标签:处理过程 height res element bin javascrip efi white 创建
本文所有讨论均基于jQuery版本3.1.1,官网http://jquery.com/。
Sizzle是用javascript实现的CSS selector engine,官网见https://sizzlejs.com/。官网上给出的Public API是
Sizzle( String selector[, DOMNode context[, Array results]] )
returns (Array): All elements matching the selector
由于现在大多数浏览器都支持CSS selector,所以大多数情况下Sizzle也是调用querySelectorAll 的。那么Sizzle的优势在哪儿呢?官网列出了很多,比如对低版本浏览器的支持,对CSS selector的增强等等。我的理解是随着浏览器软件的发展,Sizzle的价值在降低,但是其实现思路和技巧值得学习。
这里说的代码运行流程都是find时的流程,filter时的流程略有不同。
jQuery中的.find()和.filter()还有.not()方法都是调用Sizzle来实现的,而在创建jQuery对象时其实调用了.find()也就最终调用了Sizzle。比如:
$("div") -----> rootjQuery.find("div") ---------> jQuery.find("div", rootjQuery, ret) // rootjQuery是包含了window.document的jQuery object,ret是个空的jQuery object
jQuery.find就是Sizzle函数,所以用户代码其实可以直接调用Sizzle的,直接调用jQuery.find就可以了,当然这种做法是不推荐的,jQuery.find也不在jQuery API中。
对于简单的selector比如ID,CLASS或TAG,Sizzle直接调用原生的getElementByID,getElementsByClassName或getElementsByTagName来得到结果。
在用自己的算法处理之前,Sizzle会调用浏览器提供的native querySelectorAll,如果能得到结果就直接返回这个结果。
如果经过以上两步仍未得到结果,那么Sizzle就会调用select函数开始真正的Sizzle engine work。
未显示指定的情况下,比如$("div")时,jQuery会用window.document作为context,这样的话需要搜索匹配的DOM元素太多,效率不高。如果selector是类似于“#id > div”的形式,Sizzle会找到#id(通过原生的getElementByID),并把context置为这个element,这样就可以减小搜索匹配的范围,提高效率。
为了进一步提高效率,Sizzle还会从右向左地在selector中寻找ID,CLASS或TAG,找到的第一个ID,CLASS或TAG对应的elements就被设为seed。而最终在匹配时就只需要用seed中的element去匹配就可以了。
比如selector是"div > p",那么Sizzle会把seed设置为所有p元素,然后遍历seed从右到左地匹配"div >",这样比遍历context下所有的元素效率要高。
{ value: <selector字符串中的子字符串>, type: <token类型> matches: [<正则匹配时捕获的子表达式>]}

比如对selector字符串"div > p"做词法分析时结果如下,这里$.find就是jQuery中的Sizzle:

在上面这个例子中,两个正则表达式matchExpr["TAG"]和rcombinators先后匹配了selector字符串"div > p",产生了一个长度为3个token的tokens数组。注意tokenize返回的结果是tokens数组的数组,用逗号分隔的每个selector对应于一个数组元素。
superMatcher运行前面产生的element matcher和set matcher,得到Sizzle最终返回的结果。superMatcher接受的参数包括:
superMatcher在最终返回前还会去掉results中重复的DOM element,这样Sizzle运行结束后results中存放的就是在context下匹配selector的无重复的DOM element集合(Array)。
在matcherFromTokens中,处理过程如下:
