标签:wait idt xhtml 保护 官方网站 class raw 成功 date
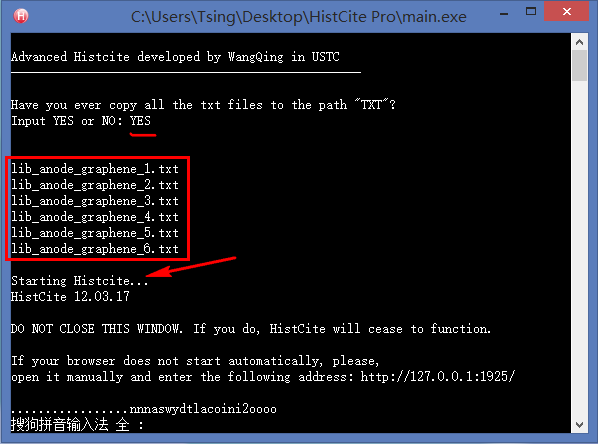
0. 制作引文分析利器HistCite的便捷使用版本
对于整天和文献打交道的研究生来说,HistCite是一款不可多得的效率利器,它可以快速绘制出某个研究领域的发展脉络,快速锁定某个研究方向的重要文献和学术大牛,还可以找到某些具有开创性成果的无指定关键词的论文。但是原生的HistCite已经有4年没有更新了,现在使用会出现各种bug,于是我就用Python基于HistCite内核开发了一个方便使用的免安装版本。具体的使用方法和下载链接见我的第一篇知乎专栏文章:文献引文分析利器HistCite使用教程(附精简易用免安装Pro版本下载) - Tsing的文章 - 知乎专栏
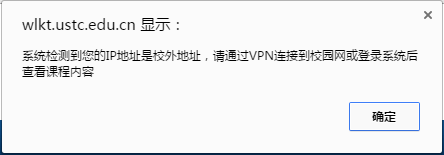
1. 破解观看中科大网络课堂
中国科学技术大学网络课堂(http://wlkt.ustc.edu.cn/

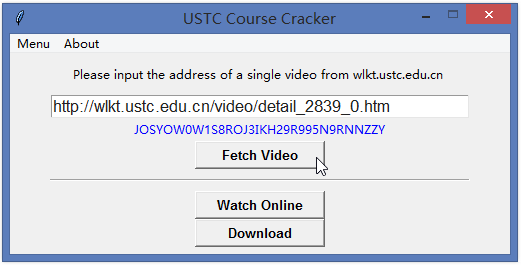
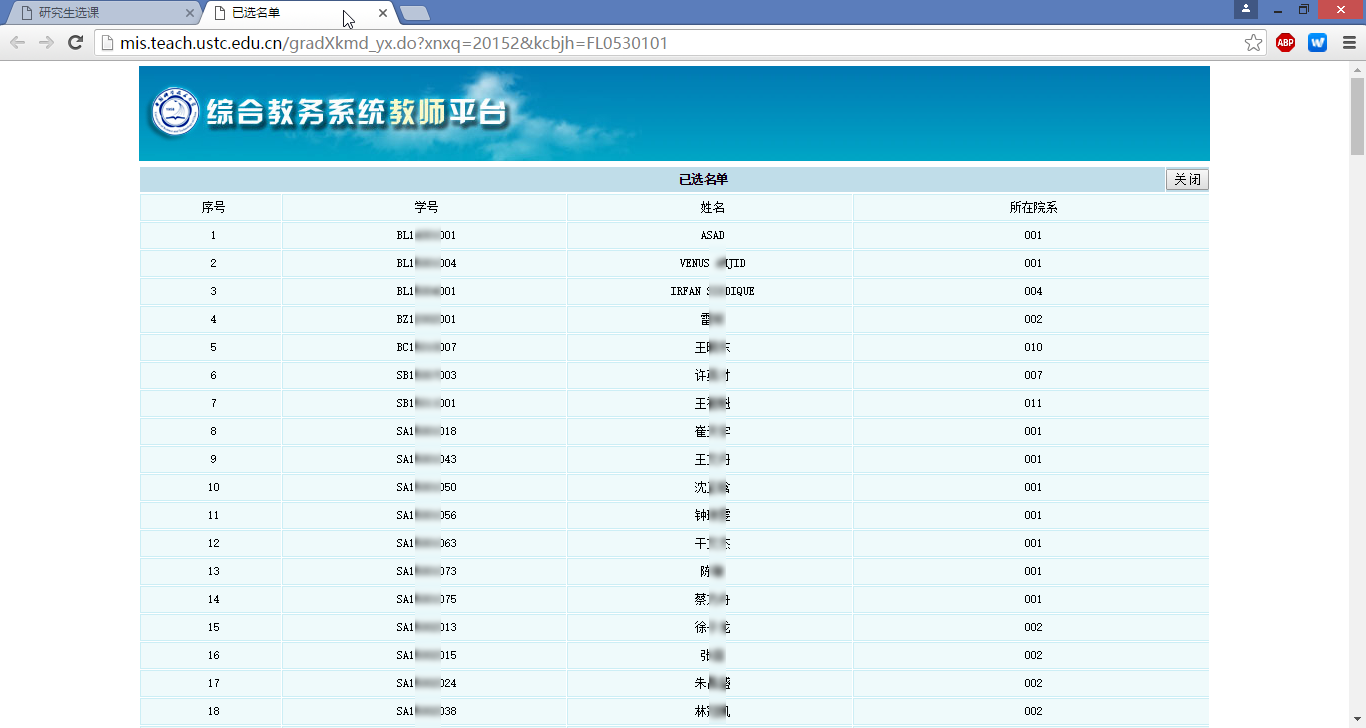
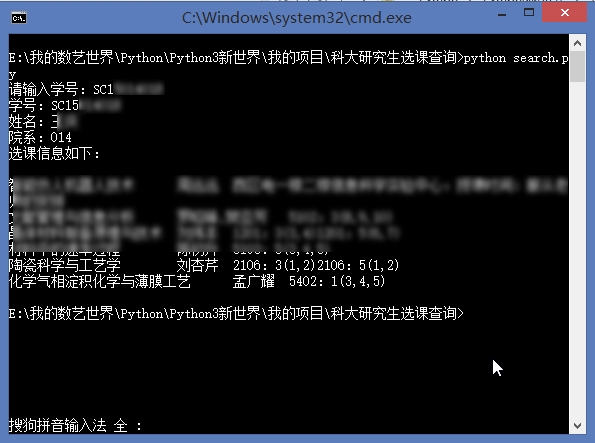
2. 获取中科大研究生系统全部学生姓名、学号、选课信息
登录中国科学技术大学的研究生综合系统(中国科学技术大学研究生信息平台



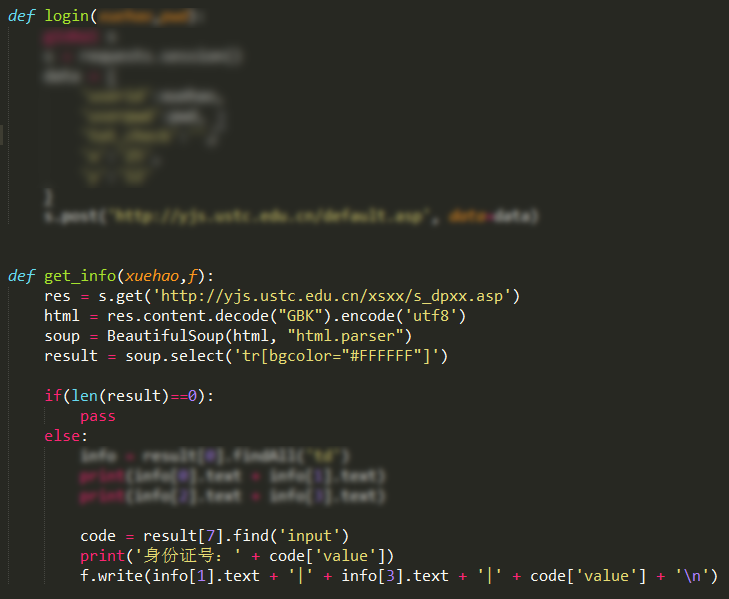
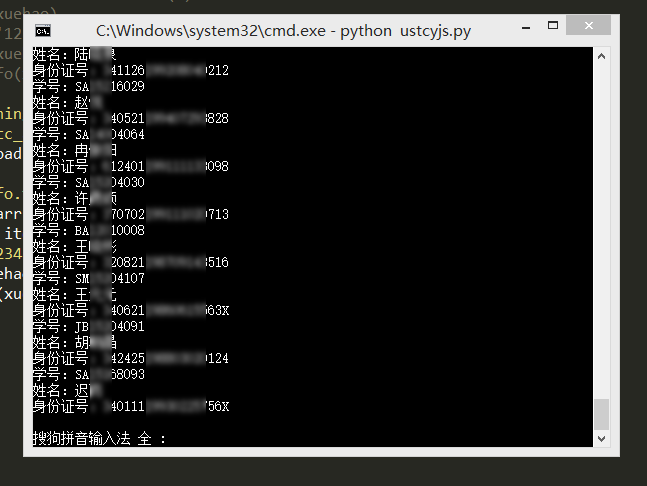
3. 扫描中科大研究生系统上的弱密码用户
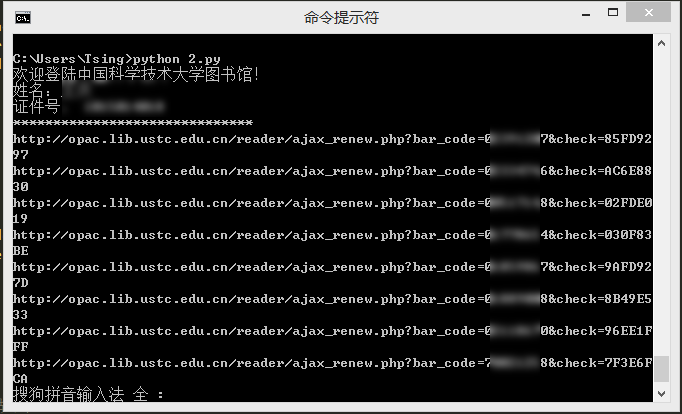
4. 模拟登录中科大图书馆并自动续借

5. 网易云音乐批量下载
# 网易云音乐批量下载# By Tsing# Python3.4.4importrequestsimporturllib# 榜单歌曲批量下载# r = requests.get(‘http://music.163.com/api/playlist/detail?id=2884035‘) # 网易原创歌曲榜# r = requests.get(‘http://music.163.com/api/playlist/detail?id=19723756‘) # 云音乐飙升榜# r = requests.get(‘http://music.163.com/api/playlist/detail?id=3778678‘) # 云音乐热歌榜r=requests.get(‘http://music.163.com/api/playlist/detail?id=3779629‘)# 云音乐新歌榜# 歌单歌曲批量下载# r = requests.get(‘http://music.163.com/api/playlist/detail?id=123415635‘) # 云音乐歌单——【华语】中国风的韵律,中国人的印记# r = requests.get(‘http://music.163.com/api/playlist/detail?id=122732380‘) # 云音乐歌单——那不是爱,只是寂寞说的谎arr=r.json()[‘result‘][‘tracks‘]# 共有100首歌foriinrange(10):# 输入要下载音乐的数量,1到100。