标签:结构化 address 支持 ted 字符 后缀 student pat 使用
(一) XML概念
在电子计算机中,标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种的信息比如文章等。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 它非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是Internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。早在1998年,W3C就发布了XML1.0规范,使用它来简化Internet的文档信息传输。
(二)XML作用
1. 描述带关系的数据(常用做软件的配置文件):描述包含于被包含的关系,适用范围非常广泛,比如 tomcat SSH框架全部都使用到了XML
例如配置主机和端口号:
1 host.xml 2 <host> 3 <ip>255.43.12.55</ip> 4 <port>1521</port> 5 </host>
2. 作为数据的载体(存储数据,小型的“数据库”)
例如存储信息:
1 teacher.xml 2 <teacher> 3 <name>张三</name> 4 <email>zhangsan@qq.com</email> 5 <workage>2</workage> 6 </teacher>
(三)XML语法
xml文件以xml后缀名结尾。
xml文件需要使用xml解析器去解析。浏览器内置了xml解析器
语法: <student></student> 开始标签 标签体内容 结束标签
1)<student/> 或 <student></student> 空标签。没有标签体内容
2)xml标签名称区分大小写。
3)xml标签一定要正确配对。
4)xml标签名中间不能使用空格
5)xml标签名不能以数字开头
6)注意: 在一个xml文档中,有且仅有一个根标签
语法: <Student name="eric">student</Student>
注意:
1)属性值必须以引号包含,不能省略,也不能单双引号混用!
2)一个标签内可以有多个属性,但不能出现重复的属性名!
在xml中内置了一些特殊字符,这些特殊字符不能直接被浏览器原样输出。如果希望把这些特殊字符按照原样输出到浏览器,对这些特殊字符进行转义。转义之后的字符就叫转义字节。
特殊字符 转义字符
< <
> >
" "
& &
空格 &nsbp;
(四) XML的DOM解析:
XML文档除了需要供开发者来阅读、配置相关信息,还需要让程序能够读懂其中包含的信息,这就叫做XML文档的解析。
其中XML文档主要有两种解析方式,DOM解析和SAX解析,这里我们主要讲DOM解析方式,而这种方式也是SSH三大框架的解析XML的方式。
4.1 DOM解析:
DOM解析原理:xml解析器一次性把整个xml文档加载进内存,然后在内存中构建一颗Document的对象树,通过Document对象,得到树上的节点对象,通过节点对象访问(操作)到xml文档的内容。
Document对象代表了一个完整的xml文档,通过Document对象,可以得到其下面的其他节点对象,通过各个节点对象来访问xml文档的内容。
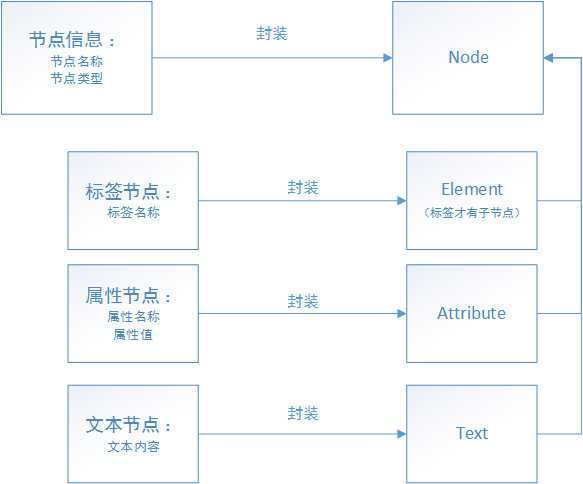
其中主要包括:标签节点,属性节点,文本节点和注释节点;并且各类节点也被封装成对应的对象,通过操作不同的对象来访问xml的内容:
树只有一个根标签,树上的分支叫做节点(node)
4.2 Domj4读取xml文件
首先创建xml解析器对象,获取到Document对象:
1 public static Document getDocument(){ 2 3 //创建一个XML解析器 4 SAXReader saxReader = new SAXReader(); 5 try { 6 //读取Document对象 7 Document document = null; 8 document = saxReader.read("./src/xml/User.xml"); 9 return document; 10 } catch (DocumentException e) { 11 e.printStackTrace(); 12 } 13 return null; 14 }
节点:
Iterator Element.nodeIterator(); //获取当前标签节点下的所有子节点
标签:
Element Document.getRootElement(); //获取xml文档的根标签
Element ELement.element("标签名") //指定名称的第一个子标签
Iterator<Element> Element.elementIterator("标签名");// 指定名称的所有子标签
List<Element> Element.elements(); //获取所有子标签
代码示例:
1 /** 2 * 遍历所有的标签节点 3 * @param document 4 */ 5 public static void gerAll(Document document){ 6 7 //获取XML文档的根标签 8 Element rootElement = document.getRootElement(); 9 getChildNodes(rootElement); 10 } 11 12 /** 13 * 递归获取传入标签下的所有子节点 14 * @param element 15 */ 16 public static void getChildNodes(Element element){ 17 System.out.println(element.getName()); 18 // 迭代器获取当前节点下的所有子节点 19 Iterator<Node> it = element.nodeIterator(); 20 while (it.hasNext()){ 21 Node node = it.next(); 22 //1 判断是否是标签 23 if (node instanceof Element){ 24 //如果仍然是标签节点,那个递归获取子节点 25 getChildNodes((Element) node); 26 } 27 28 } 29 } 30 31 32 /** 33 * 