标签:utf-8 方法 分组 using nec 角度 settings 序号 最优
catalogue
0. 引言 1. Byte-sequence N-grams 2. Opcodes N-grams 3. API and Functions calls 4. Use of registers 5. Call Graphs 6. Malware as an Image 7. Detection of malware using dynamic behavior and Windows audit logs 8. 其他方法: Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification
0. 引言
During the last decade, researchers and anti-virus vendors have begun employing machine learning algorithms like
Association Rule
Support Vector
Machines
Random Forests
Naive Bayes
Neural Networks
to address the problem of malicious software detection and classification
Relevant Link:
http://www.covert.io/research-papers/deep-learning-security/Convolutional%20Neural%20Networks%20for%20Malware%20Classification.pdf
1. Byte-sequence N-grams
字节码N-Gram是一种根据单个byte进行N-gram编码的数据编码方式,对于英文单词来说只有0~255个编码空间

0x1: Feature Extraction
Features are created in 4 steps:
n-gram extraction
sequential pattern extraction
pattern statistics calculation
feature reduction.
1. N-Grams Extraction
这里简单对N-Gram做一下理解,该模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。对于一个句子T,我们怎么算它出现的概率呢?假设T是由词序列W1,W2,W3,…Wn组成的,那么P(T)=P(W1W2W3Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)。对于一个句子T,我们怎么算它出现的概率呢?假设T是由词序列W1,W2,W3,…Wn组成的,那么P(T)=P(W1W2W3Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)
一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram, P(T) = P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1)≈P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram,在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多,下面举一个栗子
假设语料库总词数为13,748

P(I want to eat Chinese food) =P(I)*P(want|I)*P(to|want)*P(eat|to)*P(Chinese|eat)*P(food|Chinese) =0.25*1087/3437*786/1215*860/3256*19/938*120/213 =0.000154171
N-Grams的本质就是在进行"几几一组"这件事,1-Grams就是1个单词为一个分组(0xXX),即1-Grams只能有256维,2-Grams就是2个ACII字符为一组,对应就是256 * 256维。通过对同一个文件采用不同的"组size"进行分组,并统计频次直方图,从binary文件中得到一个直方图分布的统计特征

我们对一个挖矿程序进行1、2、3、4的Gram提取,得到的结果如下
1-Gram

2-Gram(2步图)

3-Gram
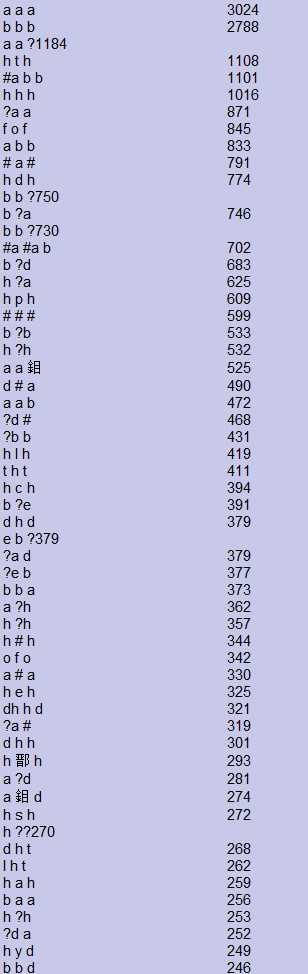
4-Gram
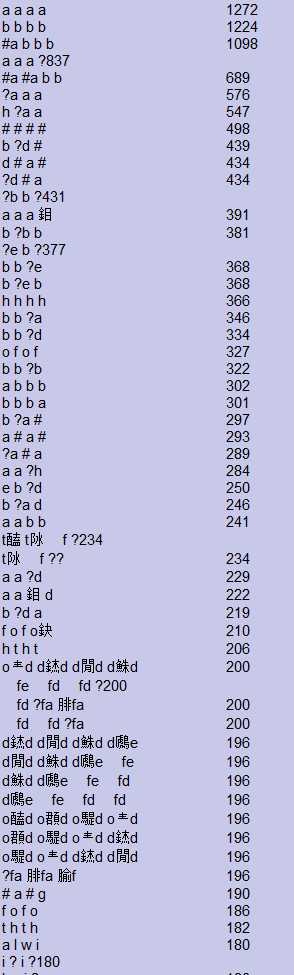
2. Sequential Pattern Extraction
There are a very large number of n-grams, but they lack order information necessary to capture characteristics of a program. This information can be provided by sequential patterns. A sequential pattern extraction technique is used to generate frequently occurred sequences of n-grams to represent the data and reduce response time. After being processed, malware is represented by a set of frequent patterns.
Let 1 2 { , ,..., } T t t t = m be a set of terms (n-grams) which are resulted from n-gram extraction. Given X be a set of terms (termset) in malware m, coverset(X) denotes the covering set of X for m, which includes all malware file mw F m Î ( ) , where X mw Í , i.e., coverset( ) X = Î Í { | ( ), } mw mw F m X mw , the absolute support of X is the number of occurrences of X in ( ) : | ( ) ( )| F sup X cov m a = erset X , the relative support of X is the fraction of the malware file that contains the pattern ( ) | ( )| / | ( ) | a sup X coverset X F m = . The relationships between frequent patterns and covering sets are shown in Figure 3. A termset X called a frequent pattern if _ a sup min sup ³ , a minimum support.
根据N-gram的词组进行sort排序后,给每个词组打上序号,根据1/2/3/4步图的词频分布情况进行归类,来分类恶意样本,即例如出现{t3,t4,t6}(第3、4、6位的词组)这组的词汇的样本可能就属于{mw2, mw3, mw4}这3个恶意样本