name=str(i+1)+‘ ‘+arr[i][‘name‘]+‘.mp3‘link=arr[i][‘mp3Url‘]urllib.request.urlretrieve(link,‘网易云音乐\\‘+name)# 提前要创建文件夹print(name+‘ 下载完成‘)
上面这些都是在Python3的环境下完成的,在此之前,用Python2还写了一些程序,下面也放几个吧。初期代码可能显得有些幼稚,请大神见谅。
6. 批量下载读者杂志某一期的全部文章
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 保存读者杂志某一期的全部文章为TXT
# By Tsing
# Python 2.7.9
import urllib2
import os
from bs4 import BeautifulSoup
def urlBS(url):
response = urllib2.urlopen(url)
html = response.read()
soup = BeautifulSoup(html)
return soup
def main(url):
soup = urlBS(url)
link = soup.select(‘.booklist a‘)
path = os.getcwd()+u‘/读者文章保存/‘
if not os.path.isdir(path):
os.mkdir(path)
for item in link:
newurl = baseurl + item[‘href‘]
result = urlBS(newurl)
title = result.find("h1").string
writer = result.find(id="pub_date").string.strip()
filename = path + title + ‘.txt‘
print filename.encode("gbk")
new=open(filename,"w")
new.write("<<" + title.encode("gbk") + ">>\n\n")
new.write(writer.encode("gbk")+"\n\n")
text = result.select(‘.blkContainerSblkCon p‘)
for p in text:
context = p.text
new.write(context.encode("gbk"))
new.close()
if __name__ == ‘__main__‘:
time = ‘2015_03‘
baseurl = ‘http://www.52duzhe.com/‘ + time +‘/‘
firsturl = baseurl + ‘index.html‘
main(firsturl)
7. 获取城市PM2.5浓度和排名