获取当前标签的指定名称的第一个子标签 34 * @param element 当前标签 35 */ 36 public static Element getElementByName(Element element, String elemName){ 37 38 //获取当前标签下的指定名称的第一个子标签 39 Element elem = element.element(elemName); 40 System.out.println(elem.getName()); 41 return elem; 42 } 43 44 /** 45 * 获取当前标签下指定名称的所有子标签 46 * @param element 当前标签 47 * @param elemName 指定的名称 48 */ 49 public static Iterator<Element> getElementsByName(Element element, String elemName){ 50 51 //获取当前标签下的指定名称的所有子标签 52 Iterator<Element> itElement = element.elementIterator(elemName); 53 while (itElement.hasNext()){ 54 Element elem = itElement.next(); 55 System.out.println(elem.getName()); 56 } 57 return itElement; 58 } 59 60 /** 61 * 获取当前标签下所有子标签 62 * @param element 当前标签 63 */ 64 public static List<Element> getElements(Element element){ 65 66 //获取当前标签下的指定名称的所有子标签 67 List<Element> elementList = element.elements(); 68 for (Element elem : elementList) { 69 System.out.println(elem.getName()); 70 } 71 72 return elementList; 73 }
属性:
String Element.attributeValue("属性名") //获取指定名称的属性值
Attribute Element.attribute("属性名");//获取指定名称的属性对象
Attribute.getName() //获取属性名称
Attibute.getValue() //获取属性值
List<Attribute> Element.attributes(); //获取所有属性对象
Iterator<Attribute> Element.attibuteIterator(); //获取所有属性对象
代码示例:
1 /** 2 * 获取属性信息 3 */ 4 5 6 /** 7 * 根据属性名称获取指定的属性 和属性值 8 * @param element 所在标签节点 9 * @param attName 属性名 10 */ 11 public static void getAttributeByName(Element element,String attName){ 12 13 //想要获取属性,首先要获取属性所在的标签 即传入的标签 14 15 // 直接根据id获取属性值 16 element.attributeValue(attName); 17 18 // 获取attribute对象,然后获取name和value值 19 Attribute attribute = element.attribute(attName); 20 String str = attribute.getName() + "=" + attribute.getValue(); 21 System.out.println(str); 22 } 23 24 public static void getAttributes(Element element){ 25 26 List<Attribute> attributeList = element.attributes(); 27 for (Attribute attribute : attributeList) { 28 System.out.println( attribute.getName() + "="+ attribute.getValue() ); 29 } 30 31 //Iterator<Attribute> itAttribute = element.attributeIterator(); 32 }
文本:
Element.getText(); //获取当前标签的文本
Element.elementText("标签名") //获取当前标签的指定名称的子标签的文本内容
代码示例:
1 /** 2 * 获取文本信息 3 */ 4 5 public static String getText(Element element){ 6 //注意:空格和换行也是xml的内容 7 String text = element.getText(); 8 return text; 9 }
4.3 Domj4修改xml文件
增加:
DocumentHelper.createDocument() 增加文档
addElement("名称") 增加标签
addAttribute("名称",“值”) 增加属性
代码示例:
1 /** 2 * 增加:文档,标签 ,属性 3 */ 4 @Test 5 public void AddNode() throws Exception{ 6 7 //创建文档 8 Document doc = DocumentHelper.createDocument(); 9 //增加标签 10 Element rootElem = doc.addElement("UserList"); 11 Element userElem = rootElem.addElement("User"); 12 userElem.addElement("username"); 13 //增加属性值 14 userElem.addAttribute("id", "001"); 15 userElem.addAttribute("username", "eric"); 16 17 writeXml(doc); 18 }
修改:
Attribute.setValue("值") 修改属性值
Element.addAtribute("同名的属性名","值") 修改同名的属性值
Element.setText("内容") 修改文本内容
代码示例:
1 /** 2 * 修改:属性值,文本 3 * @throws Exception 4 */ 5 @Test 6 public void updateNode() throws Exception{ 7 Document doc = new SAXReader().read(new File("./src/xml/userWrite.xml")); 8 9 /** 10 * 方案一: 修改属性值 1.得到标签对象 2.得到属性对象 3.修改属性值 11 */ 12 //1.1 得到标签对象 13 /* 14 Element userElem = doc.getRootElement().element("User"); 15 //1.2 得到属性值 16 Attribute idAttr = userElem.attribute("id"); 17 //1.3 修改属性值 18 idAttr.setValue("003"); 19 */ 20 /** 21 * 方案二: 修改属性值 22 */ 23 //1.1 得到标签对象 24 /* 25 Element userElem = doc.getRootElement().element("User"); 26 //1.2 通过增加同名属性的方法,修改属性值 27 userElem.addAttribute("id", "004"); 28 */ 29 30 /** 31 * 修改文本 1.得到标签对象 2.修改文本 32 */ 33 Element nameElem = doc.getRootElement().element("User").element("username"); 34 nameElem.setText("王五"); 35 36 //把修改后的Document对象写出到xml文档中 37 writeXml(doc); 38 }
删除
Element.detach(); 删除标签
Attribute.detach(); 删除属性
代码示例:
1 /** 2 * 删除:标签,属性 3 * @throws Exception 4 */ 5 @Test 6 public void deleteNode() throws Exception{ 7 Document doc = new SAXReader().read(new File("./src/xml/userWrite.xml")); 8 9 /** 10 * 1.删除标签 1.1 得到标签对象 1.2 删除标签对象 11 */ 12 // 1.1 得到标签对象 13 /* 14 Element ageElem = doc.getRootElement().element("User").element("age"); 15 //1.2 删除标签对象 16 ageElem.detach(); 17 //ageElem.getParent().remove(ageElem); 18 */ 19 /** 20 * 2.删除属性 2.1得到属性对象 2.2 删除属性 21 */ 22 //2.1 得到属性对象 23 //到第二个user标签 24 Element userElem = (Element)doc.getRootElement(). 25 elements().get(0); 26 //2.2 得到属性对象 27 Attribute idAttr = userElem.attribute("id"); 28 //2.3 删除属性 29 idAttr.detach(); 30 //idAttr.getParent().remove(idAttr); 31 32 writeXml(doc); 33 }
写出内容到xml文档
XMLWriter writer = new XMLWriter(OutputStream, OutputForamt)
wirter.write(Document);
代码示例:
1 /** 2 * 把修改后的Document对象写出到xml文档中 3 * @param document 4 * @throws IOException 5 */ 6 public void writeXml(Document document) throws IOException { 7 //把修改后的Document对象写出到xml文档中 8 FileOutputStream out = new FileOutputStream("./src/xml/userWrite.xml"); 9 //比较美观的排版方式 用于人阅读 10 OutputFormat format = OutputFormat.createPrettyPrint(); 11 12 //紧凑型的排版方式 ,主要用于程序运行中使用 减少不必要的空格换行等 13 //OutputFormat format2 = OutputFormat.createCompactFormat(); 14 15 format.setEncoding("utf-8"); 16 XMLWriter writer = new XMLWriter(out,format); 17 writer.write(document); 18 writer.close(); 19 20 }
其中使用的到xml文件:
1 <?xml version="1.0" encoding="utf-8"?> 2 3 <UserList> 4 <User id="001"> 5 <username>张三</username> 6 <passwprd>33333</passwprd> 7 <age>33</age> 8 <address>aaaaaaaa</address> 9 </User> 10 11 <User id="002"> 12 <username>李四</username> 13 <passwprd>44444</passwprd> 14 <age>44</age> 15 <address>bbbbbbbbb</address> 16 </User> 17 <abc></abc> 18 19 </UserList>
(五)xPath技术
5.1 引入
问题:当使用dom4j查询比较深的层次结构的节点(标签,属性,文本),比较麻烦!