A sequential pattern is an ordered list of terms

A sequence 1 1,..., i s x x =< > is a sub-sequence of another sequence =< 12 ,..., yys j > denoted by 1 2 s s Í , if 1 ‘ ,. , .. y $ j j such that yi ...1 <<<£ jjjj 21 and 1 1 2 2 , ,..., j j i ji x y x y x y = = = . Given 1 2 s s Í , we usually say s1 is a sub-pattern of s2, and s2 is a super-pattern of s1. To simplify the explanation, we refer to sequential patterns as patterns
这句话是这么理解的,我们把样本按照一定的步数提出出N-gram的词组,然后根据词频进行排序,得到一个排序后的词组序列,从这个词组序列中截取一些"片段"(从本质上来说就是样本中的一小段汇编片段,常常是和核心代码区域相关的),这些"词频片段"就是从统计角度看到的样本恶意特征,可以被输入神经网络进行训练
3. Pattern Statistics Calculation(TF-IDF)
After n-gram patterns are generated, they will be organized in the following fashion
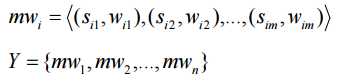
where ij s in pair  denotes a pattern sj(词组片段) in malware mwi, and wij is sj’s significance(词频权重) weight in mwi, thus the results are a set of malware vectors. In each malware
denotes a pattern sj(词组片段) in malware mwi, and wij is sj’s significance(词频权重) weight in mwi, thus the results are a set of malware vectors. In each malware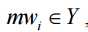 , the pattern significance can be calculated using term frequency-inverse document frequency (TF-IDF) weighting, where a term represents an n-gram sequential pattern, and a document represents a record of malware. A TF-IDF weight can be calculated as follows:
, the pattern significance can be calculated using term frequency-inverse document frequency (TF-IDF) weighting, where a term represents an n-gram sequential pattern, and a document represents a record of malware. A TF-IDF weight can be calculated as follows:

As a result, TF-IDF filters out common n-gram sequential patterns by giving low weights to patterns that appear frequently in the data set.TF-IDF会自动将样本中常见(出现频率很高)的词组序列过滤掉,从中提取中有价值的词组序列
4. Feature Reduction(特征降维)
There can be a large number of patterns. Although all of these patterns constitute the inputs of a classifier, they have different impacts to the classification performance. Some patterns may not increase the discriminative power of the classification among pattern classes. Vice versa some patterns may be highly correlated, and some may even be irrelevant for a specific classification. The sequential floating forward selection (SFFS) procedure [17] is thus applied to find a minimum feature set. It consists of applying after each forward step a number of backward steps as long as the resulting subsets are better than the previously evaluated ones at that level. The SFFS method can be described, as follows:

where i x is a candidate feature (pattern), Ym is the set of selected features (patterns) of size m, and J ×)( is the criterion function which is conditional mutual information in this research,SFFS的核心就是逐个尝试一组pattern的不同组合,不断筛选出最优值同时去除最差值
0x2: Malware Family Classification
A classification model accepts a feature vector and returns the family of the malware
1. C4.5 Decision Tree
The C4.5 decision tree is a powerful and popular tool for classification. The algorithm uses gain ratio as the impurity measure for split calculation which can be calculated as:
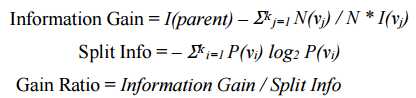
2. Artificial Neural Network
在神经网络的最后一层建立多分类神经元(例如10个),经过训练后,则该分类器能够区分10类不同种类的样本
3. Support Vector Machine
A support vector machine (SVM) is a supervised learning technique suitable for solving classification problems with high dimensional feature space
0x3: Experimental Results
The dataset is divided into two subsets 80% for training and 20% for testing
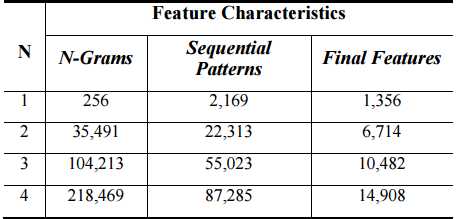
The final feature sets consist of: 1,356 patterns for 1-gram, 6,714 patterns for 2-gram, 10,482 patterns for 3-gram, and 14,908 patterns for 4-gram
Relevant Link:
http://www.kwicfinder.com/kfNgram/kfNgramHelp.html
http://blog.csdn.net/lengyuhong/article/details/6022053
http://paginaspersonales.deusto.es/ypenya/publi/penya_ICEIS09_N-grams-based%20File%20Signatures%20for%20Malware%20Detection.pdf
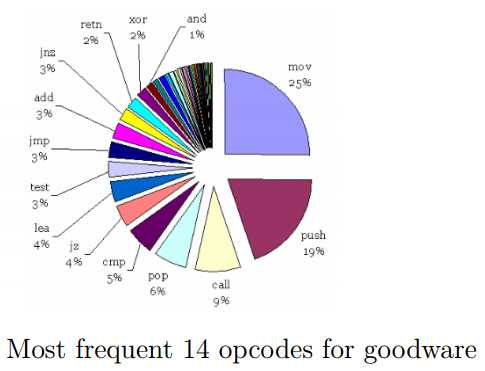
2. Opcodes N-grams
和byte N-gram相比,Opcode N-gram更能直观地描述出二进制样本的功能性特征,从软件层面来看,Opcode(汇编指令)及其组合是组成一个逻辑函数的最小单位
Relevant Link:
3. API and Functions calls
API and Functions calls属于程序的动态行为,需要借助sandbox技术动态获取程序的运行行为
API and function calls have been widely used to detect and classify malicious software. An experiment was conducted to determine the top maliciously used APIs. They retrieved the imports of all of the PE files and proceeded to count the number of times each sample uniquely imported an API. They found that there was a total of 120126 uniquely imported APIs.

