表实现,待验证。(?)
Calculate Daily Revenue
WITH daily_revenue AS
(
SELECT
date(created_at) AS dt,
ROUND(SUM(price), 2) AS rev
FROM
purchases
WHERE refunded_at IS NULL
GROUP BY 1
)
SELECT
*
FROM
daily_revenue
ORDER BY dt;
2.9 ARPU 3
Calculate Daily ARPU
WITH daily_revenue AS (
SELECT
DATE(created_at) AS dt,
ROUND(SUM(price), 2) AS rev
FROM purchases
WHERE refunded_at IS NULL
GROUP BY 1
),
daily_players AS (
SELECT
DATE(created_at) AS dt,
COUNT(DISTINCT user_id) AS players
FROM gameplays
GROUP BY 1
)
SELECT
daily_revenue.dt,
daily_revenue.rev / daily_players.players
FROM daily_revenue
JOIN daily_players USING (dt);
2.12 1 Day Retention 2
SELF JOIN:
By using a self-join, we can make multiple gameplays available on the same row of results. This will enable us to calculate retention.
The power of self-join comes from joining every row to every other row. This makes it possible to compare values from two different rows in the new result set.
SELECT
DATE(g1.created_at) AS dt, g1.user_id
FROM
gameplays AS g1
JOIN
gameplays AS g2 ON g1.user_id = g2.user_id
ORDER BY 1
LIMIT 100;
2.13 1 Day Retention 3
Calculate 1 Day Retention Rate
SELECT
DATE(g1.created_at) AS dt,
ROUND(100 * COUNT(DISTINCT g2.user_id) / COUNT(DISTINCT g1.user_id)) AS retention
FROM
gameplays AS g1
LEFT JOIN
gameplays AS g2 ON g1.user_id = g2.user_id
AND DATE(g1.created_at) = DATE(DATE_SUB(g2.created_at, INTERVAL 1 DAY))
GROUP BY 1
ORDER BY 1;
NB
游戏行业中,公认的次日留存率(1 Day Retention Rate)定义为:DNU在次日再次登录的比例。而本题计算的是:DAU在次日再次登录的比例。
IV. 附录
1. DISTINCT和GROUP BY的去重逻辑浅析
SELECT
COUNT(DISTINCT amount_paid)
FROM
order_items;
或
SELECT
COUNT(1)
FROM
(SELECT
1
FROM
order_items
GROUP BY amount_paid) a;
或
SELECT
SUM(1)
FROM
(SELECT
1
FROM
order_items
GROUP BY amount_paid) a;
分别是在运算和存储上的权衡:
DISTINCT需要将列中的全部内容存储在一个内存中,将所有不同值存起来,内存消耗可能较大;
GROUP BY先将列排序,排序的基本理论是:时间复杂为nlogn,空间为1。优点是空间复杂度小,(?)缺点是执行时间会较长。
使用时根据具体情况取舍:数据分布离散时,使用GROUP BY;数据分布集中时,使用DISTINCT,效率高,空间占用较小。
2. SELECT 1 FROM table
1是一常量(可以为任意数值),查到的所有行的值都是它,但从效率上来说,1>column name>*,因为不用查字典表(?)。
没有特殊含义,只要有数据就返回1,没有则返回NULL。
常用于EXISTS、子查询中,一般在判断子查询是否成功(即是否有满足条件)时使用,如:
SELECT
*
FROM
orders
WHERE
EXISTS( SELECT
1
FROM
orders o
JOIN
order_items i ON o.id = i.order_id);
3. WHERE 1=1和WHERE 1=0的作用
3.1 WHERE 1=1:条件恒真,同理WHERE ‘a‘ = ‘a‘等。在构造动态SQL语句,如:不定数量查询条件时,1=1可以很方便地规范语句:
3.1.1 制作查询页面时,若可查询的选项有多个,且用户可自行选择并输入关键词,那么按照平时的查询语句的动态构造,代码大致如下:
MySqlStr="SELECT * FROM table WHERE";
IF(Age.Text.Lenght>0)
{
MySqlStr=MySqlStr+"Age="+"‘Age.Text‘";
}
IF(Address.Text.Lenght>0)
{
MySqlStr=MySqlStr+"AND Address="+"‘Address.Text‘";
}
1)如果上述的两个IF判断语句,均为True,即用户都输入了查询词,那么,最终的MySqlStr动态构造语句变为:
MySqlStr="SELECT * FROM table WHERE Age=‘27‘ AND Address=‘广东省深圳市南山区科兴科学园‘"语句完整,能够被正确执行;
2)如果两个IF都不成立,MySqlStr="SELECT * FROM table WHERE";,语句错误,无法执行。
3.1.2 使用WHERE 1=1:
1)MySqlStr="SELECT * FROM table WHERE 1=1 AND Age=‘27‘ AND Address=‘广东省深圳市南山区科兴科学园‘";,正确可执行;
2)MySqlStr="SELECT * FROM table WHERE 1=1";,由于WHERE 1=1恒真,该语句能够被正确执行,作用相当于:MySqlStr="SELECT * FROM table";
也就是说:如果用户在多条件查询页面中,不选择任何字段、不输入任何关键词,那么,必将返回表中所有数据;如果用户在页面中,选择了部分字段并且输入了部分查询关键词,那么,就按用户设置的条件进行查询。
WHERE 1=1仅仅只是为了满足多条件查询页面中不确定的各种因素而采用的一种构造一条正确能运行的动态SQL语句的一种方法。
3.2 WHERE 1=0:条件恒假,同理WHERE 1 <> 1等。不会返回任何数据,只有表结构,可用于快速建表:
3.2.1 用于读取表的结构而不考虑表中的数据,这样节省了内存,因为可以不用保存结果集:
SELECT
*
FROM
table
WHERE
1 = 0;
3.2.2 创建一个新表,新表的结构与查询的表的结构相同:
CREATE TABLE newtable AS SELECT * FROM
oldtable
WHERE
1 = 0;
4. 复制表
CREATE TABLE newtable AS SELECT * FROM
oldtable;
5. Having
NB
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数(aggregate function)一起使用。常用的聚合函数有:COUNT,SUM,AVG,MAX,MIN等。
例1:查找订单总金额少于 2000 的客户
SELECT
Customer, SUM(OrderPrice)
FROM
Orders
GROUP BY Customer
HAVING SUM(OrderPrice) < 2000;
例2:查找客户 "Bush" 或 "Adams" 拥有超过 1500 的订单总金额
SELECT
Customer, SUM(OrderPrice)
FROM
Orders
WHERE
Customer = ‘Bush‘ OR Customer = ‘Adams‘
GROUP BY Customer
HAVING SUM(OrderPrice) > 1500;
6. USING
It is mostly syntactic sugar, but a couple differences are noteworthy:
ON is the more general of the two. One can JOIN tables ON a column, a set of columns and even a condition. For example:
SELECT
*
FROM
world.City
JOIN
world.Country ON (City.CountryCode = Country.Code)
WHERE ...
USING is useful when both tables share a column of the exact same name on which they join. In this case, one may say:
SELECT
film.title, film_id # film_id is not prefixed
FROM
film
JOIN
film_actor USING (film_id)
WHERE ...
To do the above with ON, we would have to write:
SELECT
film.title, film.film_id # film.film_id is required here
FROM
film
JOIN
film_actor ON (film.film_id = film_actor.film_id)
WHERE ...
NB film.film_id qualification in the SELECT clause. It would be invalid to just say film_id since that would make for an ambiguity.
