标签:transient family 大学 一点 http number 程序 散列表 没有
o( ̄▽ ̄)d
小伙伴们在上网或者搞程序设计的时候,总是会听到关于“哈希(hash)”的一些东西。比如哈希算法、哈希表等等的名词,那么什么是hash呢?
一.相关概念
1.hash算法:一类特殊的算法(注意哦,hash算法并不是某个固定的算法,而是一类特殊功能算法的统称)。
2.哈希表(hash table)、哈希映射(hash map)、哈希集合(hash set):一种基于hash算法的数据结构。
3.哈希函数:在hash算法中的核心函数。
4.map:译为“映射”,是一种从键(key)到值(value)的对应关系。
5.消息摘要:又叫“数字摘要”、“数字指纹”,类似于文章的梗概,或者人的指纹,是一个唯一对应一段信息的值。
二.hash算法
(一).hash算法是什么?
第一步,我们先去查查字典,看看hash是啥意思。
hash
英 [hæ?] 美 [hæ?]
n.剁碎的食物;#号;蔬菜肉丁
vt.把…弄乱;切碎;反复推敲;搞糟
差不多就是“切碎”的意思,“哈希”又叫“散列”。(这里就想吐槽一下,起这么多小名干嘛,名字不重要......)
第二步,我们去查查百科。
Hash算法可以接受任意长度字节的输入值,并经过复杂运算,给出固定长度的输出值。
从这里我们可以看出,只要一个算法符合上面的特征,就可以称其为“hash算法”。Hash算法产生“数字摘要”:也就是说,从不同的输入中,通过一些计算摘取出来一段输出数据,值可以用以区分输入数据。
(二).hash算法到底有什么用处呢?
1.在信息安全方面
Hash算法可用作加密算法。
2.在数据结构方面
Hash算法可用作快速查找。
在数据结构领域,有一种哈希表(hash table)的结构,正是利用了hash算法的特性,实现了以常数平均时间执行插入、删除和查找。这个也是接下来讨论的重点。
三.哈希/散列表
原则上来说,计算机中最基本的数据结构只有两种:数组(连续型)和链表(离散型)。其它诸如堆、栈、树、表等都是数组与链表的特殊实现。也就是说,把数组和链表经过特殊处理(这个过程可以叫做“封装”),就产生了其他的“高级数据结构类型”。哈希表也是其中一种。或者换一种说法,堆、栈、树等都是逻辑结构,而连续存储和离散存储是在物理方面的结构。
我们分析一下传统的查找模式。比如我们建立了一个“查找树”。当我们在查找时,会从根节点“逐一比较”,查找的效率依赖于查找的次数。
~哈希表
一种最理想的情况是不需要做任何比较,一次存取就能得到想要的记录。那就必须在记录的存储位置和它的关键字之间建立一个确定的关系h,使每个关键字和结构中一个唯一的存储位置相对应。因而在查找时,只要根据这个对应关系h找到给定值K的像h(K)。若结构中存在关键字和K相等的记录,则必定在h(K)的存储位置上,反之在这个位置上没有记录。由此,不需要比较便可直接取得所查记录。在此,我们称这个对应关系h为哈希(Hash)函数 ,按这个思想建立的表为哈希表 。
~哈希函数
1.灵活性
哈希函数是一种映像关系,说的通俗一点,就是一种对应关系。因此只要得到的哈希值在表允许的范围内就可以。
2.冲突
对不同的关键字可能得到同一哈希地址,即key1≠key2,而h(key1)=h(key2) ,这种现象称为冲突(collision)。
很遗憾,冲突是不可避免的。上面我们说,哈希函数是关键字到地址集合的映射。关键字可以在格式允许的范围内任意取,但是我们内存的地址集合是有限的。从大范围到小范围,所以冲突不可避免。但是我们可以设法减小冲突的概率。因此单单一个合适的哈希函数是不够的,还要有一个良好的解决冲突的方法。
由此我们得到了哈希表的两个关键:哈希函数以及解决冲突的方法。
综上,我们可以得到哈希表的一个定义:
根据设定的Hash函数 - H(key)和处理冲突的方法,将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的象作为记录在表中的存储位置,这样的表便称为Hash表 。
四.java中的HashMap
1.FAQ
问:为什么有HashMap?
答:HashMap利用hash算法实现了快速存取的特性。
问:hash表和HashMap有什么关系?