每个element matcher都会形成闭包,element matcher运行时需要访问的变量或函数(其实都是javascript对象)就存放在闭包中。例如如果token的type是"TAG",那么matcherFromTokens就会调用下面的Expr.filter["TAG"]来得到对应的element matcher。这个element matcher运行时需要访问的变量nodeName就存放在闭包中,因为element matcher本身是Expr.filter["TAG"]的内部函数。不管这种形式叫”curry化的函数“还是”编译函数“,其本质就是javascript的闭包。
Expr = Sizzle.selectors = { ...... filter: { "TAG": function (nodeNameSelector) { // 闭包,即这个函数在compile阶段运行完之后,它的activation object仍然保留在内存中 var nodeName = nodeNameSelector.replace(runescape, funescape).toLowerCase(); return nodeNameSelector === "*" ? function () { return true; } : function (elem) { // element matcher,运行时通过作用域链读取闭包中的nodeName return elem.nodeName && elem.nodeName.toLowerCase() === nodeName; }; }, ...... }
Expr = Sizzle.selectors = { ...... filter: { "TAG": function (nodeNameSelector) { var nodeName = nodeNameSelector.replace(runescape, funescape).toLowerCase(); return nodeNameSelector === "*" ? function () { return true; } : function (elem) { return elem.nodeName && elem.nodeName.toLowerCase() === nodeName; }; }, ...... }
superMatcher运行时,会首先得到一个DOM element的集合,这个集合
然后superMatcher遍历这个DOM element集合,每次取出一个DOM element作为参数去调用element matcher,比如下图中最右边的那个element matcher。如果返回结果是true,那么这个element就是匹配对应的selector。
下面是个Sizzle compile和match的例子。这个例子中,我们忽略了Sizzle会对selector做的优化,也就是说我们假设Sizzle不会事先产生seed,这样selector还是"div > p"不会变成"div >"。
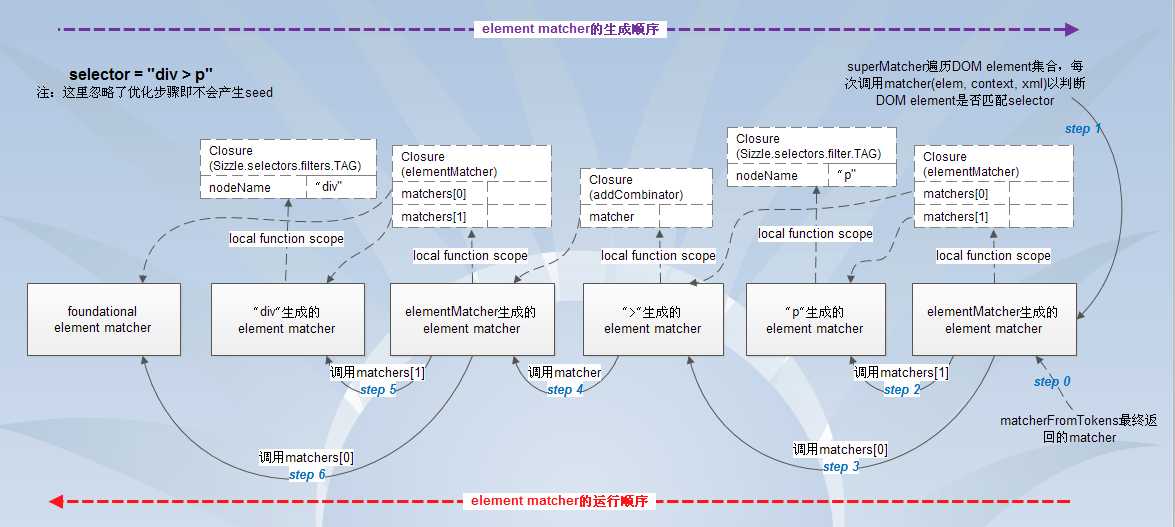
step 0. 在compile的时候,matcherFromTokens根据selector对应的tokens产生了element matcher。虽然整个过程中产生了6个element matcher,但最终返回的是最后产生的那个element matcher(由elementMatcher生成)。
step 1. superMatcher遍历备选DOM element集合,每次取出一个DOM element作为参数去调用compile时得到的element matcher。这个element matcher的代码如下:
function (elem, context, xml) { var i = matchers.length; while (i--) { if (!matchers[i](elem, context, xml)) { return false; } } return true; }
可以看出,
step 2. "p"生成的element matcher运行,判断传入的elem的nodeName是否等于存放在闭包中的nodeName(即字符串"p")。如果是的话,那么返回true,step 3继续运行;否则整个匹配过程结束,返回false。
step 3. ">"生成的element matcher运行,代码如下:
function (elem, context, xml) { while ((elem = elem[dir])) { // 这个例子中, dir="parentNode", checkNonElements=true if (elem.nodeType === 1 || checkNonElements) { return matcher(elem, context, xml); } } return false; }