5.2 xPath作用
主要是用于快速获取所需的节点对象。
5.3 在dom4j中如何使用xPath技术
1)导入xPath支持jar包 。 jaxen-1.1-beta-6.jar
2)使用xpath方法 :这里使用的是多态技术,因为不管是标签还是属性或者文本类型的对象都是节点对象
List<Node> selectNodes("xpath表达式"); 查询多个节点对象
Node selectSingleNode("xpath表达式"); 查询一个节点对象
5.4 xPath语法
| / | 绝对路径 | 表示从xml的根位置开始或子元素(一个层次结构) |
| // | 相对路径 | 表示不分任何层次结构的选择元素。 |
| * | 通配符 | 表示匹配所有元素 |
| [] | 条件 | 表示选择什么条件下的元素 |
| @ | 属性 | 表示选择属性节点 |
| and | 关系 | 表示条件的与关系(等价于&&) |
| text() | 文本 | 表示选择文本内容 |
语法示例:
|
/AAA |
|
选择根元素AAA |
|
|
|
/AAA/CCC |
|
选择AAA的所有CCC子元素 |
|
|
|
/AAA/DDD/BBB |
|
选择AAA的子元素DDD的所有子元素 |
|
|
如果路径以双斜线 // 开头, 则表示选择文档中所有满足双斜线//之后规则的元素(无论层级关系)
|
//BBB |
|
选择所有BBB元素 |
|
|
|
//DDD/BBB |
|
选择所有父元素是DDD的BBB元素 |
|
|
星号 * 表示选择所有由星号之前的路径所定位的元素
|
/AAA/CCC/DDD/* |
|
选择所有路径依附于/AAA/CCC/DDD的元素 |
|
|
|
/*/*/*/BBB |
|
选择所有的有3个祖先元素的BBB元素 |
|
|
方块号里的表达式可以进一步的指定元素, 其中数字表示元素在选择集里的位置, 而last()函数则表示选择集中的最后一个元素.
|
/AAA/BBB[1] |
|
选择AAA的第一个BBB子元素 |
|
|
|
/AAA/BBB[last()] |
|
选择AAA的最后一个BBB子元素 |
|
|
属性通过前缀 @ 来指定
|
//@id |
|
选择所有的id属性 |
|
|
|
//BBB[@id] |
|
选择有id属性的BBB元素 |
|
|
|
//BBB[@name] |
|
选择有name属性的BBB元素 |
|
|
|
//BBB[@*] |
|
选择有任意属性的BBB元素 |
|
|
属性的值可以被用来作为选择的准则, normalize-space函数删除了前部和尾部的空格, 并且把连续的空格串替换为一个单一的空格
|
//BBB[@id=‘b1‘] |
|
选择含有属性id且其值为‘b1‘的BBB元素 |
|
|
count()函数可以计数所选元素的个数
|
//*[count(BBB)=2] |
|
选择含有2个BBB子元素的元素 |
|
|
本文所涉及到的代码:https://git.oschina.net/infaraway/basisJava/tree/master/src/xml
标签:结构化 address 支持 ted 字符 后缀 student pat 使用
原文地址:http://www.cnblogs.com/infaraway/p/6525049.html