标签:关系型数据库 记录 存在 卡尔 行数据 ade justify 集合 size
查询的原理
在一个查询中常包含下述子句:
1、select,2、distinct,3、join,4、on,5、from,6、where,7、having,8、group by,9、order by,10、limit
在查询执行过程中,每个子句按照一定的顺序被执行,每个子句被执行时都会产生一张虚拟表,只有最后一步生成的虚拟表才会返回给用户。
我们用实际的例子来讲解下查询的执行过程,先准备以下两张表:
create table t_student(
id bigint(20) not null auto_increment comment ‘主键ID‘,
name varchar(10) not null default ‘‘ comment ‘姓名‘,
age tinyint(3) not null default 0 comment ‘年龄‘,
primary key (id)
)engine=innodb default charset=utf8 comment ‘学生信息表‘;
create table t_grade(
id bigint(20) not null auto_increment comment ‘主键ID‘,
student_id bigint(20) not null default 0 comment ‘学生ID‘,
level varchar(4) comment ‘水平:Null.未评级、A.优秀、B.中等、C.不及格‘,
primary key (id)
)engine=innodb default charset=utf8 comment ‘成绩表‘;
并插入一些基本数据:
insert into t_student(name,age) value(‘小A‘,16),(‘小B‘,17),(‘小C‘,18),(‘小D‘,17),(‘小E‘,18);
insert into t_grade(student_id,level) value(1,‘A‘),(2,‘B‘),(3,‘C‘),(4,‘B‘),(5,‘Null‘);
现有一个查询需求“查出是哪些水平拥有至少2个以上且年龄大于等于17岁的学生,并按人数由少到多排序”,那么根据这个需求我们可以写出如下代码:
select g.level, count(g.student_id) as total_student from t_student s left join t_grade g on s.id=g.student_id
where s.age>=17 group by g.level having count(g.student_id) >= 2 order by total_student asc;
下面我们就来说说上述SQL的执行顺序,
1)在一个查询语句中,from子句总是最先执行的,form操作会得到关联表的笛卡尔积,如下图
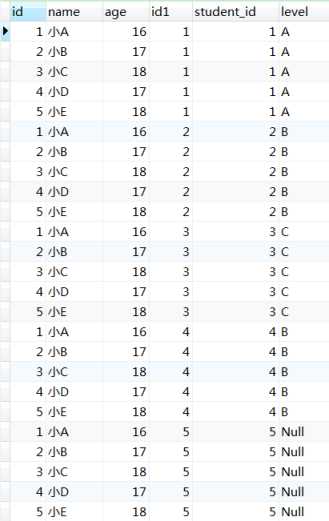
2)on子句会进行筛选操作,只有符合on后条件的行才会被筛选出来,我们刚刚所写查询的on后条件是s.id=g.student_id,那么不满足这个条件的行就会被去除,如下图有红色小三角标记的是会被保留的行
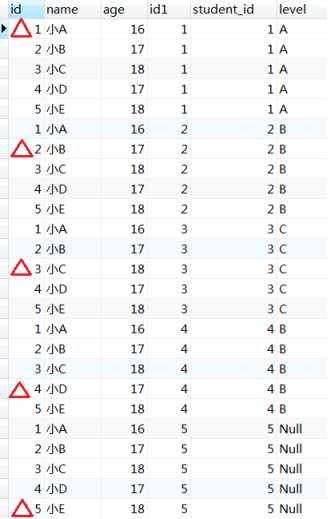
3)join子句如果是left join或right join,那么保留表(由于我们在SQL中使用的是left join,因此这里的保留表指的是t_student)中未匹配的行(因on子句被去掉的行)会作为外部行添加到虚拟表中,如下图
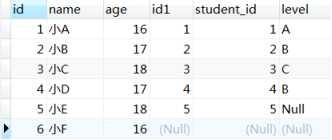
从上图对于join子句的表现不够直观,我们再向t_student表中插入一条数据,且这条数据是没有与t_grade表有关联关系的,insert into t_student(name,age) value(‘小F‘,16);
再看如下截图,由于刚插入的那条数据没有与t_grade表有关联关系,原本是要被on子句被去掉的,但是由于使用了left join,会保留左表的所有数据,同时右表没有与之关联的列值被赋值为Null,这就是添加外部行(left join的全写是left outer join,这里的outer就是指外部行)。
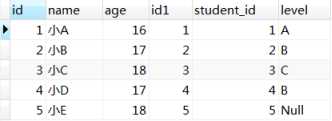
4)接着where子句会对得到的行再进行过滤,只有满足where后条件的行才会被筛选出来,见下图
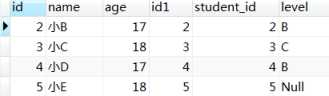
这里补充讲解一点,对于left join或right join,在on过滤完之后会添加保留表中被on过滤掉的行,而被where过滤的行则是永久性过滤。
5)group by对经过了where条件筛选后的数据进行分组;
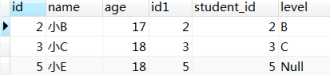
6)having需要和group by配合使用,因为having使用的前提是group by已经对数据完成了分组,而having就是来对分组后的数据再进行筛选,如下图