这个element matcher找到传入的DOM element的父节点,然后用这个父节点作为参数去调用matcher,也就是用这个父节点去匹配">"关系符之前的那部分selector。如果这个父节点匹配成功,那么它返回true,否则它也匹配失败返回false。
step 4. 这个element matcher的代码与step 1中的代码是一模一样的,只不过它的matchers数组不同,指向了"div"的element matcher和foundational matcher。注意此时传入的DOM element已经不是step 1时的DOM element了,而是那个DOM element的父节点。
step 5. "div"生成的element matcher运行,与step 2类似,判断传入的elem的nodeName是否等于存放在闭包中的nodeName(即字符串"div")。如果是的话返回true,step 6继续运行;否则整个匹配过程结束,返回false。
step 6. foundational matcher做最后的检查,看看此时的DOM element是否可以从context这个”根节点“出发到达。如果是的话返回true,这样层层返回,最终superMatcher得到true的返回结果,即本次匹配成功。
只有当selector字符串中包含Sizzle自定义的位置伪类时,Sizzle才会生成set matcher。Sizzle的位置伪类是":first"、"last"、":even"、":odd"、”:eq“、”:lt“、":gt"和”:nth“,例如"div > p:first"就是一个包含了位置伪类的selector。
但是使用Sizzle自定义的位置伪不能立即使用native querySelectorAll来完成查找,降低了效率。所以jQuery API建议把$("div > p:first")写成$("div > p").filter(":first")。
其实Sizzle自定义的位置伪类都有替代的办法,比如$("div > p:first")就是$("div > p").first()。
当然Sizzle允许用户可以自己添加伪类,那样的话还是需要set matcher来支持伪类。
set mathcer的匹配方式和element matcher的匹配方式完全不同:
对于set matcher来说,一条selector分为4块,如下:

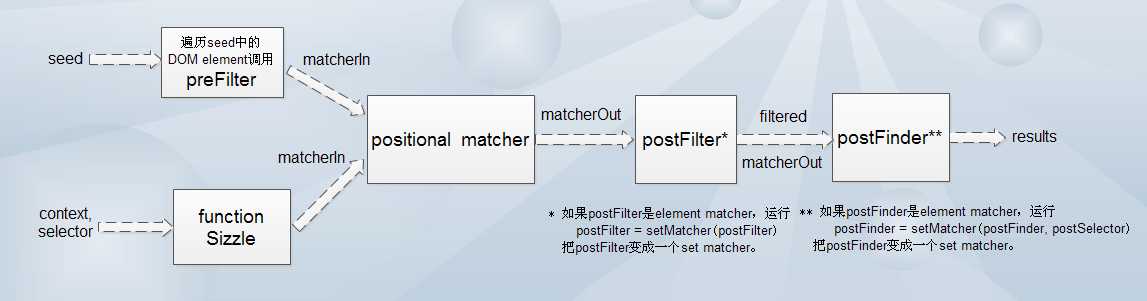
set matcher的signature类似于function(seed, results, context, xml),seed可以为

function condense(unmatched, map, filter, context, xml) { var elem, newUnmatched = [], i = 0, len = unmatched.length, mapped = map != null; for (; i < len; i++) { if ((elem = unmatched[i])) { if (!filter || filter(elem, context, xml)) { newUnmatched.push(elem); if (mapped) { map.push(i); } } } } return newUnmatched; }
positional matcher对于输入matcherIn进行处理,得到输出也是下一步postFilter的输入matcherOut。 所有位置伪类的逻辑都是相同的,就是从一个数组中找出其下标符合匹配条件的那些数组元素。例如":first"就是匹配下标为0的数组元素,":even"就是匹配下标是偶数的数组元素,":gt(argument)"就是匹配下标大于argument的数组元素,"eq(argument)"或"nth(argument)"就是匹配下标等于argument的数组元素。这样所有的positional matcher都如下:
function (seed, matches) { // set matcher调用这个函数时,matcherIn传递给形参seed,matcherOut传递给形参matches var j, matchIndexes = fn([], seed.length, argument), // fn和argument由位置伪类的种类决定,存放在闭包中 i = matchIndexes.length; // Match elements found at the specified indexes while (i--) { if (seed[(j = matchIndexes[i])]) { seed[j] = !(matches[j] = seed[j]); } } };