7. IFNULL()和COALESCE()函数 用于规定如何处理NULL值
假如 "UnitsOnOrder" 列可选,且包含 NULL 值。使用:
SELECT
ProductName, UnitPrice * (UnitsInStock + UnitsOnOrder)
FROM
Products;
由于 "UnitsOnOrder" 列存在NULL值,那么结果是 NULL。
为了便于计算,我们希望如果值是NULL,则返回0:
SELECT
ProductName, UnitPrice * (UnitsInStock + IFNULL(UnitsOnOrder, 0))
FROM
Products;
或
SELECT
ProductName, UnitPrice * (UnitsInStock + COALESCE(UnitsOnOrder, 0))
FROM
Products;
8. UCASE()和LCASE()函数 字段值得大小写转换
SELECT
LCASE(first_name) AS first_name,
last_name,
city,
UCASE(state) AS state
FROM
bakeries;
9. MID()函数 用于从文本字段中提取字符
SELECT
MID(column_name, start, length)
FROM
table_name;
column_name: 必需。要提取字符的字段。
start: 必需。规定开始位置(起始值是 1)。
length: 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。
SELECT
MID(state, 1, 3) AS smallstate
FROM
bakeries;
10. LENGTH()函数 返回文本字段中 值的长度
SELECT
LENGTH(City) AS LengthOfCity
FROM
bakeries;
11. WHERE EXISTS命令
11.1 WHERE EXISTS与WHERE NOT EXISTS
EXISTS:判断子查询得到的结果集是否是一个空集,如果不是,则返回 True,如果是,则返回 False。即:如果在当前的表中存在符合条件的这样一条记录,那么返回 True,否则返回 False。
NOT EXISTS:作用与 EXISTS 正相反,当子查询的结果为空集时,返回 True,反之返回 False。也就是所谓的”若不存在“。
EXISTS和NOT EXISTS所在的查询属于相关子查询,即:对于外层父查询中的每一行,都执行一次子查询。先取父查询的第一个元组,根据它与子查询相关的属性处理子查询,若子查询WHERE条件表达式成立,则表达式返回True,则将此元组放入结果集,以此类推,直到遍历父查询表中的所有元组。
查询选修了任意课程的学生的姓名:
SELECT
Sname
FROM
student
WHERE
EXISTS( SELECT
*
FROM
sc,
course
WHERE
sc.Sno = student.Sno
AND sc.Cno = course.Cno);
查询未被200215123号学生选修的课程的课名:
SELECT
Cname
FROM
course
WHERE
NOT EXISTS( SELECT
*
FROM
sc
WHERE
Sno = 200215123
AND Cno = course.Cno);
11.2 WHERE EXISTS与WHERE NOT EXISTS的双层嵌套
1)查询选修了全部课程的学生的课程:
SELECT
Sname
FROM
student
WHERE
NOT EXISTS( SELECT
*
FROM
course
WHERE
NOT EXISTS( SELECT
*
FROM
sc
WHERE
Sno = student.Sno AND Cno = course.Cno));
思路:
STEP1:先取 Student 表中的第一个元组,得到其 Sno 列的值。
STEP2:再取 Course 表中的第一个元组,得到其 Cno 列的值。
STEP3:根据 Sno 与 Cno 的值,遍历 SC 表中的所有记录(也就是选课记录)。若对于某个 Sno 和 Cno 的值来说,在 SC 表中找不到相应的记录,则说明该 Sno 对应的学生没有选修该 Cno 对应的课程。
