3. java代码实现思路
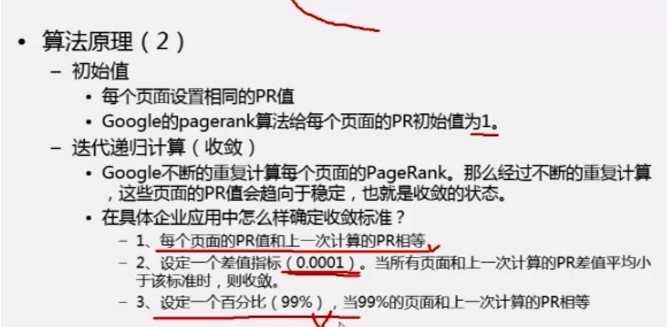
1、定义收敛标准
每次算出新的pr-oldpr=差值 ,所有页面的差值累加 ,除以pagecount,得到avg差值 ,如果。小于0.01
2、计算总页面数,并且算出每个页面的初始pr值=1/pagecount
3、
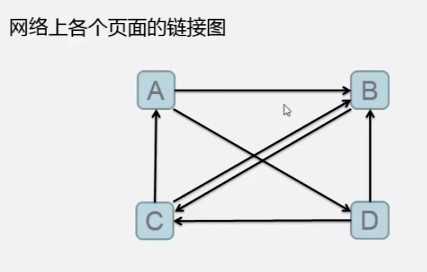
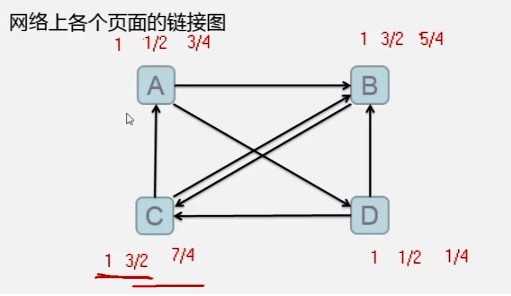
A 0.25 B D ----- A 0.35 B D--- A 0.29 B D----
数据集:
一个MapReduce(如何做到循环)
1. Job的设计
定义一个收敛值d=0.01,一直循环进行MapReduce操作,当所有页面和上一次计算的pr差值平均小于该标准时,则收敛,跳出循环
boolean flag = job.waitForCompletion(true);if(flag){System.out.println(job.getJobName()+" run success");//获取计数器中的差值long sum = job.getCounters().findCounter(Mycounter.my).getValue();System.out.println("SUM: "+ sum);double avg = sum /4000.0;if(avg < d){//满足设定的值,跳出循环break;}}
统计计算的次数i,conf.setInt("runCount", i);便于从上一次的输出中读取数据
inputPath和outputPath的设计
Path inputPath =newPath("/user/pagerank/input/pagerank.txt");//如果不是是第一次计算if(i >1){ inputPath =newPath("/user/pagerank/output/pr"+(i-1));}FileInputFormat.addInputPath(job, inputPath);Path outputPath =newPath("/user/pagerank/output/pr"+ i);FileSystem fs =FileSystem.get(conf);if(fs.exists(outputPath)){ fs.delete(outputPath,true);}FileOutputFormat.setOutputPath(job, outputPath);
2. Mapper的设计
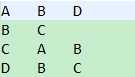
Mapper端数据的输入--key:Text value:Text key:A value:B D
(job端在进行Mapper操作之前,将数据进行了格式处理job.setInputFormatClass(KeyValueTextInputFormat.class);key,value转化为Text格式)
步骤一:获取运行的次数,判断是否是第一次进行map操作,如果是第一次,赋予1.0默认值,然后将value(1.0 B D)封装为Node对象
步骤二:将计算前的数据进行输出,key:A value:1.0 B D context.write(new Text(page),new Text(node.toString())
步骤三:如果网页有出链,计算对当前page,对其他网页的出链值key:B value:0.5 || key:D value:0.5
Mapper端数据的输出:
第一种--key:A value:1.0 B D
第二种--key:B value:0.5 || key:D value:0.5
3. Reducer的设计
Reducer端数据的输入--第一种--key:A value:1.0 B D 第二种--key:A value:0.5 || key:A value:0.75
步骤一:遍历Iterable<Text>对象,里面有两种数据(value:1.0 B D || value:0.5)
无论哪种数据,首先将value转化为Node对象,其次,如果是前者将该node定义为上次的node(sourceNode),否则,获取该node的pageRank(其他网页对该page的投票值),进行sum累加(sum的最终结果也就是本次计算其他page对当前page的投票值总和),比如页面A本次一共获得1.25来自于其他页面的投票
步骤二:计算新的pr值double newPR = (0.15 / 4.0) + (0.85 * sum);并与之前的也就是上一次的pr值进行比较(上一次的pr值存放在sourceNode中)double d = newPR - sourceNode.getPageRank(); 将差值结果放到累加器中
context.getCounter(Mycounter.my).increment(j);
步骤三:更新page上一次的pr值--sourceNode.setPageRank(newPR);
步骤四:数据输出,key:A value:1.25 B D--context.write(key, new Text(sourceNode.toString()));