答:Hash表 是一种逻辑数据结构,HashMap是Java中的一种数据类型(结构类型),它通过代码实现了Hash表 这种数据结构,并在此结构上定义了一系列操作。
2.上帝视角的HashMap
基本上HashMap就像这样:
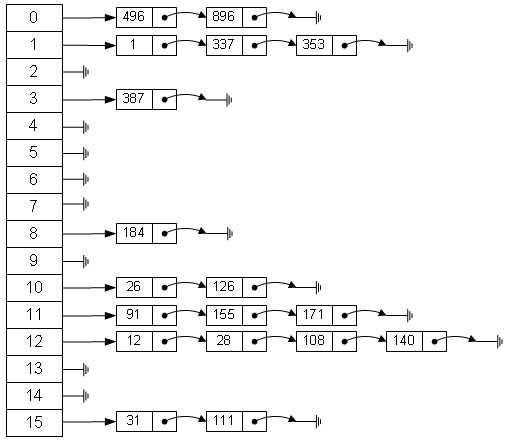
3.实现一个new HashMap

1 /*** 1. 构造方法:最终使用的是这个构造方法 ***/ 2 // 初始容量initialCapacity为16,装填因子loadFactor为0.75 3 public HashMap(int initialCapacity, float loadFactor) { 4 if (initialCapacity < 0) 5 throw new IllegalArgumentException("Illegal initial capacity: " + 6 initialCapacity); 7 if (initialCapacity > MAXIMUM_CAPACITY) 8 initialCapacity = MAXIMUM_CAPACITY; 9 if (loadFactor <= 0 || Float.isNaN(loadFactor)) 10 throw new IllegalArgumentException("Illegal load factor: " + 11 loadFactor); 12 13 this.loadFactor = loadFactor; 14 threshold = initialCapacity; 15 init();//init可以忽略,方法默认为空{},当你需要集成HashMap实现自己的类型时可以重写此方法做一些事 16 } 17 18 /*** 2. (静态/实例)成员变量 ***/ 19 /** 默认的容量,容量必须是2的幂 */ 20 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 21 /** 最大容量2的30次方 */ 22 static final int MAXIMUM_CAPACITY = 1 << 30; 23 /** 默认装填因子0.75 */ 24 static final float DEFAULT_LOAD_FACTOR = 0.75f; 25 /** 默认Entry数组 */ 26 static final Entry<?,?>[] EMPTY_TABLE = {}; 27 28 /** Entry数组:table */ 29 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; 30 31 /** table中实际的Entry数量 */ 32 transient int size; 33 34 /** 35 * size到达此门槛后,必须扩容table; 36 * 值为capacity * load factor,默认为16 * 0.75 也就是12。 37 * 意味着默认情况构造情况下,当你存够12个时,table会第一次扩容 38 */ 39 int threshold; 40 41 /** 装填因子,值从一开构造HashMap时就被确定了,默认为0.75 */ 42 final float loadFactor; 43 44 /** 45 * 哈希种子,实例化HashMap后在将要使用前设置的随机值,可以使得key的hashCode冲突更难出现 46 */ 47 transient int hashSeed = 0; 48 49 /** 50 * The number of times this HashMap has been structurally modified 51 * Structural modifications are those that change the number of mappings in 52 * the HashMap or otherwise modify its internal structure (e.g., 53 * rehash). This field is used to make iterators on Collection-views of 54 * the HashMap fail-fast. (See ConcurrentModificationException). 55 */ 56 transient int modCount; 57 58 /*** 3. Map.Entry<K,V>:数组table中实际存储的类型 ***/ 59 static class Entry<K,V> implements Map.Entry<K,V> { 60 final K key; // "Key-Value对"的Key 61 V value; // "Key-Value对"的Value 62 Entry<K,V> next; 63 int hash; 64 65 Entry(int h, K k, V v, Entry<K,V> n) { 66 value = v; 67 next = n;//链表的下一个Entry 68 key = k; 69 hash = h; 70 } 71 public final int hashCode() { 72 return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue()); 73 } 74 }
4.存 - put(key, value)、解决冲突