需要注意的是,若在left join或right join查询中,在select子句后使用count(1)或count(*),可能会把添加的外部行统计入内,从而导致查询结果与预期结果不符,对于这样的查询最好是使用count(具体列名)。
7)select将需要返回的列筛选出来,我们可以看到select的优先级并不高;

8)如果查询语句中带有去重子句distinct,则会执行去掉重复记录的操作;
去掉重复记录的原理是对进行distinct操作的列增加一个唯一索引。若SQL中使用了group by,则distinct是无效的,因为已经进行了分组,不会移除任何行。
9)接下来是order by,在我们得到了预期的数据后,可以对数据进行排序,以方便阅读,由于我们所执行的SQL查询出来只有一条数据,所以这里的排序效果并不明显,如下图

需要注意的是若不使用order by则查询出来的数据是无序的,并非是按照主键有序排列,这是因为关系型数据库是基于数学来实现的,关系对应数学中的集合,表中的数据对应集合中的元素,而集合本身是无序的,因此在不使用order by的情况下结果并不一定按照主键顺序进行排列,故我们在需要有序输出行记录时必须使用order by。
还有在对列进行排序时,若列没有索引,则排序会造成一定的性能开销。一般通过show status like ‘%sort%’ \G; 来观察相关变量,以此来判断是否可以通过添加索引来降低开销。
还需说明的是null值在升序中会首先被选出,因为在order by子句中null值被视为最小值。
10)最后是limit,拿到从指定位置开始的指定行数据,limit常和order by一起使用,其使用方式是limit n,m,表示拿到从第n行开始(不包含n行,实际从n+1行开始,如要取到的数据包含第n行,则应该是n-1)的共m行数据。
需要注意的是在大数据量下使用limit来分页效率是比较低的,因为需要在这么多数据量下去定位位置(定位n)。
这里详细对多表联查的过程做下说明,假设我们联查表A、B、C、D
先是表A、B做笛卡尔积,即两表记录数相乘,然后通过on来筛掉不符合的记录,如果是left join或right join这种方式的联查,则还需要保留外部行,怎么理解保留外部行,就是保留表中被过滤条件过滤掉的数据,这样就得到了表A、B的联查数据,接下来再将得到的数据和表C做笛卡尔积,并重复这一过程,直到最后一张表完成这一过程,最后就得到了A、B、C、D四表联查的数据;
额外知识点
在where子句后书写过滤条件时,有两种过滤情况是不允许发生的。
①数据没有分组前或者说在group by没有执行前,在where子句中不能使用分组函数,例如max()、min()、count()、sum()等,正因为这个限制的存在就能理解having子句存在的意义了,因为我们还存在对分组后的数据进行统计的需要;
错误的SQL:
select id from t_commodity c where count(commodity_type_id)>=5;
MySQL提示:

②为select子句后的列取别名,并在where子句里直接使用列别名,是不被允许的。因为where的执行顺序是要高于select的,因为在列还没有被选取的情况下,就开始使用列别名明显是不行的。
错误的SQL:
select `name` as n from t_commodity where n=‘精进‘;
MySQL提示:

标签:关系型数据库 记录 存在 卡尔 行数据 ade justify 集合 size
原文地址:http://www.cnblogs.com/seker/p/6536643.html