#!/usr/bin/env python# -*- coding: utf-8 -*-# 获取城市PM2.5浓度和排名# By Tsing# Python 2.7.9importurllib2importthreadingfromtimeimportctimefrombs4importBeautifulSoupdefgetPM25(cityname):site=‘http://www.pm25.com/‘+cityname+‘.html‘html=urllib2.urlopen(site)soup=BeautifulSoup(html)city=soup.find(class_=‘bi_loaction_city‘)# 城市名称aqi=soup.find("a",{"class","bi_aqiarea_num"})# AQI指数quality=soup.select(".bi_aqiarea_right span")# 空气质量等级result=soup.find("div",class_=‘bi_aqiarea_bottom‘)# 空气质量描述printcity.text+u‘AQI指数:‘+aqi.text+u‘\n空气质量:‘+quality[0].text+result.textprint‘*‘*20+ctime()+‘*‘*20defone_thread():# 单线程print‘One_thread Start: ‘+ctime()+‘\n‘getPM25(‘hefei‘)getPM25(‘shanghai‘)deftwo_thread():# 多线程print‘Two_thread Start: ‘+ctime()+‘\n‘threads=[]t1=threading.Thread(target=getPM25,args=(‘hefei‘,))threads.append(t1)t2=threading.Thread(target=getPM25,args=(‘shanghai‘,))threads.append(t2)fortinthreads:# t.setDaemon(True)t.start()if__name__==‘__main__‘:one_thread()print‘\n‘*2two_thread()8. 爬取易迅网商品价格信息
#!/usr/bin/env python
#coding:utf-8
# 根据易迅网的商品ID,爬取商品价格信息。
# By Tsing
# Python 2.7.9
import urllib2
from bs4 import BeautifulSoup
def get_yixun(id):
price_origin,price_sale = ‘0‘,‘0‘
url = ‘http://item.yixun.com/item-‘ + id + ‘.html‘
html = urllib2.urlopen(url).read().decode(‘utf-8‘)
soup = BeautifulSoup(html)
title = unicode(soup.title.text.strip().strip(u‘【价格_报价_图片_行情】-易迅网‘).replace(u‘】‘,‘‘)).encode(‘utf-8‘).decode(‘utf-8‘)
print title
try:
soup_origin = soup.find("dl", { "class" : "xbase_item xprice xprice_origin" })
price_origin = soup_origin.find("span", { "class" : "mod_price xprice_val" }).contents[1].text
print u‘原价:‘ + price_origin