例如对于":first",fn = function() { return [0]; };,":even"对应的fn返回[0,2,4,...],其它位置伪类的fn类似。
postFilter对应的那部分selector可能包含位置伪类,也可能不包含位置伪类。前一种情况下,postFilter是element matcher,后一种情况下postFilter是set matcher。为方便统一处理,在前一种情况下,postFilter将会被转成set matcher。相应的代码如下:
// 在compile阶段运行 if (postFilter && !postFilter[expando]) { // set matcher函数的expando属性为true postFilter = setMatcher(postFilter); //把postFilter从element matcher转换成set matcher } //以下 在superMatcher运行set matcher时运行 ... ... temp = condense(matcherOut, postMap); // matcherOut可能包含placeholder,即可能是[elem1, false, elem2, false, false, elem3, ...]。condense函数去掉所有的placeholder,返回[elem1, elem2, elem3 ...]。 postFilter(temp, [], context, xml); // 效果相当于用最初的postFilter(一个element matcher)筛选了matcherOut,对于匹配的DOM element,在temp数组中对应的位置用placeholder也就是boolean false标记
最后matcherOut根据postFilter的结果进行更新,作为下一步postFinder的输入。
如果postSelector不包含位置伪类,那么postFinder就是element matcher。类似对于postFilter的处理,postFinder也会被转换成一个set matcher。代码如下:
// 在compile阶段运行 if (postFinder && !postFinder[expando]) { postFinder = setMatcher(postFinder, postSelector); } //以下 在superMatcher运行set matcher时运行 postFinder(null, results, matcherOut, xml); // seed === null时的语句
如果Step 1时有seed传入时调用postFinder的参数略有不同,因为要考虑到seed和results位置的同步,比如seed[2]最终匹配成功,那么seed[2]必须放在results[2],这样可以保证最终结果中DOM element的顺序与传入的seed相同。
经过这样的处理之后,运行(转换后的)postFinder会导致Sizzle(postSelector, <context>)被多次调用,每次调用时<context>置为上一步即postFilter输出中的一个DOM element。
这里jQuery有个小错误,多次调用Sizzle()的返回结果没有去掉重复的DOM element。例如对于
<div>
<p id="p1"></p>
<p id="p2"></p>
<p id="p3"></p>
<input type="text" id="unique">
</div>
用jQuery去选择DOM element时,下面的selector会返回两个一样的DOM element:

javascript的regular expressions参见https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Regular_Expressions。
由于对于javascript String来说,正则表达式字符"\“也是一个有特殊含义的character,所以要在javascript String里把字符"\"转义,即写成"\\",这才相当于在正则表达式里写了一个"\"。否则javascript会把"\"当作特殊字符来处理。例如"[\x20]"就会变成"[ ]"。
Sizzle用selector.replace(rtrim, "$1")来去掉selector字符串头尾可能存在的空白字符。rtrim的定义如下:
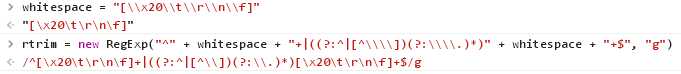