1 /** 存放 **/ 2 public V put(K key, V value) { 3 if (table == EMPTY_TABLE) { 4 inflateTable(threshold);//table会被初始化为长度16,且hashSeed会被赋值; 5 } 6 if (key == null) 7 //HashMap允许key为null:在table中找到null key,然后设置Value,同时其hash为0; 8 return putForNullKey(value); 9 10 // a). 计算key的hashCode,下面详细说 11 int hash = hash(key); 12 13 // b). 根据hashCode计算index 14 int i = indexFor(hash, table.length); 15 16 // c). 覆盖(如是相同Key则覆盖Value,注意这里不是解决冲突): 17 // 遍历index位置的Entry链表,如果链表中Entry的hash相等且== || equals则认为是同一个key,所以覆盖value 18 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 19 Object k; 20 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 21 V oldValue = e.value; 22 e.value = value; 23 e.recordAccess(this); 24 return oldValue; 25 } 26 } 27 28 modCount++; 29 // d). 正常添加Entry,如果需要增加table长度(size>threshold)就乘2增加,并重新计算每个元素在新table中的位置和转移 30 addEntry(hash, key, value, i); 31 return null;//增加成功最后返回null 32 } 33 34 35 //详细说说上面的a). b). d). 36 37 /** a). 为了防止低质量的hash函数,HashMap在这里会重新计算一遍key的hashCode **/ 38 final int hash(Object k) { 39 int h = hashSeed; 40 if (0 != h && k instanceof String) {//字符串会被特殊处理,返回32bit的整数(就是int) 41 return sun.misc.Hashing.stringHash32((String) k); 42 } 43 44 h ^= k.hashCode();//将key的hashCode与h按位异或,最后赋值给h 45 46 // This function ensures that hashCodes that differ only by 47 // constant multiples at each bit position have a bounded 48 // number of collisions (approximately 8 at default load factor). 49 h ^= (h >>> 20) ^ (h >>> 12); 50 return h ^ (h >>> 7) ^ (h >>> 4); 51 } 52 53 /** 54 * b). 计算此hashCode该被放入table的哪个index 55 */ 56 static int indexFor(int h, int length) { 57 return h & (length-1);//与table的length - 1按位与,就能保证返回结果在0-length-1内 58 } 59 60 /** 61 * 解决冲突:链地址法 62 * d). addEntry(hash, key, value, i)最终是调用了此函数 63 */ 64 void createEntry(int hash, K key, V value, int bucketIndex) { 65 Entry<K,V> e = table[bucketIndex];//首先table中此index的Entry拿出来 66 // 在构造函数中,e代表next。 67 // 即如果e是null,那正好设置next为null,否则将原有的Entry设置为next,新建的Entry放在此位置 68 // 也就是说这里用链地址法解决冲突时,会将原有元素放入链尾,新元素放在链头 69 table[bucketIndex] = new Entry<>(hash, key, value, e); 70 size++; 71 }
5.取-get(key)
1 //其实看完了最精髓的存,取的话就比较简单,就不放代码在这里了,仅说下思路。 2 3 // 1. 根据k使用hash(k)重新计算出hashCode 4 // 2. 根据indexFor(int h, int length)计算出该k的index 5 // 3. 如果该index处Entry的key与此k相等,就返回value,否则继续查看该Entry的next
五.Java中的equals()与hashCode()比较
Java中Object类有两个方法,都是有关于“相同”的概念。
在上面对于hash函数的讨论中,我们知道对于相同的key必须得到同一个hashCode。
但是在Java中,相同有两个概念,一个是“同一个”,另一个是“相等”。
从上面我们可以看出,HashMap设计选择了equals()。
此时,也许你就能明白为什么Object的
HashCode()方法说:相等的对象必须有相等的哈希值。
Equals()方法说:覆盖此方法,通常由必要重写hashCode()方法,以维护其general contract。
原因:
1. Object的equals()方法开始看,此方法默认使用==进行判断;还要知道,hashCode()是native方法,即它是依赖C语言算出来的。
2. 我们可以观察一下HashMap的put(key)操作,它首先进行的是判断相等的key就覆盖的操作,也就是使用了key的equals()方法,在这种情况下,如果 你自己的类覆盖了euqals()方法而没有管hashCode()方法,那么,在put(key)方法中,依赖hashCode计算出index这一步,就会将原本equals()的对象放在 不同index中,这样接下来的覆盖操作就不会起作用了。造成的结果是,相等的对象被放入了不同index位置,而不是覆盖。
所以我们要避免出现这类问题,在改写equals()的同时也要改写hashCode()。我们可以去看官方给出的API文档,就很好地遵循了这一准则。
OK,在这一篇中我们分析了hash算法的构造以及java包中实现的hashmap功能,在下一篇我们会给出一些hash表中的hash函数实现方法和解决“冲突”的方法。
参考:【1】哈希表、Java中HashMap
【2】严蔚敏,吴伟民.数据结构(C语言版).北京:清华大学出版社,2007
【3】 HashMap深度解析(一)
标签:transient family 大学 一点 http number 程序 散列表 没有
原文地址:http://www.cnblogs.com/yuxiuyan/p/6498352.html
