标签:topic 部分 mode 环境 self pen 域名 body computers
用Scrapy做爬虫分为四步
上一章节做了创建项目,接着用上一次创建的项目来爬取网页
网上很多教程都是用的dmoz.org这个网站来做实验,所以我也用这个来做了实验
在Scrapy中,items是用来加载抓取内容的容器
我们想要的内容是
在tutorial目录下会有items.py文件,在默认的代码后面添加上我们的代码
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy.item import Item, Field import scrapy class TutorialItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field()
#下面是我自己加的 class DmozItem(Item): title = Field() link = Field() desc = Field()
爬虫还是老规矩,先爬再取。也就是说先获取整个网页的内容,然后取出你需要的部分
在tutorial\spiders目录下建立python文件,命名为dmoz_spider.py
目前的代码如下
from scrapy.spiders import Spider class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls= [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self,response): filename=response.url.split("/")[-2] open(filename,‘wb‘).write(response.body)
name是爬虫的名字,必须唯一
allowed_domains是爬取的限制范围,意思只爬取该域名下的内容
start_urls是爬取的url列表,子URLl将会从这些起始URL中继承性生成
parse大概可以理解为对response的预处理
好啦,爬虫写好了,然后运行,在tutorial目录下打开cmd窗口
输入
scrapy crawl dmoz
哦豁,报错了
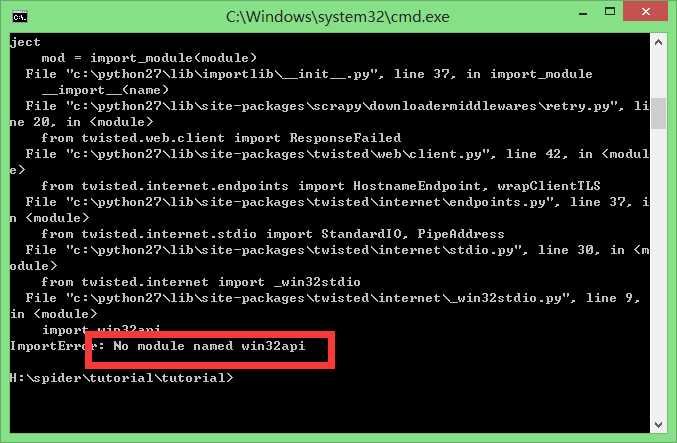
娘度了下,是因为没有win32api这个模块
我用的是python2.7 32位,所以下载pywin32-219.win32-py2.7.exe这个文件
记得不要下错了,分32位和64位的,下载成64位的话会继续报
dll load failed: 1% 不是有效的win32的
错误
配置好环境后,重新运行
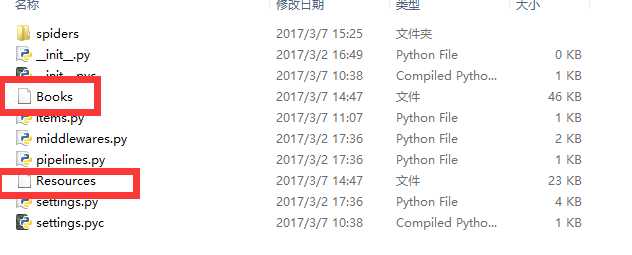
成功
tutorial目录下多了book和Resources两个文件,这就是爬取下来的文件
标签:topic 部分 mode 环境 self pen 域名 body computers
原文地址:http://www.cnblogs.com/ronyjay/p/6515934.html