标签:函数 letter ssi max add get 使用 公众账号 应该
背景说明
近期北京理财频道反馈用来存放股市实时数据的MongoDB数据库写响应请求很慢,难以跟上业务写入速度水平。我们分析了线上现场的情况,发现去年升级到SSD磁盘后,数据持久化的磁盘IO开销已经不是瓶颈.通过日志分析,线上单次写入(更新)请求大多在数十毫秒这个级别,数据库端观察几个主要的db在繁忙时通常有95%以上的时间在进行锁等待。线上数据库并发很高,接近1000个连接,所以怀疑是并发争用表锁导致性能不足。
我们知道MongoDB的mmap存储引擎一直是库/表级锁,因此任何写操作并发越高锁争用造成的性能损耗越大。为了改善锁并发性能MongoDB,升级到行级锁引擎应该能够改善线上更新数据的性能瓶颈。3.0的WT存储引擎和toku开发的tokumx存储引擎都号称实现了行级锁和多版本并发控制。因此,为了确定我们升级的方向,决定使用线上类似的场景,对三种存储引擎进行一次性能测试,评估最能改善并发更新写的方案。
我们取得了线上最繁忙的stock和stock_status数据,并且仿照线上并发更新最频繁的根据证券code更新的方式,在测试环境进行测验。
硬件环境
CPU: 24 核 Intel(R) Xeon(R) CPU E5-2630 0 @ 2.30GHz
内存: 48G
磁盘: SSD
MongoDB版本
1. Mmap存储引擎 MongoDB-2.6.9
2. Toku存储引擎 MongoDB-2.4.10
3. WiredTiger存储引擎 MongoDB 3.0.5
测试用例
从线上将股票信息表数据导入测试环境,创建与线上一致的索引,股票码code_id为唯一索引。
单纯写测试:从股票表stock中抽取1000个code_id,用随机函数获取其中一个code_id,对这一行数据进行一次update操作;
读写混合测试:在一定并发度的写操作情况下,以同样并发度通过code_id读取一行数据,读写混合比例为1:1。
测试脚本
1.写测试脚本
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import multiprocessing
import time
import random
import pymongo
client = pymongo.MongoClient("172.17.1.234", 27017)
db = client.stockdef get_id():
code_list = [1000个code_id]
code_loct = random.randint(0, 999)
up_value = random.randint(10, 99)/10.0
return code_list[code_loct], up_value
def update_func():
while True:
code_id, up_value = get_id()
db.stock.update_one({"CODE":str(code_id)},{"$set":
{"ASK1":str(up_value),"ASK2":str(up_value),"ASK3":str(up_value),"ASK4":str(up_value),"ASK5":str(up_value),"ASKVOL1":str(up_value),"ASKVOL2":str(up_value),"ASKVOL3":str(up_value),"ASKVOL4":str(up_value),"ASKVOL5":str(up_value),"BID1":str(up_value),"BID2":str(up_value),"BID3":str(up_value),"BID4":str(up_value),"BID5":str(up_value)}})
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=并发度)
for i in xrange(10000000):
pool.apply_async(update_func,)
pool.close()
pool.join()
print "\n" print "All done."#! /usr/bin/env python
# -*- coding: utf-8 -*-
import multiprocessing
import time
import random
import pymongo
client = pymongo.MongoClient("172.17.1.234", 27017)
db = client.stockdef get_id():
code_list = [1000个code_id]
code_loct = random.randint(0, 499)
return code_list[code_loct]
def update_func():
while True:
code_id = get_id()
db.stock.find_one({"CODE":str(code_id)},{"CODE":1,"ASK1":1,"ASK2":1})
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=并发度)
for i in xrange(1000000):
pool.apply_async(update_func,)
pool.close()
pool.join()
print "\n"
print "All done."