但是需要注意的是,sandbox对抗领域已经在近几年成为malware detection && anti detection的一个激烈战场,恶意软件同样也会具备anti sandbox技术,动态检测当前运行环境
Relevant Link:
4. Use of registers
some people they proposed a method based on similarities of binaries behaviors.
They assumed that the behavior of each binary can be represented by the values of memory contents in its run-time. In other words, values stored in different registers while malicious software is running can be a distinguishing factor to set it apart from those of benign programs.
Then, the register values for each API call are extracted before and after API is invoked. After that, they traced the changes of registers values and created a vector for each of the values of EAX, EBX, EDX, EDI, ESI and EBP registers. Finally, by comparing old and unseen malware vectors they achieved an accuracy of 98% in unseen samples.
Relevant Link:
http://xueshu.baidu.com/s?wd=paperuri:(3747efc2c9e1f28d569e1478b57b8c5c)&filter=sc_long_sign&sc_ks_para=q%3DDyVSoR%3A+Dynamic+Malware+Detection+Based+on+Extracting+Patterns+from+Value+Sets+of+Registers&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=7223318801327141680
5. Call Graphs
Call Graphs和API and Functions calls的关系是前者是后者的包含集关系。类似IDA反汇编后得到的函数调用流图
A call graph is a directed graph that represents the relationships between subroutines in a computer program. In particular, each node represents a procedure/function and each edge (f,g) indicates that procedure f call procedure g. This kind of analysis have been used for malware classification with good results. In [15], they presented a framework which builds a function call graph from the information extracted from disassembled malware programs. For every node (i.e. function) in the graph, they extracted attributes including library APIs calls and how many I/O read operations have been been made by the function. Then, they computed the similarity between any two malware instances.
Relevant Link:
http://xueshu.baidu.com/s?wd=paperuri%3A%28c4af070f5473ed19800655223b4e48de%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.704.6425%26rep%3Drep1%26type%3Dpdf&ie=utf-8&sc_us=18240326204949692036
6. Malware as an Image
In this paper, we take a completely different and novel approach to characterize and analyze malware. At a broader level, a malware executable can be represented as a binary string of zeros and ones. This vector can be reshaped into a matrix and viewed as an image.
We observed significant visual similarities in image texture for malware belonging to the same family. This perhaps could be explained by the common practice of reusing the code to create new malware variants.(恶意软件在代码结构上都大同小异,殊途同归)
再次注意一点,利用这种binary-image图像分类的方法,我么不需要特征提取以及动态sandbox运行这些外置因素,而仅仅需要样本本身
详细的研究和实验细节,请参阅这篇文章
http://www.cnblogs.com/LittleHann/p/6505659.html
Relevant Link:
http://xueshu.baidu.com/s?wd=paperuri:(1896059a7c738909496b9cfb34aba342)&filter=sc_long_sign&sc_ks_para=q%3DMalware+images%3A+visualization+and+automatic+classification&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=609300761908966306 https://www.researchgate.net/publication/228811247_Malware_Images_Visualization_and_Automatic_Classification
7. Detection of malware using dynamic behavior and Windows audit logs
We found that Windows audit logs, while emitting manageable sized data streams on the endpoints, provide enough information to allow robust detection of malicious behavior. Audit logs provide an effective, low-cost alternative to deploying additional expensive agent-based breach detection systems in many government and industrial settings, and can be used to detect
One of the low hanging fruits not currently utilized in dynamical behavior detection are the Windows audit logs. Windows audit logs can be easily collected using existing Windows enterprise management tools, and are built
into the operating system, so there is a low performance and maintenance overhead in using them.
0x1: 定义样本特征维度
1. defining the type of system objects that will be monitored(需要i收集的事件类型)
1. files 2. registry keys 3. network events(not record)
网络行为太过密集,开启该事件log后会严重影响效率
2. what types of access to those objects should be recorded
1. reads(not record) 2. writes 3. deletes 4. executes 5. process spawns 6. permission changes
因为对于恶意程序来说,修改和写是较为通用和常见的特征,而读行为是黑和白样本都可能大量产生的行为
3. whose accesses should be monitored
1. users 2. system
0x2: 样本收集
样本收集,即收集到恶意样本和正常样本对应的行为在windows audit的结构化表芯,本质上来说,这种方法和传统的sandbox动态分析没有太大的区别,唯一的不同在于vm sandbox是在vm里安装驱动来实时捕获样本在关键节点上的行为,而windows audit log是通过收集系统日志信息来拿到行为,本质上都是行为
Relevant Link:
https://arxiv.org/abs/1506.04200 https://arxiv.org/pdf/1506.04200.pdf file:///C:/Users/Administrator/Desktop/1506.04200.pdf https://github.com/konstantinberlin/malware-windows-audit-log-detection
8. 其他方法: Novel Feature Extraction, Selection and Fusion for Effective Malware Family Classification
0x1: Entropy (ENT)
Entropy can be defined as a measure of the amount of the disorder and it is used to detect the presence of obfuscation in malware files and for this reason they computed the entropy of all the bytes in a malware file
0x2: Symbol frequencies (SYM)
The frequencies of the symbols -, +, *, ], [, ?, @ are extracted from the disassembled files because are typical of code designed to evade detection by resorting to indirect calls or dynamic library loading
0x3: Register (REG)
They computed the frequency of use of the registers in x86 architecture
Relevant Link:
http://www.covert.io/research-papers/deep-learning-security/Convolutional%20Neural%20Networks%20for%20Malware%20Classification.pdf
Copyright (c) 2017 LittleHann All rights reserved
neural network for Malware Classification(Reprinted)
标签:utf-8 方法 分组 using nec 角度 settings 序号 最优
原文地址:http://www.cnblogs.com/LittleHann/p/6476574.html