except:
pass
try:
soup_sale= soup.find(‘dl‘,{‘class‘:‘xbase_item xprice‘})
price_sale = soup_sale.find("span", { "class" : "mod_price xprice_val" }).contents[1]
print u‘现价:‘+ price_sale
except:
pass
print url
return None
if __name__ == ‘__main__‘:
get_yixun(‘2189654‘)
9. 音悦台MV免积分下载
#!/usr/bin/env python# -*- coding: utf-8 -*-# 音悦台MV免积分下载# By Tsing# Python 2.7.9importurllib2importurllibimportremv_id=‘2278607‘# 这里输入mv的id,即http://v.yinyuetai.com/video/2275893最后的数字url="http://www.yinyuetai.com/insite/get-video-info?flex=true&videoId="+mv_idtimeout=30headers={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36‘,‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8‘}req=urllib2.Request(url,None,headers)res=urllib2.urlopen(req,None,timeout)html=res.read()reg=r"http://\w*?\.yinyuetai\.com/uploads/videos/common/.*?(?=&br)"pattern=re.compile(reg)findList=re.findall(pattern,html)# 找到mv所有版本的下载链接iflen(findList)>=3:mvurl=findList[2]# 含有流畅、高清、超清三个版本时下载超清else:mvurl=findList[0]# 版本少时下载流畅视频local=‘MV.flv‘try:print‘downloading...please wait...‘urllib.urlretrieve(mvurl,local)print"[:)] Great! The mv has been downloaded.\n"except:print"[:(] Sorry! The action is failed.\n"10. 其他请参考:能利用爬虫技术做到哪些很酷很有趣很有用的事情? - Tsing 的回答
结语:Python是一个利器,而我用到的肯定也只是皮毛,写过的程序多多少少也有点相似,但是我对Python的爱却是越来越浓的。
补充:看到评论中有好多知友问哪里可以快速而全面地学习Python编程,我只给大家推荐一个博客,大家认真看就够了:Python教程 - 廖雪峰的官方网站
标签:wait idt xhtml 保护 官方网站 class raw 成功 date
原文地址:http://www.cnblogs.com/kaywu/p/6490966.html