测试结果
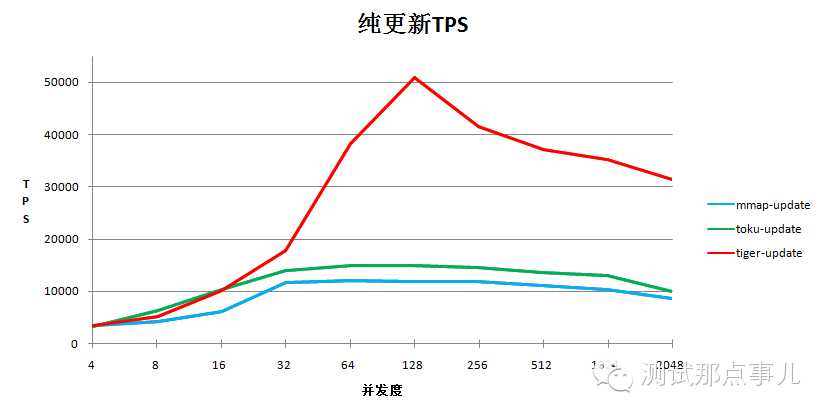
1.单纯写的测试结果
结论:WiredTiger在纯update测试场景中性能明显高于toku和mmap
a.toku和mmap并发度超过32后TPS稳定在1.4万到1.5万左右,此时整体DB的锁争用非常高
b.WiredTiger表现良好,128并发度时TPS处理能力达到5万多,更高并发下处理能力逐渐下降,稳定在3万到4万之间
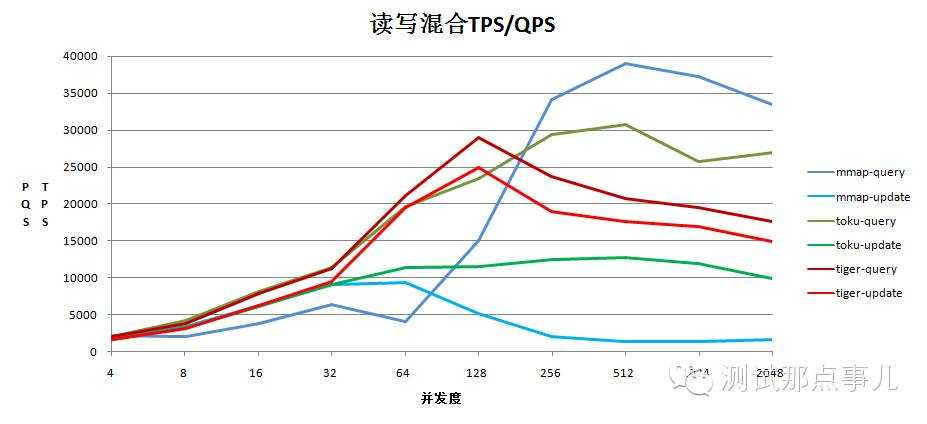
2.读写1比1混合的测试结果
结论:WiredTiger在读写1比1混合测试场景中,综合能力优于toku和mmap,且读写互不影响,都比较稳健
a.WiredTiger在读写混合测试场景中更新性能明显高于toku和mmap,读性能在高于256时不如toku和mmap,但是读写互不影响且性能较为稳定
b.mmap在高并发情况下读性能良好,但是更新性能下降很明显,受读的影响较大
c.toku在读写两端就像是WiredTiger和mmap的中庸版
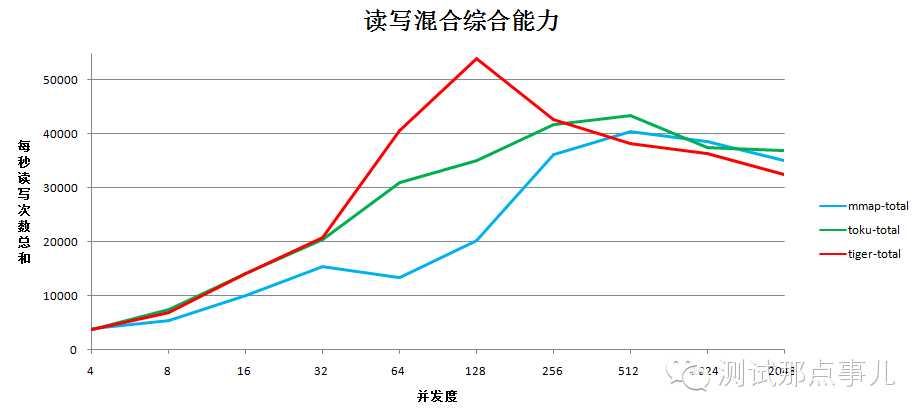
读写混合模式下,WiredTiger在32到256之间的并发情况下,综合能力优于toku和mmap,其他并发度情况下读写综合能力相近
小结
由测试结果可以看出,3.0的WT引擎对多并发更新的场景明显好于其他两种引擎,TPS性能有较大的提升,因此建议线上升级3.0并且更换存储引擎。
目前线上已经在测试环境部署了3.0的数据库,等待应用反馈回归测试结果,如果一切顺利,打算尽快升级
原创文章
禁止其他公众账号转载
标签:函数 letter ssi max add get 使用 公众账号 应该
原文地址:http://www.cnblogs.com/andashu/p/6441533.html