STEP4:对于某个学生来说,若在遍历 Course 表中所有记录(也就是所有课程)后,仍找不到任何一门他/她没有选修的课程,就说明此学生选修了全部的课程。
STEP5:将此学生放入结果元组集合中。
STEP6:回到 STEP1,取 Student 中的下一个元组。
STEP7:将所有结果元组集合显示。
其中第一个 NOT EXISTS 对应 STEP4,第二个 NOT EXISTS 对应 STEP3。
2)查询被所有学生选修的课程的课名:
SELECT
Cname
FROM
course
WHERE
NOT EXISTS( SELECT
*
FROM
student
WHERE
NOT EXISTS( SELECT
*
FROM
sc
WHERE
Cno = course.Cno AND Sno = student.Sno));
3)查询选修了200215123号学生选修的全部课程的学生的学号:
SELECT
DISTINCT Sno
FROM
sc scx
WHERE
NOT EXISTS( SELECT
*
FROM
sc scy
WHERE scy.Sno = 200215123
AND NOT EXISTS( SELECT
*
FROM
sc
WHERE
Sno = scx.Sno AND Cno = scy.Cno));
扩展:
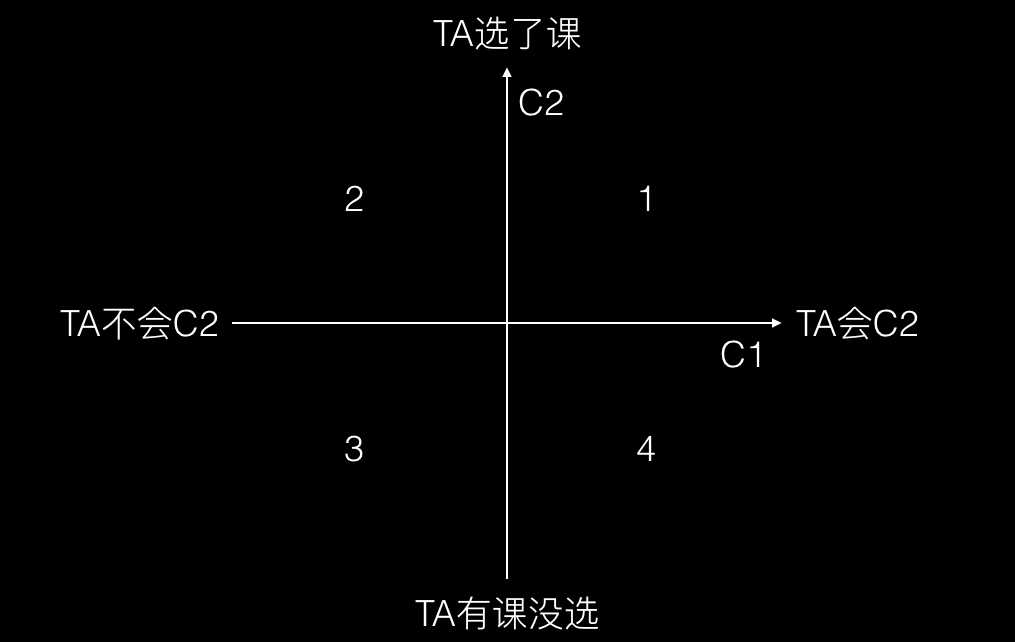
1. Condition 1:TA会C2。Condition 2:TA选修了课程 => exists+exists:查询选修了任意课程的学生;
2. Condition 1:TA不会C2。Condition 2:TA选修了课程 => not exists+exists:查询未选修任何课程的学生;
3. Condition 1:TA不会C2。Condition 2:TA有课程课没选 => not exists+not exists:查询选修了所有课程的学生;
4. Condition 1:TA会C2。Condition 2:TA有课程没选 => exists+not exists:查询未选修所有课程的学生;
11.3 WHERE EXISTS与WHERE IN的比较与使用
SELECT
Sname
FROM
student
WHERE
EXISTS( SELECT
*
FROM
sc,
course
WHERE
sc.Sno = student.Sno
AND sc.Cno = course.Cno
AND course.Cname = ‘操作系统‘);
SELECT
Sname
FROM
student
WHERE
Sno IN (SELECT
Sno
FROM
sc,
course
WHERE
sc.Sno = student.Sno
AND sc.Cno = course.Cno
AND course.Cname = ‘操作系统‘);
以上两个查询都返回选修了“操作系统”课程的学生的姓名,但原理不同:
EXISTS:对外表做loop循环,每次loop循环再对内表进行查询。首先检查父查询,然后运行子查询,直到它找到第一个匹配项。
IN:把内表和外表做hash连接。首先执行子查询,并将获得的结果存放在一个加了索引的临时表中。在执行子查询前,系统先将父查询挂起,待子查询执行完毕,存放在临时表中时以后再执行父查询。
因此:
1)如果两个表中一个较小,一个是较大,则子查询表大的用EXISTS,子查询表小的用IN;
2)在查询的两个表大小相当时,3种查询方式的执行时间通常是:
EXISTS <= IN <= JOIN
NOT EXISTS <= NOT IN <= LEFT JOIN
只有当表中字段允许NULL时,NOT IN最慢:
NOT EXISTS <= LEFT JOIN <= NOT IN
3)无论哪个表大,NOT EXISTS都比NOT IN快。因为NOT IN会对内外表都进行全表扫描,没有用到索引;而NOT EXISTS的子查询依然能用到表上的索引。
The trouble is, you think you have time.
SQL基础笔记
标签:客户 log idt list 表达 over mat miss 输入
原文地址:http://www.cnblogs.com/CXVurtne/p/6431549.html