这里whitespace是在http://www.w3.org/TR/css3-selectors/#whitespace中定义的空白字符,它是我们熟知的\s的一个子集,只定义了5种空白符。
整个rtrim分为两个分支条件。
/^[\x20\t\r\n\f]+/匹配字符串开头的一到多个空白字符,由于没有使用任何括号进行分组,$1总是空字符串,这样用$1去替代整个匹配的字符串就相当于去掉了开头的空白字符。
/((?:^|[^\\])(?:\\.)*)[\x20\t\r\n\f]+$/中的最后部分/[\x20\t\r\n\f]+$/匹配字符串结尾的一到多个空白字符。
分组或者子表达式/((?:^|[^\\])(?:\\.))*)/分为两部分,第一部分/(?:^|[^\\])/匹配字符串开始或者任何一个非"\"字符的字符,第二部分/(?:\\.))*/匹配"\"字符加上任意一个字符,而且这样的第二部分可以出现多次也可以不出现。
那么组合起来,整个第二个分支表达式可以等效匹配4种字符串:
a. 字符串开始 + 字符串结尾的一到多个空白字符
b. 字符串开始 + "\"字符+任意一个字符(黑体字部分可反复出现多次) + 字符串结尾的一到多个空白字符
c. 一个非"\"字符的字符 + 字符串结尾的一到多个空白字符
d. 一个非"\"字符的字符 + "\"字符+任意一个字符(黑体字部分可反复出现多次) + 字符串结尾的一到多个空白字符
这样的话类似"p\\ "这样的javascript String就会被trim成为"p\ "(因为匹配了上面的d),也就是p后面那个被转义的空白符得到了保留。如下所示,每种情况都得到了正确的处理。

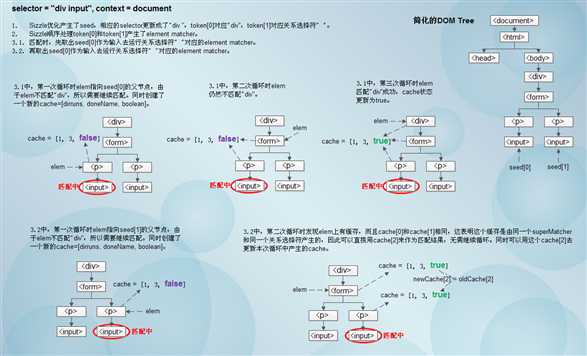
关系选择符“ ”和“~”对应的element matcher源码如下:
function (elem, context, xml) { var oldCache, uniqueCache, outerCache, newCache = [dirruns, doneName]; // We can‘t set arbitrary data on XML nodes, so they don‘t benefit from combinator caching if (xml) { while ((elem = elem[dir])) { if (elem.nodeType === 1 || checkNonElements) { if (matcher(elem, context, xml)) { return true; } } } } else { while ((elem = elem[dir])) { if (elem.nodeType === 1 || checkNonElements) { outerCache = elem[expando] || (elem[expando] = {}); // Support: IE <9 only // Defend against cloned attroperties (jQuery gh-1709) uniqueCache = outerCache[elem.uniqueID] || (outerCache[elem.uniqueID] = {}); if (skip && skip === elem.nodeName.toLowerCase()) { elem = elem[dir] || elem; } else if ((oldCache = uniqueCache[key]) && oldCache[0] === dirruns && oldCache[1] === doneName) { // Assign to newCache so results back-propagate to previous elements return (newCache[2] = oldCache[2]); } else { // Reuse newcache so results back-propagate to previous elements uniqueCache[key] = newCache; // A match means we‘re done; a fail means we have to keep checking if ((newCache[2] = matcher(elem, context, xml))) { return true; } } } } } return false; };
例子如下图:
标签:处理过程 height res element bin javascrip efi white 创建
原文地址:http://www.cnblogs.com/gaoyush/p/6418828.html
